Today we’re launching the OpenAI Deployment Company to help businesses build and deploy AI.
It's majority-owned and controlled by OpenAI. It brings together 19 leading investment firms, consultancies, and system integrators to help organizations deploy frontier AI to production for business impact. https://t.co/GnyjGFaLLA
So Mythos was, indeed, not marketing hype.
Remember this is a general purpose model that just happens to be good at finding exploits because good models are good at lots of things. Expect similar from OpenAI & Google. And from open models in 8 months. https://t.co/KbhalQYX8R
The future of programming won’t be languages easiest for humans.
It’ll be languages easiest for agents.
We just shipped a Mac app where our engineers didn’t know a single line of Rust (or Tauri) beforehand.
Result: ~1/10th the size of a normal Mac app, highly performant
Agents are the new programmers. Languages should optimize for them.
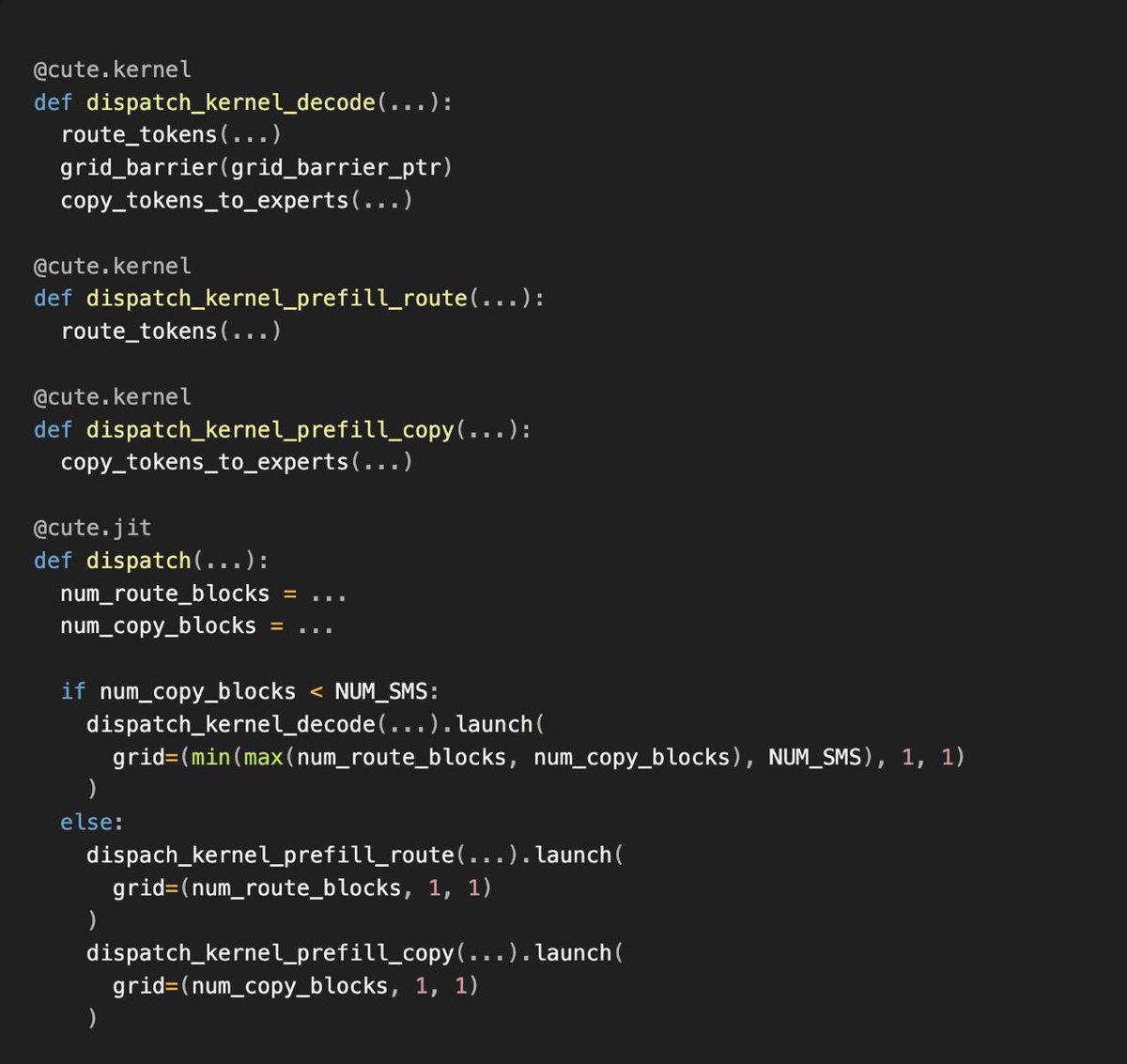
CuTeDSL offers unrestricted access to hardware primitives, providing us with the level of control we require to achieve peak performance in all edge cases.
We’ve developed our own inference engine Runtime-Optimized Serving Engine (ROSE) to serve models ranging from embeddings to trillion-parameter LLMs.
With CuTeDSL integrated into our inference engine, Perplexity can build the specialized GPU kernels faster to bring models up to peak performance on NVIDIA Hopper and Blackwell GPUs.
With CUDA, opportunities for compile-time specialization were limited, as each additional parameter added an unreasonable cost to compilation times or complexity to the build system.
Got to talk at @aiDotEngineer conf last week about the need for collaborative AI engineering.
All our current coding agents are single player. We're trying to scale up individual productivity, but creating tons of alignment problems in the process.
We have no good tools for...
1)A16 node delay until H2 2027 can confirm before when i said high defect and chip hot spot reliability problem only Nvidia AI GPU use it .
2)A13 node (no BSPDN version + 2 gen GAAFET)
3)A12 node (BSPDN version + 2 gen GAAFET)
4)N2U ??? 18A-U ???
5)A10 node use High Na EUV
Kimi K2.6 raises the bar for open-source models.
Moonshot released it yesterday, and for the first time, an open-weight model holds its ground against Claude Opus 4.6 on the benchmarks that matter for agentic work.
It also costs a fraction of the price.
𝗧𝗵𝗲 𝗽𝗿𝗶𝗰𝗶𝗻𝗴
Kimi K2.6 runs at $0.95 per million input tokens and $4 per million output tokens.
Claude Opus 4.6 runs at $5 and $25.
With cache hits, the gap widens. K2.6 drops to $0.16 per million on cached inputs. Opus 4.6 drops to $0.50.
That's roughly 5-6x cheaper across the board, before and after caching.
𝗧𝗵𝗲 𝗯𝗲𝗻𝗰𝗵𝗺𝗮𝗿𝗸𝘀
K2.6 leads Opus 4.6 on four of the six head-to-head comparisons Moonshot published:
- SWE-bench Pro: 58.6 vs 53.4 (agentic coding)
- HLE with tools: 54.0 vs 53.0 (agentic reasoning)
- DeepSearchQA: 92.5 vs 91.3 (deep research)
- LiveCodeBench: 89.6 vs 88.8
Opus 4.6 still wins on SWE-bench Multilingual and BrowseComp, but the gap is under a point in both.
𝗧𝗵𝗲 𝗽𝗮𝗿𝘁 𝘁𝗵𝗮𝘁 𝗮𝗰𝘁𝘂𝗮𝗹𝗹𝘆 𝗺𝗮𝘁𝘁𝗲𝗿𝘀
Benchmarks are the easy story. The harder and more interesting story is long-horizon execution.
K2.6 ran a single autonomous task for over 12 hours, making 4,000+ tool calls, to port and optimize inference for a small LLM in Zig, a language most models barely touch.
It ended up running around 20% faster than LM Studio on the same hardware.
Separately, it refactored an 8-year-old financial matching engine across 13 hours, delivering a 133% peak throughput gain.
This is the capability gap that usually separates frontier closed models from open ones. K2.6 closes a meaningful chunk of it.
You get weights you can actually deploy, a Modified MIT license, 5-6x lower inference cost, and performance that no longer forces you to compromise on agentic workloads.
The moat around Frontier Labs is shrinking fast.
Read more: https://t.co/ye6bkXBYTD
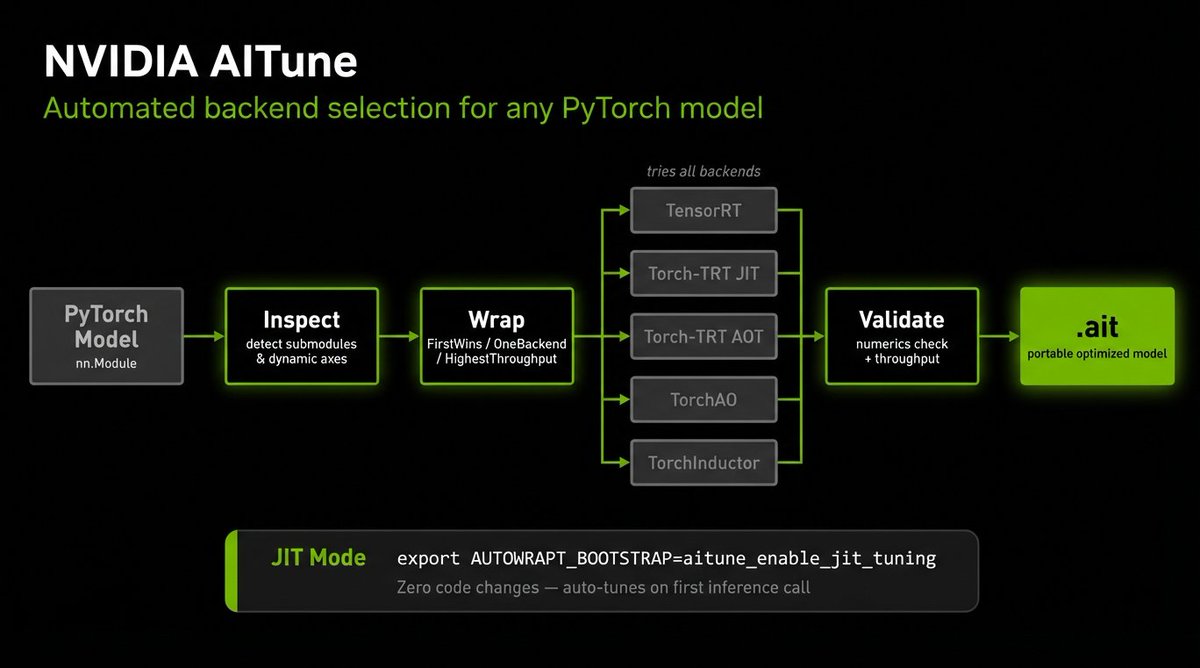
⚡🔧 PyTorch inference optimization just got a lot simpler
Introducing AITune — NVIDIA's new library that automatically finds the fastest inference backend for any PyTorch model. It covers TensorRT, Torch Inductor, TorchAO and more, benchmarks all of them on your model and hardware, and picks the winner. No guessing, no manual tuning.
The production path (Ahead-of-time): AITune profiles all backends, validates correctness automatically, and serializes the best one as an .ait artifact — compile once, zero warmup on every redeploy. Something torch.compile alone doesn't give you. Pipelines are also supported — each submodule gets tuned independently.
The fast path (Just-in-time): set env variable, run your script unchanged. No code changes, no setup — AITune auto-discovers modules and optimizes them. Good for quick exploration before committing to AOT.
Not competing with vLLM or TRT-LLM — fills the gap for everything else: diffusion, CV, speech, embeddings. Works on any PyTorch model.
Check it out: https://t.co/WHrGcWEp1e
Open-source software never stops. It only accelerates.
Dynamo, @sgl_project, TensorRT LLM, and @vllm_project are constantly optimized by a vast ecosystem of developers building on top of the NVIDIA platform.
The result: your token output keeps improving and token cost keeps decreasing on the same hardware resources while your developer velocity stays at its peak.
Build on the foundation continuously optimized by the world’s best developers. ⚡
🔗 https://t.co/eH2xhsw8mG
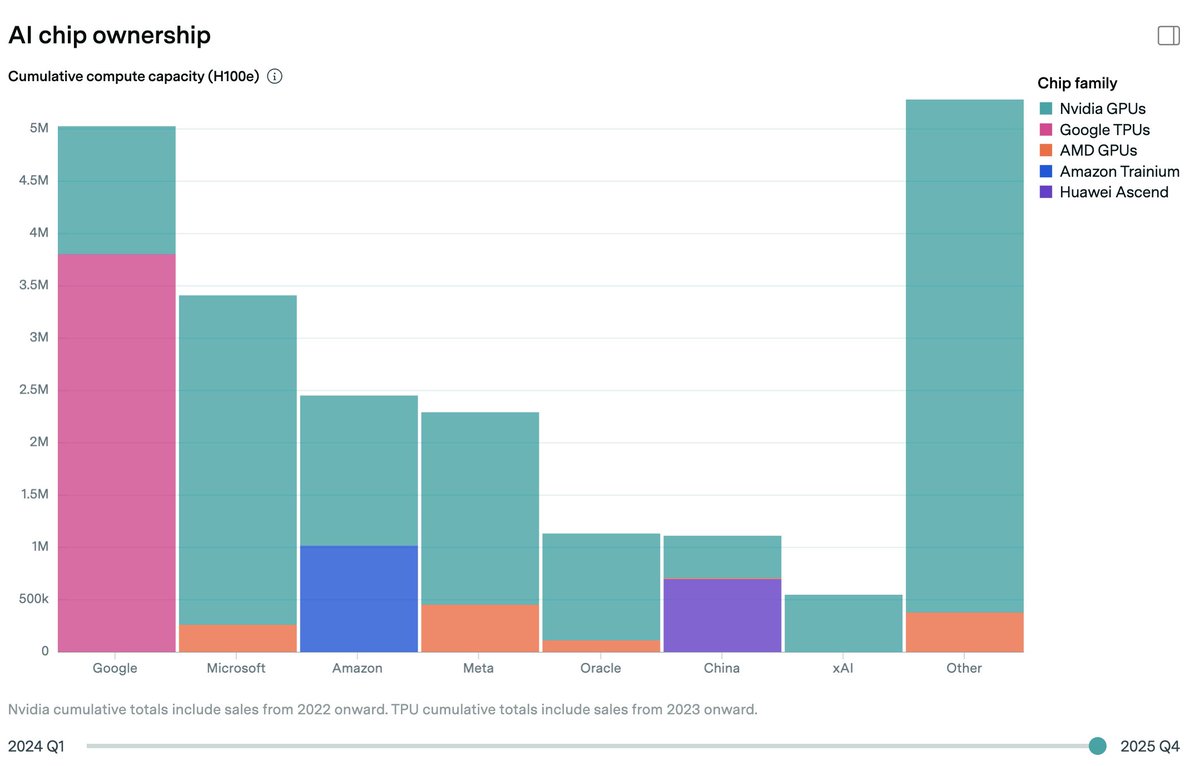
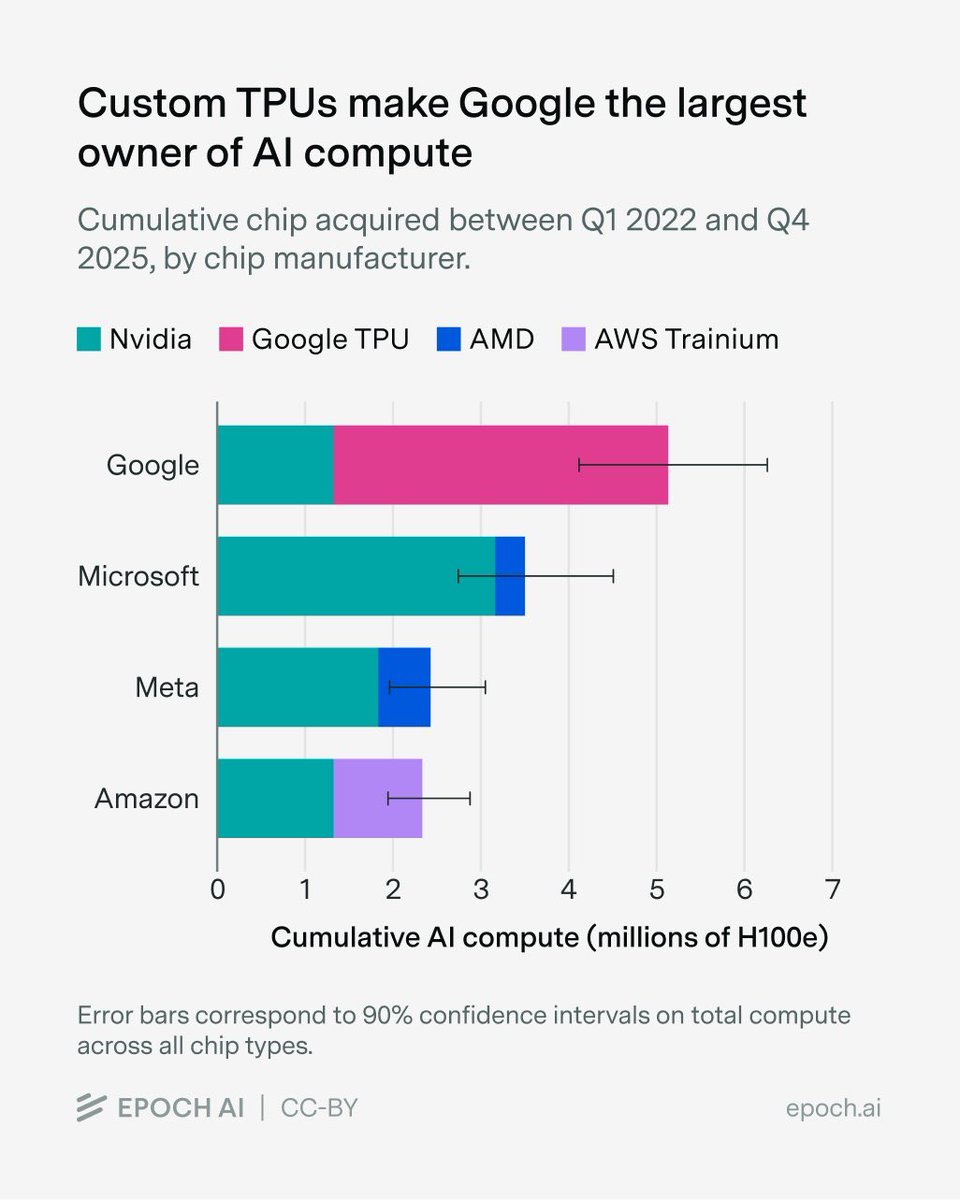
Compute may be the most important input to AI. So who owns the world’s AI compute?
Introducing our new AI Chip Owners explorer, showing our analysis of how leading AI chips are distributed among hyperscalers and other major players, broken down by chip type over time.
Google had the foresight to develop TPUs back in 2012. Today, they have by far the most compute. In the long term, Google is in one of the best starting positions: a solid revenue and product base, compute, and above all: distribution.