Want robot imitation learning to generalize to new tasks? Blindfold your human demonstrator!
Best robotics paper at EXAIT Workshop #ICML2025
https://t.co/6XT0hdl00d
Wait, why does this make sense?
Read below!
How to plan subgoals for complex tasks with multiple objects?
Key ideas: factor the subgoals + diffusion model to generate subgoals suggretions
+ a few other neat tricks -> learning complex tasks from visual inputs. Check out the thread/paper!
Can we use tactile sensors for soft object imaging?🤔
YES!
Toward Artificial Palpation: Representation Learning of Touch on Soft Bodies.
@shafer_eli , @talt80, @Efrat_Shimron, @AvivTamar1.
Paper, videos, data: https://t.co/RwkUSDE46b
Check us out at @NeurIPSConf#neurips2025!
Robots wil eventually be able to explore/adapt, but how can we trust strategies that are hard to interpret?
We take the first step in *interpretable* exploration, and find a tree-like exploration rule that is both efficient (low regret) and interpretable (shallow tree)
#ICML25
Want to learn / teach RL?
Check out new book draft:
Reinforcement Learning - Foundations
https://t.co/142MbSiTIQ
W/ @shiemannor and @YishayMansour
This is a rigorous first course in RL, based on our teaching at TAU CS and Technion ECE.
This project completely reshaped my view on tree search + neural networks
https://t.co/UFLhFJDqry
Using a NN for value/policy in MCTS is standard, but if the network errs, search performance goes down. We asked: if we have uncertainty estimates, can we exploit them?
When does meta training truly benefits RL efficiency?
In our #ICML2024 paper, @AvivTamar1 and me analyse the conditions under which fast regret rates can be achieved at test time https://t.co/3AhsEWX7ul
1/5
Generalization in RL is hard. Compositional generalization is even harder… We made some progress in our #ICLR2024 spotlight w/ @DanHrmti and @TalDaniel8
RL trains a robotic manipulation policy that generalizes to different numbers of objects
Code+paper: https://t.co/mPIHSKQK0W
Our work "MAMBA: An Effective World Model Approach for Meta Reinforcement Learning" got accepted to @iclr_conf!
It was super fun working on this one with @TomJurgenson, @orrkrup, Gilad Adler, and @AvivTamar1
Paper: https://t.co/1BnykXA4WI
Code: https://t.co/nVsD16YupU
🧵
[1/9]
DOTE won BEST PAPER at #nsdi23 !!!
DOTE trains a deep neural network that directly outputs traffic engineering configurations. This works great for traffic that is difficult to predict accurately, e.g., MSFT's costumer facing WAN
Yarin Perry will present Wed 14:40EDT
👇
Working on robotic bin picking?
#ICRA2023 work led by Osaro’s research team shows how to improve throughput at deployment time
Idea: optimize sequence of tools changes based on pretrained grasp success maps = better throughput for free!
https://t.co/yeDwzkuPYU
Poster Wed 9am
Meta-RL is all about inferring the task from a history of observations. But how to best learn a history embedding?
In ContraBAR ( #ICML2023 w\
@era_choshen ) we investigate a contrastive learning approach.
Paper: https://t.co/k0u8OAgLMR
Code: https://t.co/hy3AwBHFFA
👇
Check out these beautiful videos 🤩
Deep *dynamic* latent particles is a new object-based video prediction method, led by @TalDaniel8
Key idea:
Latent variables = particles, making it easier to learn latent dynamics
👇
Teacher-student algos are great for learning w/ partial observability: teacher trained with full info -> student imitates it.
But what if full-info policy is very different from partial-info?
TGRL cleverly balances imitation with RL, leading to a very practical method
#ICML2023
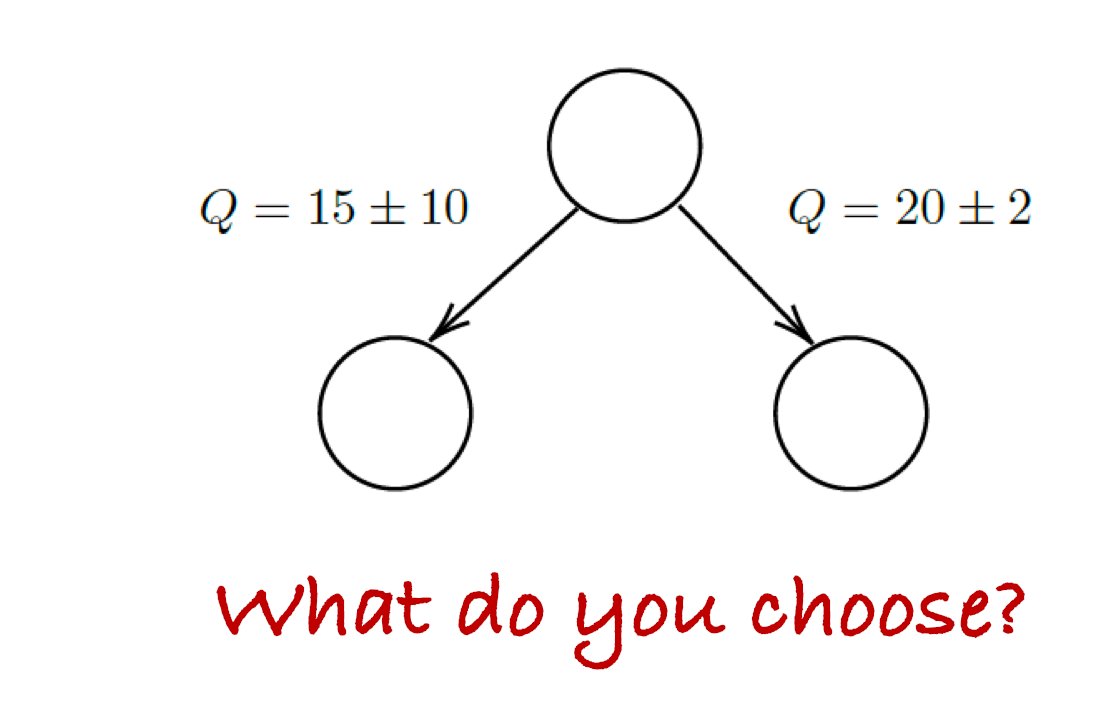
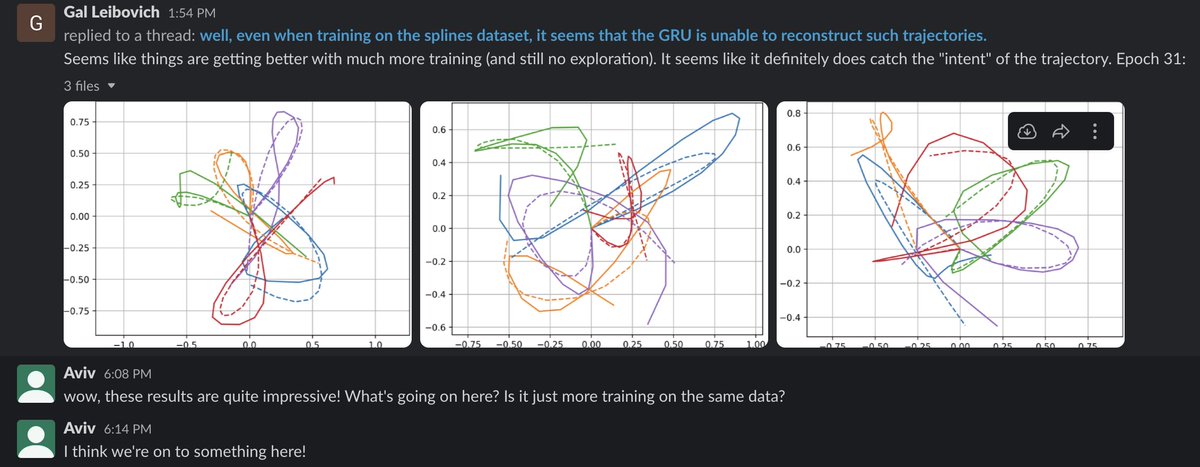
On Mar 21 we forgot to shut down a machine running a simple sanity check experiment. A couple days later, we were surprised to see beautiful results, which we couldn’t quite explain!
👇
What do you do when your robot world model just doesn't cut it? Fine-tune it, of course!
New paper in #CoRL2023 next week, "Fine-Tuning Generative Models as an Inference Method for Robotic Tasks"
1/ >>>
https://t.co/ifXaBsjXtq
We recently had a bit of a breakthrough in generalization in RL, led by @EvZisselman
TL;DR: learning MaxEnt exploration generalizes better than maximizing reward. We use this to set a new SOTA for ProcGen + significantly improve on hard games like Heist!
#NeurIPS2023
Details👇