What if computation is not just automation, but interpretation? We draw on the West African Ifá knowledge system to rethink AI, governance & intelligence through ethics, context, dialogue & social accountability. A new framework for AI governance & safety https://t.co/QMHLLHYfdw
Our new book!
My new book is out!
What if computation is not just automation, but interpretation? Drawing on the West African Ifá knowledge system to rethink AI, governance & intelligence through ethics, context, dialogue & social accountability. A new framework for AI safety
Major preprint just out!
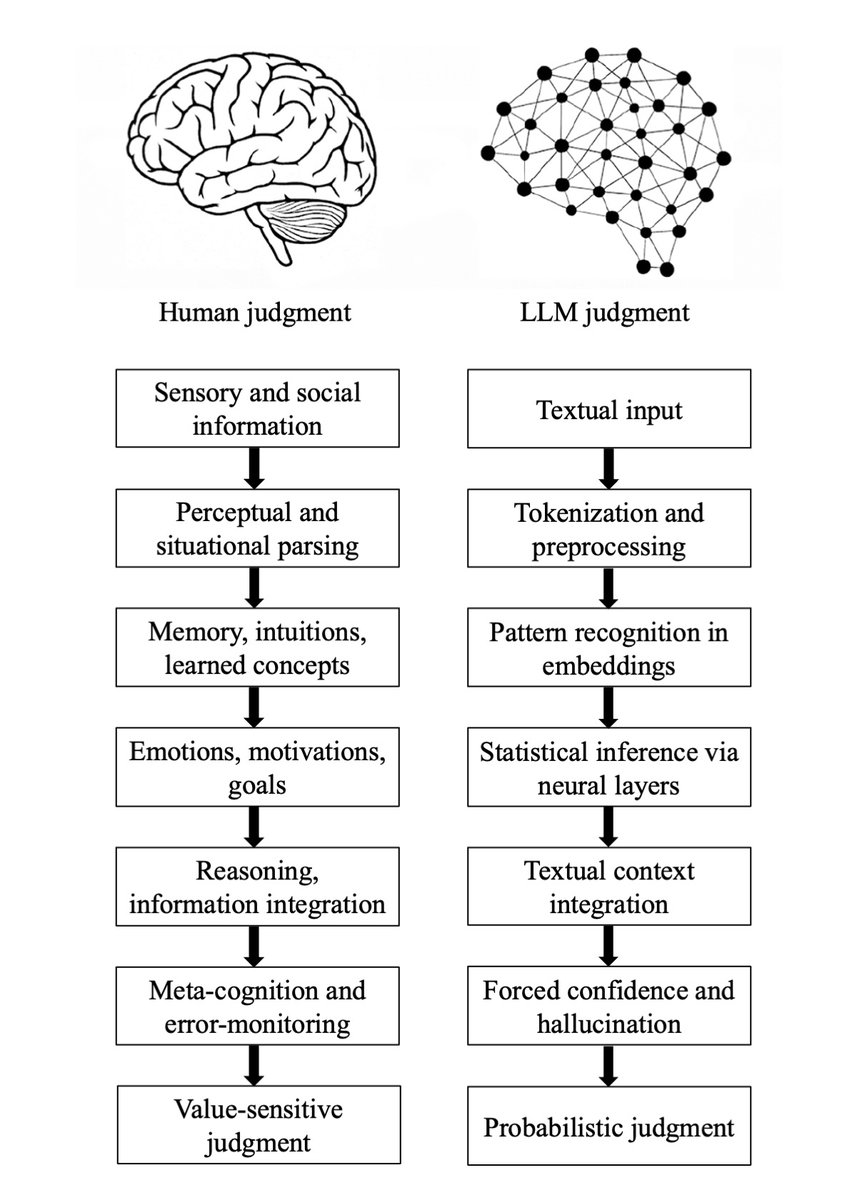
We compare how humans and LLMs form judgments across seven epistemological stages.
We highlight seven fault lines, points at which humans and LLMs fundamentally diverge:
The Grounding fault: Humans anchor judgment in perceptual, embodied, and social experience, whereas LLMs begin from text alone, reconstructing meaning indirectly from symbols.
The Parsing fault: Humans parse situations through integrated perceptual and conceptual processes; LLMs perform mechanical tokenization that yields a structurally convenient but semantically thin representation.
The Experience fault: Humans rely on episodic memory, intuitive physics and psychology, and learned concepts; LLMs rely solely on statistical associations encoded in embeddings.
The Motivation fault: Human judgment is guided by emotions, goals, values, and evolutionarily shaped motivations; LLMs have no intrinsic preferences, aims, or affective significance.
The Causality fault: Humans reason using causal models, counterfactuals, and principled evaluation; LLMs integrate textual context without constructing causal explanations, depending instead on surface correlations.
The Metacognitive fault: Humans monitor uncertainty, detect errors, and can suspend judgment; LLMs lack metacognition and must always produce an output, making hallucinations structurally unavoidable.
The Value fault: Human judgments reflect identity, morality, and real-world stakes; LLM "judgments" are probabilistic next-token predictions without intrinsic valuation or accountability.
Despite these fault lines, humans systematically over-believe LLM outputs, because fluent and confident language produce a credibility bias.
We argue that this creates a structural condition, Epistemia:
linguistic plausibility substitutes for epistemic evaluation, producing the feeling of knowing without actually knowing.
To address Epistemia, we propose three complementary strategies: epistemic evaluation, epistemic governance, and epistemic literacy.
Full paper in the first reply.
Joint with @Walter4C & @matjazperc
#AI is presented as a disruptive #innovation.
But as @UyiosaOM argues, #Indigenous knowledge systems, such as Ifá, provide an alternative decolonial lens through which to understand AI computation and its impact on society @LSEImpactBlog
https://t.co/rOabUupMWb
https://t.co/GtFPLe1Nfg Indigenous knowledge systems, such as Ifá, provide an alternative decolonial lens through which to understand AI computation and its impact on society
“Everybody in math and physics uses it.”
Nearly 35 years ago, Paul Ginsparg created arXiv, a digital repository for sharing research. It changed science for good.
Three decades in, Ginsparg reflects on its legacy—and its future.
https://t.co/tnW3ldTbcw
Contribution of vaccination to improved survival and health: modelling 50 years of the Expanded Programme on Immunization - The Lancet https://t.co/l41nAXEV3I
“Here, we advance work on the Moral Turing Test and find that Americans rate ethical advice from GPT-4o as slightly more moral, trustworthy, thoughtful, and correct than that of the popular New York Times advice column, The Ethicist.”https://t.co/tpfuFJRNrB
"If there's a book that you want to read, but it hasn't been written yet, then you must write it. The same is true of any endeavor: if the solution you seek doesn't exist, create it." - Toni Morrison