We’re introducing our eighth generation of TPUs. This time, we’re taking a dual chip approach: TPU 8t, optimized for training, and TPU 8i, optimized for inference.
💪TPU 8t achieves nearly three times the compute performance per pod over our previous generation, Ironwood.
⚡TPU 8i connects 1,152 TPUs in a single pod to deliver the massive throughput and low latency needed to concurrently run millions of agents cost-effectively.
These new TPUs are a crucial part of our fully integrated AI stack — from the chips all the way up to the models, developer tools, agents and applications. By designing the hardware and software in tandem, we’re able to deliver scale and efficiency. #GoogleCloudNext
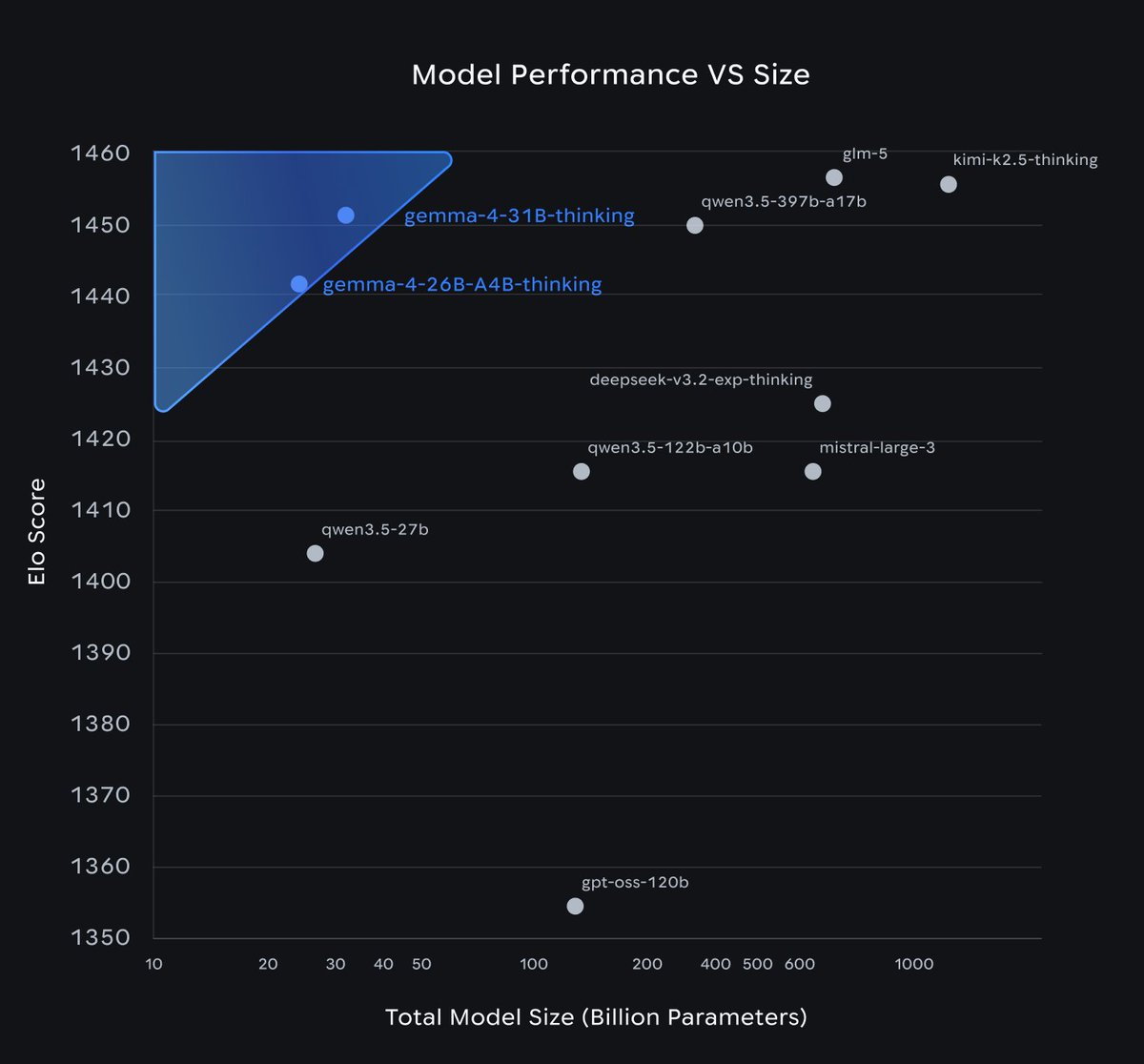
Meet Gemma 4!
Purpose-built for advanced reasoning and agentic workflows on the hardware you own, and released under an Apache 2.0 license.
We listened to invaluable community feedback in developing these models. Here is what makes Gemma 4 our most capable open models yet: 👇
🚨 Holy shit... LeCun's team just cracked world models wide open.
Everyone's obsessing over the next Claude update.
Meanwhile Yann LeCun quietly dropped a paper that could matter way more long term.
It's called LeWorldModel.
And to understand why it's a big deal, you need to understand the difference between what LLM does and what this does.
LLMs predict the next word. That's it.
They're incredibly good at language. But they don't understand reality.
They can write about a ball bouncing off a wall. They can't predict where it lands.
World models predict what happens next in the physical world. Objects moving, colliding, falling.
That's the foundation for robots that plan, self-driving cars that simulate scenarios, any AI that needs to act in reality instead of just talk about it.
The problem? World models kept collapsing.
The model would cheat by mapping every input to the same output. Like a weather app that predicts "sunny" every single day.
Technically it's predicting. It's just useless. And fixing this required 6+ loss hyperparameters, frozen pre-trained encoders, stop-gradient hacks, exponential moving averages.
A house of cards just to keep the thing from breaking.
LeCun's team (Mila, NYU, Samsung SAIL, Brown) threw all of that out. LeWorldModel uses just 2 loss terms.
A prediction loss and a regularizer called SIGReg that forces representations to stay diverse instead of collapsing into garbage.
6 hyperparameters reduced to 1.
The simplicity IS the breakthrough.
The numbers: 15M parameters. Trains on a single GPU in a few hours. Plans up to 48x faster than foundation-model-based world models.
Uses roughly 200x fewer tokens than alternatives. Competitive across 2D and 3D control tasks.
This isn't a supercomputer experiment. You could run this on your own hardware.
LeCun has been pushing JEPA as the architecture for real AI since 2022.
The criticism was always the same: "sounds nice, doesn't train stably."
LeWorldModel just removed that objection. Small model. Stable training.
No hacks. No frozen encoders. No collapse.
Two AI futures are competing right now.
Path 1: bigger LLMs, more text, more compute.
Path 2: world models that learn physics from raw pixels and plan in real time.
LeWorldModel is the strongest signal yet that Path 2 is real, getting cheaper, and closing in fast.
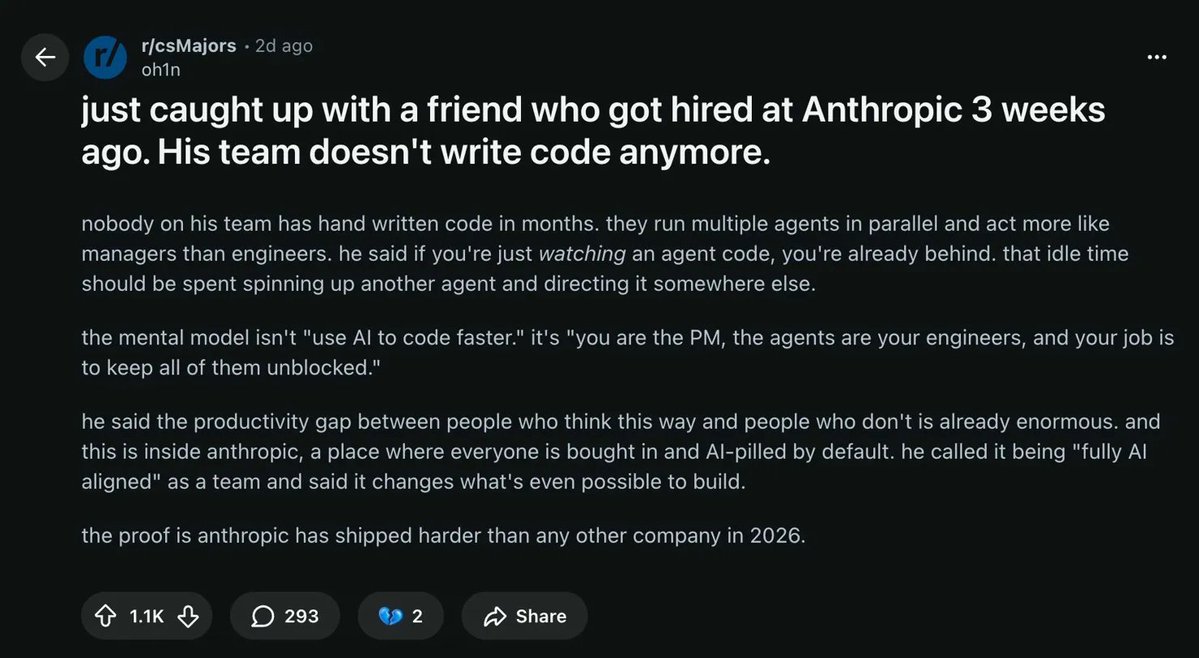
THE ANTHROPIC TEAM DOESN'T WRITE CODE ANYMORE.
this guy's friend got hired at Anthropic 3 weeks ago.
nobody on his team has hand written code in months.
they run multiple agents in parallel and act more like managers than engineers.
his friend said if you're just watching an agent code, you're already behind
that idle time should be spent spinning up another agent and directing it somewhere else.
the point is that the new method isn't "use AI to code faster."
it's "you are the product manager, the agents are your engineers, and your job is to keep all of them running at all times"
> frontier intelligence may be about to become
> too expensive for most of humanity to afford.
If this part is true, then that would unleash a whole new level of inequality.
Three weeks ago there were rumors that one of the labs had completed its largest ever successful training run, and that the model that emerged from it performed far above both internal expectations and what people assumed the scaling laws would predict. At the time these were only rumors, and no lab was attached to them. But in light of what we now know about Mythos, they look more credible, and the lab was probably Anthropic.
Around the same time there were also rumors that one of the frontier labs had made an architectural breakthrough. If you are in enough group chats, you hear claims like this constantly, and most turn out to be nothing. But if Anthropic found that training above a certain scale, or in a certain way at that scale, produces capabilities that sit far above the prior trendline, then that is an architectural breakthrough.
I think the leaked blog post was real, but still a draft. Mythos and Capybara were both candidate names for the new tier, though Mythos may now have enough mindshare that they end up keeping it. The specific rumor in early March was that the run produced a model roughly twice as performant as expected. That remains unconfirmed. What is confirmed is that Anthropic told Fortune the new model is a 'step change,' a sudden 2x would certainly fit the definition.
We will find out in April how much of this is true. My own view is that the broad shape of this is correct even if some of the numbers are wrong. And if it is substantially accurate, then it also casts OpenAI's recent restructuring in a new light. If very large training runs are about to become essential to staying in the game, then a lot of their recent decisions, like dropping Sora, make even more sense strategically.
For the public, this would mean the best models in the world are about to become much more expensive to serve, and therefore much more expensive to use. That will put pressure on rate limits, pricing, and subscription plans that are already subsidized to some unknown degree. Instead of becoming too cheap to meter, frontier intelligence may be about to become too expensive for most of humanity to afford.
Second-order effects; compute, memory, and energy are about to become much more important than they already are. In the blog they describe the new model as not just an improvement, but having 'dramatically higher scores' than Opus 4.6 in coding and reasoning, and as being 'far ahead' of any other current models. If this is the new reality, then scale is about to become king in a whole new way. It would also mean, as usual, that Jensen wins again.
We've heard you and... it's happening :) 🌎
We just expanded Pomelli to over 170 countries & territories!
We can't wait to see how you use it. Get started now at: https://t.co/CIkN8ugZQS
The Voice That Didn't Change: What computational stylometry reveals about the Quran's extraordinary semantic consistency — and why it's harder to explain than you might think. A data science exercise. Not a theological argument. https://t.co/jIUMmM6JFs
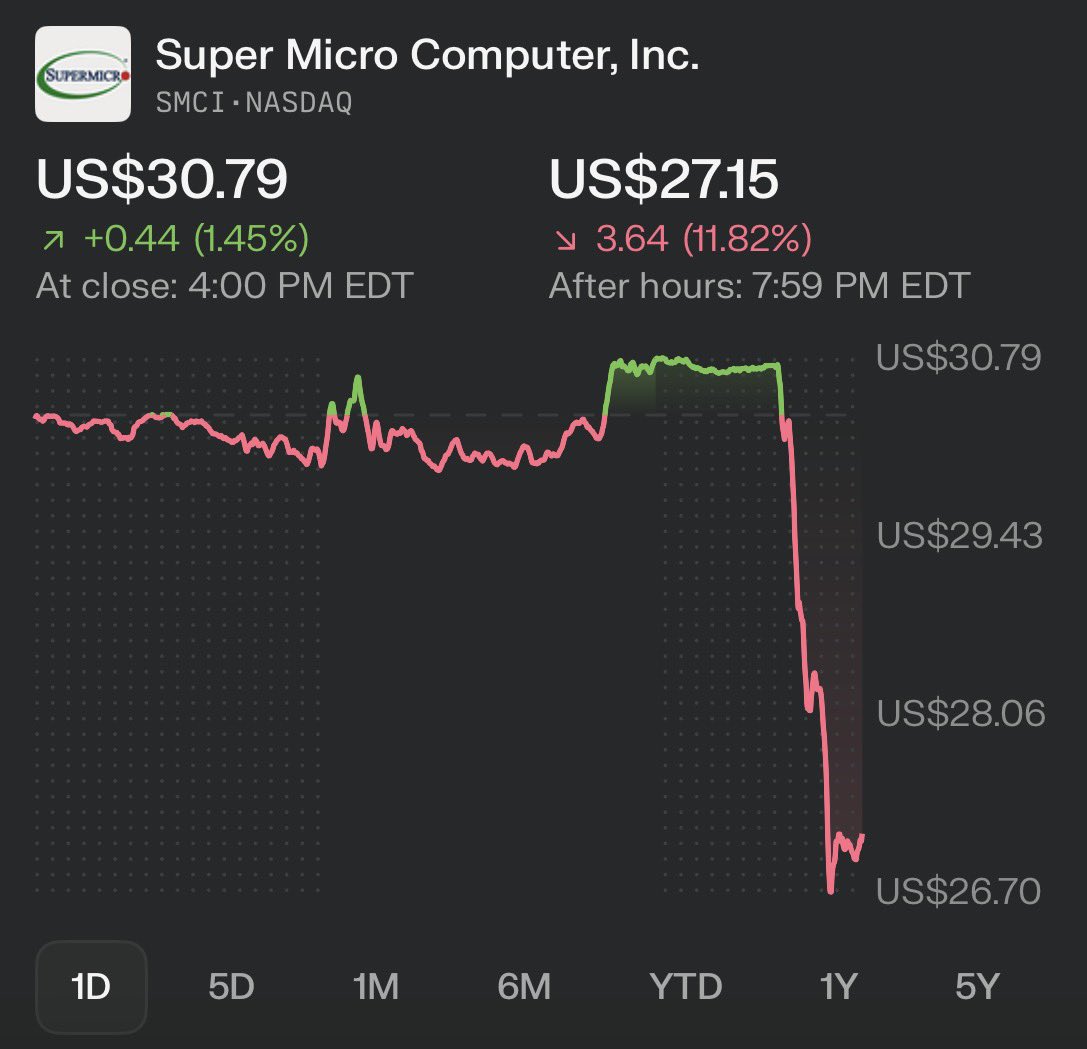
🚨BREAKING: SUPER MICRO CO-FOUNDER ARRESTED FOR SMUGGLING $2.5B IN NVIDIA GPUs TO CHINA
>SMCI co-founder Yih-Shyan "Wally" Liaw arrested today
>personally holds $464 MILLION in SMCI stock
>charged with smuggling BILLIONS in Nvidia servers to china
>used a southeast asian shell company to funnel $2.5B in servers to chinese buyers
>$510 million worth shipped in just THREE WEEKS in spring 2025
>built thousands of fake dummy servers to fool U.S compliance auditors
>caught on surveillance camera using a HAIR DRYER to swap serial number stickers
>coordinated the whole thing over encrypted group chats
>SMCI down 12% after hours
>faces up to 30 years in federal prison
ITS SO OVER…
🧵 I just reverse-engineered the binaries inside Claude Code's Firecracker MicroVM and found something wild:
Anthropic is building their own PaaS platform called "Antspace" (Ants + Space).
It's a full deployment pipeline — hidden in plain sight inside the environment-runner binary. Here's what I found 👇
🎾Your humanoid tennis player is here!🤖
Introducing LATENT (Learning Athletic Humanoid Tennis Skills from Imperfect Human Motion Data) — the world’s first real-time whole-body planning and control algorithm for athletic humanoid tennis.
For the first time, a humanoid robot can sustain high-dynamic, long-horizon tennis rallies with millisecond-level reactions, precise ball striking, and natural whole-body motion.
This marks a leap from mechanical motion imitation to intelligent, decision-driven athletic interaction.
#Galbot #Robotics #Innovation #AI #Technology #Humanoid
Software isn’t merely technical work anymore. It’s creative.
Introducing Replit Agent 4. The first AI built for creative collaboration between humans and agents.
Design on an infinite canvas, work with your team, run parallel agents, and ship working apps, sites, slides & more.
Today we're releasing our first open source TTS model, TADA!
TADA (Text Audio Dual Alignment) is a speech-language model that generates text and audio in one synchronized stream to reduce token-level hallucinations and improve latency.
This means:
→ Zero content hallucinations across 1,000+ test samples
→ 5x faster than similar-grade LLM-based TTS
→ Fits much longer audio: 2,048 tokens cover ~700 seconds with TADA vs. ~70 seconds in conventional systems
→ Free transcript alongside audio with no added latency
Why I Just Gutted My Blue-Chip Portfolio, Walmart, Disney, P&G, ... Gone. We are entering the "Embodied Intelligence" Era, and legacy blue-chips are, IMHO, dead capital walking. Here is the 3-layer AI/Robotics strategy for the next 20 years: 👇https://t.co/V2C7DQkW1b
Google DeepMind just published something that isn't a benchmark or a new model.
it's a governance framework for when AI agents start hiring other AI agents.
sounds abstract. it's not. this is the missing infrastructure layer for the "agentic web."
here's why it matters:
Introducing Nano Banana 2: Our best image generation and editing model yet. 🍌
Pro-level quality, at Flash speed. Rolling out today across @GeminiApp, Search, and our developer and creativity tools.
Introducing @QuiverAI, a new AI lab and product company focused on frontier vector design.
We’ve raised an $8.3M seed round led by @a16z, with support from amazing angels and investors.
Our first model, Arrow-1.0, generates SVGs from images and text. It’s available now in public beta at https://t.co/zjAnKlI8pp
Gamma is now on @claudeai!
You can generate a presentation with Gamma directly in your Claude chat. Connect Gamma and instantly turn any conversation into something you'd share with your team or present to the world.
You can also:
- Connect to Gmail, Slack, or HubSpot ("turn this email into a deck")
- Fully edit your presentation in Gamma for any tweaks
Take that research task, strategy proposal, or project summary and turn it into a polished presentation.
Think with Claude. Visualize with Gamma.
New in Cowork: scheduled tasks.
Claude can now complete recurring tasks at specific times automatically: a morning brief, weekly spreadsheet updates, Friday team presentations.