CPU usage heatmap comparing "Heterogeneous short running thread scheduling policy" on a 7800X3D in Starfield (City CPU Intensive Bench).
"All Processors" vs "Prefer Performant Processors"
The difference is pretty clear. "All Cores" has a more even multithreading, better L3 Hit Rate, less DRAM Hit Rate.
Ray Reconstruction uses AI to improve the quality of ray-traced lighting, reflections, and shadows.
Can you see the difference?
Here's a hint:
Look at the scene after the lighter turns off.
On the bottom, shadows and lighting updates appear slower and less precise.
On the top, the scene settles into darkness more naturally.
New @NVIDIAAI DGX station is an absolute monster for desktop AI workstation.💰💰💰
748 GB Total memory:
- 252 GB HBM3e | 7.1 TB/s (GPU)
- 496 GB LPDDR5X | 396 GB/s (CPU)
But what's more interesting is It features open expansion slots (1x PCIe Gen 5 x16, 2x x16@x8). Drop in an RTX PRO 6000 Blackwell or a 4000 Blackwell SFF to scale up to 844 GB of total system memory.
Image taken from GigaByte
AI Workstation - NVIDIA GB300 Grace™ Blackwell Ultra Desktop Superchip
@KuptoKosmos Il nous faut un tuto clair pour bannir totalement utiq de nos ordis. Perso je suis perdu là, pourtant je suis pas le dernier des noob en info. Je commence à devenir total parano.
‼️⚠️😡 BOYCOTT UTIQ
Dernier avertissement, lisez bien...
Ils utilisent des techniques de hackers pour nous pister en douce
Ils obligent les grands médias à créer des sous-domaines du style :
utiq.bfmtv .com
utiq.lefigaro .fr
La liste est longue !
Ils pointent discrètement via une astuce DNS appelée CNAME vers leurs vrais serveurs AWS :
frontend .prod.utiq-aws.net
Ton navigateur se fait complètement avoir il croit que c’est du contenu tout ce qu’il y a de plus normal du site que tu lis !!
Utiq peut alors balancer des cookies comme si c’était le site lui-même, choper ton IP réelle et lancer le tracking via ton opérateur
C’est du CNAME cloaking bien dégueulasse, une vieille technique de merde utilisée depuis 2019 pour rendre les trackers invisibles
Les coups de vicieux :
- Dans les pop-ups cookies, ils glissent tranquillement Utiq dans la liste comme si c’était un simple cookie à accepter... alors que c’est un tracking beaucoup plus vicieux via ton opérateur
- Résultat des dizaines de millions de Français (environ 40 millions rien qu’en France selon leurs propres chiffres récents, et jusqu’à 80 millions en Europe) se retrouvent dans la base Utiq sans avoir vraiment eu l’impression de choisir ou de comprendre ce qu’ils acceptaient. Ça, ce n’est clairement pas du consentement libre et éclairé 🤔
- En plus, ils rendent la révocation ultra-compliquée et décourageante, bien au-delà du simple fait de vous attirer discrètement. Ce n’est pas honnête du tout !!
- La bannière est floue à mort rien ne te dit clairement que ton opérateur va te pister avec ton abonnement
- L’identifiant créé est persistant il survit à la navigation privée, au vidage de cache et au changement de navigateur
- Les opérateurs se font maintenant du blé sur une donnée qu’ils possédaient déjà... sans jamais vraiment alerter les gens !!
À savoir : Sur un WiFi partagé c’est l’abonnement du foyer hôte qui se fait tracer, pas le tien
Ce n’est PAS une alternative "propre" aux cookies tiers
C’est pire... plus discret, plus lié à ta vraie identité, et planqué derrière le nom du site que tu lis !!
Utiq c’est du greenwashing technique pur et dur. À bloquer sans pitié
😡 Bombardez le mail [email protected] avec vos plaintes massives, et tag @CNIL pour leur mettre le nez dans ce hack dégueulasse monté par les opérateurs et Utiq.
Voir les liens et solutions dans les commentaires...
#Privacy 🛡️
Let me trace the timeline here because nobody's connecting it.
Step 1: Scrape the entire internet. Every book, every article, every conversation, every piece of art, every forum post. Do it without asking. Do it without paying.
Step 2: Train a model on all of it. Call it "artificial intelligence."
Step 3: Go to BlackRock's Infrastructure Summit and announce: "We see a future where intelligence is a utility, like electricity or water, and people buy it from us on a meter."
Step 3 is where you sell people's own knowledge back to them. On a meter.
They took the collective output of human thought, compressed it into a model, and now they want to charge you by the token to access a version of what you and everyone you know already created.
One Reddit user put it perfectly: "They stole all this data from us, the people, our life's work, creativity, art, by devouring the internet and blowing through all copyright laws. Now they want to sell it back to us in the form of a utility."
Imagine if someone photocopied every book in the public library, burned the library down, and then opened a subscription service for the copies.
That's the metered intelligence business model.
And they're pitching it to infrastructure investors as though they invented water.
i just beat @GoogleDeepMind's turboquant
introducing Shard. 10x KV cache compression on Llama-3.1-8B. zero quality loss
- 10x @ 8K context, 11.2x @ 32K
- NIAH recall 1.000 across 4K-32K
- LongBench Δ ≈ 0 vs FP16
turboquant tops out at 4-6x at the same quality. we doubled it.
read more: https://t.co/PAV5WdAzN6
@kirrithan
Première mondiale ! Un robot a travaillé 200h non-stop, et trié plus de 249 000 colis à lui seul. Pas une seule panne, pas une seule pause et tout a été diffusé en live pour le prouver.
À la base c'était un défi de 8h. Le robot a tellement bien tourné qu'ils ne l'ont jamais coupé. 200 heures plus tard il tournait encore.
Le truc de fou, c'est qu'il y a quelques jours un stagiaire a fait un duel contre le robot sur un shift de 10h. Le gars a gagné. De justesse, 2.79 secondes par colis contre 2.83 pour la machine. Sauf que le stagiaire a fini avec l'avant-bras en vrac. Le robot lui il a continué 190 heures de plus sans broncher.
Et c'est là que je comprends pas. On a littéralement un robot humanoïde qui fait un boulot d'entrepôt en continu, sans supervision, tout est géré par son IA embarquée. Si le robot bug, il se reset tout seul et reprend. Si il a un souci hardware, il sort de la ligne et un autre prend le relais automatiquement.
Malgré tout ça, la majorité des gens ne voient pas ce qui arrive. On scrolle, on passe, on se dit "c'est cool" et on oublie. Mais c'est pas "cool". C'est un changement de civilisation. Les tâches physiques répétitives vont être automatisées.
La robotique humanoïde c'est le sujet dont personne ne parle assez. On commence à peine à parler d'IA avec bien du retard, sauf qu'il faut comprendre que l'étape d'après c'est l'IA incarnée, cad, les robots.
I made busybeaver a 50M model to do tool calling because its an arguably small range of possibilities. It did okay, so i pivoted to asking "is this even an LLM job?" turns out the range of possibilities is constrained enough that it doesnt. Obviously needs much more rigorous testing for true empirical claims. But, based on this experiment and some refinements it appears to be the case.
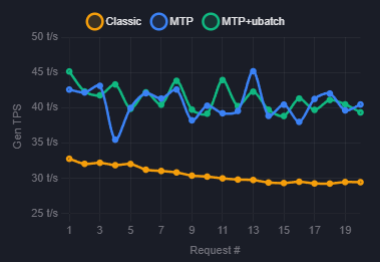
Try "--ubatch-size 256" with MTP!!!
Uses 1GB less VRAM (70k context with vision) :
ub 1024 = 22.5GB
ub 256 = 21.5GB
=> I've been able to increase context back to 120k (22.5GB VRAM) with ub 256! (K Q8 and V Q4)
Don't ask me why, I don't know
Performances are similar (20 chained requests with different ctx and gen, uses KV cache)
Hardware : RTX 3090 @ 260W
My results with MTP from @UnslothAI
Qwen3.6 UD 4 K XL on a RTX 3090 @ 260W.
Quite faster on generation but slower on prefill.
You will have to reduce your context windows by a lot (120k to 70K with vision with KV Q8).
--spec-type draft-mtp \
--spec-draft-p-min 0.75 \
--spec-draft-n-max 2