Frontier models are powerful advisors.
On @harvey's Legal Agent Benchmark, a GLM 5.1 worker using Claude Opus 4.7 as a sparse advisor reached 18/100 all-pass versus 14/100 for Opus alone, at 39% of the cost.
More on the harness design, advisor pattern, and training results: https://t.co/ozxFycdzcT
At 30 trillion tokens a day, we're the largest inference provider outside the frontier labs' own APIs.
We're hiring.
Come build the infrastructure behind the top AI workloads: https://t.co/bUweMxMq9L
📸 @Wing VC's 2026 Enterprise Tech 30 list (thanks @WingVC @ericnewcomer)
Kimi has been the most popular model on Fireworks, both out of the box and as a fine-tuning base (including Composer 2)
Now Kimi K2.6 is live with huge jumps (10+%) in coding, long-running agents and deep research
Try it out for inference or fine-tuning!
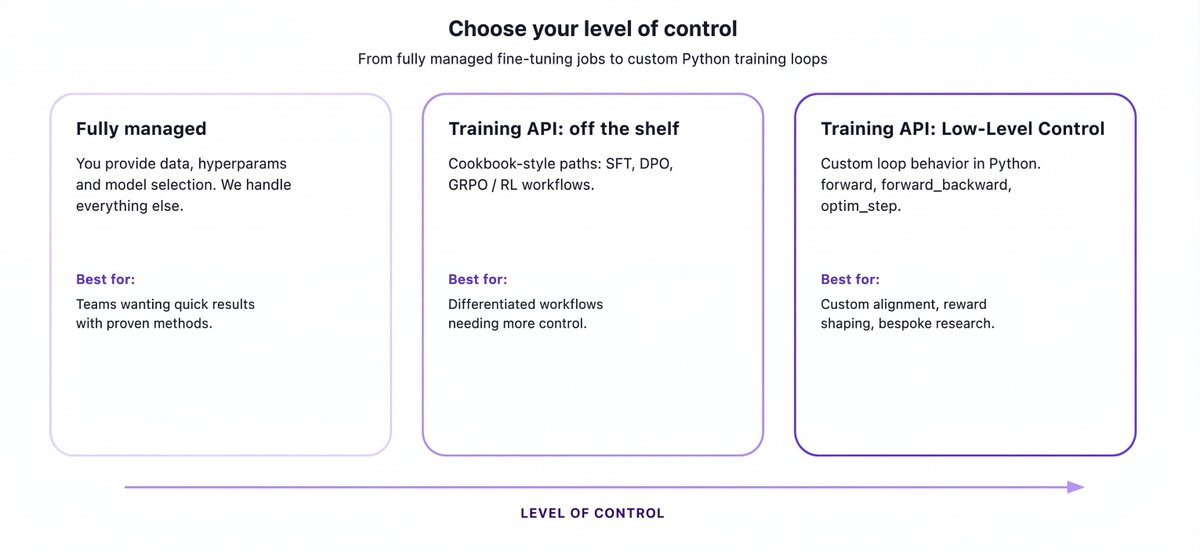
Fireworks Training is now in preview.
You can now full-parameter fine-tune Kimi K2.5 (1T params, 256k context) with custom loss functions (GRPO, DRO, DAPO, or bring your own) on managed infra.
@genspark_ai built their proprietary model stack in four weeks. @vercel hit 93% error-free generation with RFT. @cursor_ai runs their RL rollout fleet on Fireworks.
Full-parameter from 8B to 1T. Multi-LoRA serving. Managed or bring your own training loop.
Your model is your product. Your data is your moat.
https://t.co/kyz7HzihC1
Training trillion-parameter MoEs is an infra problem disguised as a modeling problem.
So we built the infra solution. Cursor used it to train Composer 2. Now it's available for Kimi K2.5, Qwen3.5 397B, MiniMax M2.5, and more:
→Fused RL loss (~2x faster PPO)
→MXFP8 expert kernels on Blackwell
→Composable 4D parallelism
→1M+ token context training validated
Here's how it all works ↓
https://t.co/PA20I8EFaD
Most teams don’t hit a fine-tuning bottleneck because they picked the wrong algorithm.
They hit the bottleneck because the loop around training is too slow:
-data plumbing
-eval setup
-deployment friction
-too much guesswork between runs
People of the virtual sphere, check out the recently published "Shared and specialized coding across posterior cortical areas for dynamic navigation decisions", quality work from the Harvey Lab's @ShihYiTseng1 @selmaanchettih @CharlotteArlt!
https://t.co/Aqt0xxew5B
Could not be happier for @CharlotteArlt and the Harvey Lab @harvardmed. Some quality science I had the fortune of working on out on pre-print now! Check it out!
Excited to share some of my postdoc work as a @biorxivpreprint from the Harvey lab @harvardmed. We show that mice rely on different cortical areas for navigation decisions, depending on what other complex tasks they have previously learned. Training history matters!
Dig into digital influence operations with us *tonight* @ 7pm CST. @BobBarroso & @nick__tallant of Omelas will discuss the map they've created of the online information environment to detect digital influence campaigns used to undermine democratic values.
https://t.co/WshtIrm84F
People of the virtual world, check out some quality work from the students of @UChicagoCAPP using data viz to understand a multitude of relevant policy issues.
https://t.co/IZUCiwLBKx
A tad late but thought I'd share. Worked with the brilliant @HanaPassen
investigating methods to demystify results from dimensionality reduction. Check it out!
https://t.co/3AJdSfrefn
@jesicaramirezto, Oscar and @StephieRamos explored crime statistics in Mexico City to better understand trends, patterns, and assess the safety of citizens. See: https://t.co/Tl7HEoVF35
Maps tell stories, and these maps tell familiar stories. See how public health indicators in Chicago correlate to demographic indicators along the CTA. See what @maerunes, @HanaPassen and @BobBarroso created: https://t.co/1yBqsiMmbP