1/3 Big news!! After more than 750 pull requests from 89 contributors and 19 months since our first release in May 2020 we are happy to announce the 1.0 release of #Haystack! 🎉🎁🖖 https://t.co/gUEVZISoko (release notes here: https://t.co/UJCsHD1Wgb)
@konnrex87 @deepset_ai Also happy to continue this conversation through Github or our Slack channel (https://t.co/KKFq3o3T3i) where we can have a deeper dive into the topic!
@konnrex87 @deepset_ai Hey Konstantin, thank you very much! The __init__() of the ElasticsearchDocumentStore has a custom_mapping argument. Here's our API specs for that fn (https://t.co/5hVL3EW0gx). Is this what you're after?
.@pydataberlin May 2021 (Online) Meetup is tomorrow, May 19! @BrandenChan3 will talk about #Haystack :) Full event description here: https://t.co/kcXFWtflgi See you there!
Great to be trending on GitHub again! https://t.co/u2RuJAf0nk We've added quite a lot to Haystack since 0.7.0, and it's awesome to see more people using it!
We've been lately optimizing preprocessing and it's now FAST! Converting 7.4 GB of DPR data in 45 seconds on @timomo1234's laptop. Kudos to @huggingface for fast tokenizers, but also to @rustlang !
Our top @NYNLPmeetup program video: "Question Answering Beyond SQuAD: Larger Datasets and New Domains," with @BrandenChan3 from @deepset_ai, May 26, 2020
https://t.co/npbmw5AdzC
#NLProc
Lots of great #QuestionAnswering work at #COLING2020 ! @BrandenChan3 shares 4 papers that caught his attention. Read to find out more about robust QA models, user feedback for models, efficient approaches to AS2 style QA. https://t.co/zWUWj3Wy75 #nlp#nlproc#transformers
Shout out to @deepset_ai who are building something really special. This is the most complete implementation of an end-to-end search stack utilizing state of the art nlp approach.
https://t.co/xULv13G8fC
@emnlp2020, would love to register but the registration site seems to be broken! This is what it is showing even though I've never been on the site. Tried different browsers, devices and internet connections. Is there some other way I could register? Thanks!
Got a paper accepted at COLING2020! Stefan Schweter, Timo Möller and I trained a new set of SoTA German BERT and ELECTRA models. We perform evaluation over the course of training to show just how quickly the models are learning.
Preprint: https://t.co/SF4QFOFUwn
#NLProc#ML
We are proud to announce the 29 accepted papers for the first Computational Humanities Research Workshop. It promises to be a diverse program with papers on history, cultural evolution, literary studies, linguistics, methods, a.o. Find papers here >> https://t.co/bc0XkDaLFg
🎉 Excited to release Haystack 0.4.0! 🎉
With 50+ pull requests, it's a really big one including many new features that will help you build a scalable #QuestionAnswering System!
📑 Release notes https://t.co/GI0ak8v5jc
Big thanks to all contributors!
#NLP#ML#DeepLearning
RigL is a new algorithm for training sparse neural networks. Instead of pruning a pre-existing dense network, it dynamically builds one during training without sacrificing accuracy relative to traditional approaches. Learn how it’s done at https://t.co/VZa1Ve9uH1
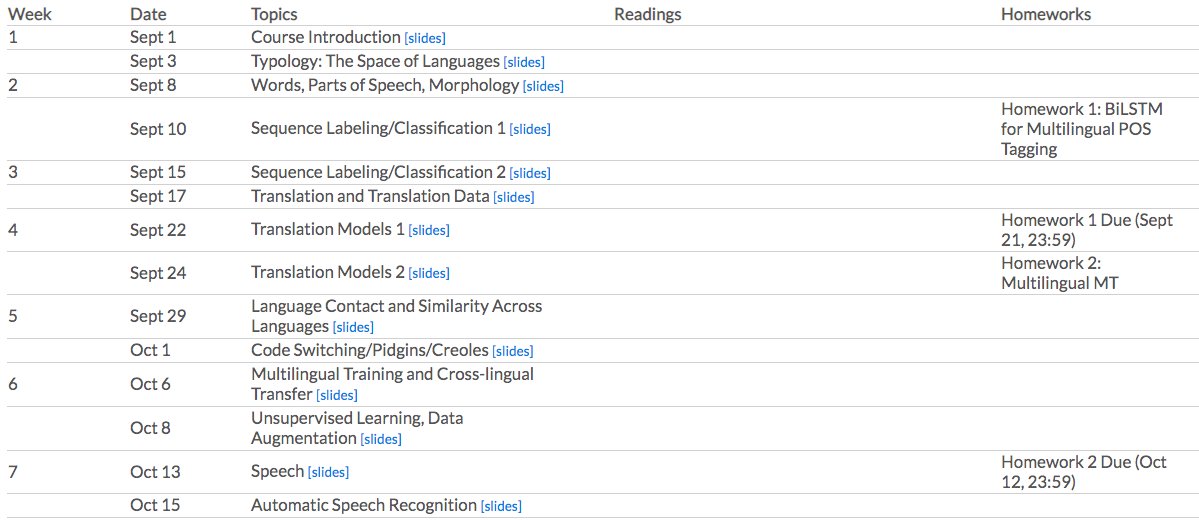
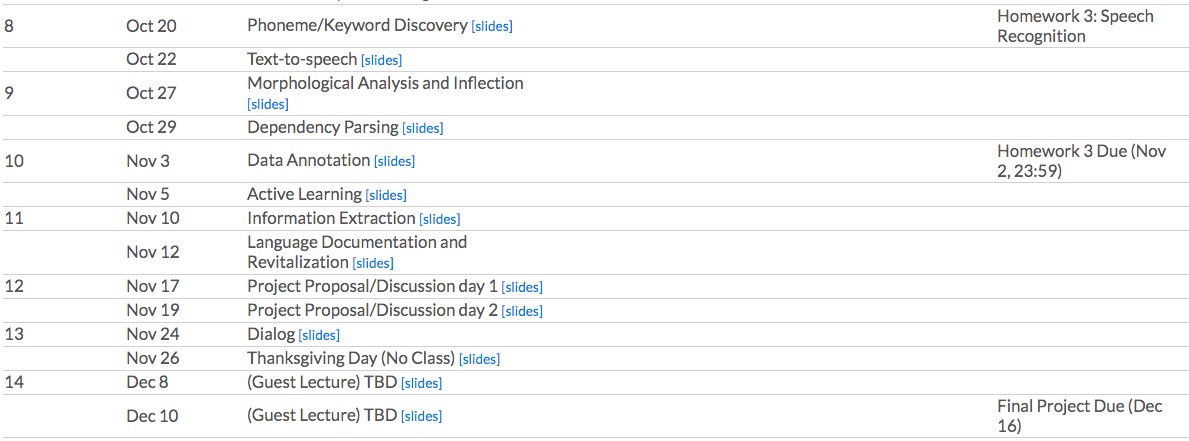
Looking forward to our *brand new class*, CMU CS11-737 "Multilingual Natural Language Processing" this semester with Yulia Tsvetkov and Alan Black! We're covering the linguistics, modeling, and data that you need to build NLP systems in new languages: https://t.co/ajKxNV2CkT 1/2
Some reflections on @emilymbender and @alkoller's #acl2020nlp paper on form and meaning, and an attempt to crystallize the ensuing debate: https://t.co/NRO8lBQIhg