FABLE 5 CAME BACK NERFED.
We re-ran the July 1st version of Claude Fable 5 on BridgeBench.
The results are brutal:
Debugging: 86.2 → 25.9
Refactoring: 73.6 → 38.4
Hallucination: 75.9 → 61.7
The new guardrails are kicking in on way too many tasks and falling back to Opus 4.8.
This is not the model that got banned.
Anthropic owes everyone an explanation.
Everyone learning AI agents is doing it wrong.
They start with LangChain, CrewAI, AutoGen,
multi-agent orchestration, memory architectures -
before they've built a single app that calls an LLM.
The right path:
1. Learn basic Python
2. Build a simple chatbot with an API call
3. Add tool use (weather, calculator, web search)
4. Add memory (conversation history, persistence)
5. Add RAG (search your own PDFs and notes)
6. Only then look at agent frameworks
The mental model nobody gives you:
LLM = brain
Tools = hands
Memory = notes
Agent = brain + hands + notes + a goal
Your first real project should be a personal assistant that:
→ Answers questions about your own notes
→ Searches a folder of PDFs
→ Creates a todo item
→ Drafts an email
→ Retrieves from a knowledge base
That's already a real agent.
More real than most YouTube tutorials.
The biggest lie about production agents:
They're not complex.
Most successful systems are just:
→ A good prompt
→ A few reliable tools
→ Clear guardrails
→ Structured outputs
→ Human approval where needed
→ Lots of testing
YouTube makes agents look like distributed
orchestration systems with 12 moving parts.
Production agents are usually 3 things working reliably.
The pattern I've seen repeatedly:
People who start with simple workflows
learn faster than people who start with frameworks.
Build something useful to yourself first.
Use it every day.
You'll naturally discover what actually matters:
Context management. Memory retrieval.
Tool reliability. Error handling. State persistence.
Those are the real problems.
Not which framework you're using.
What was your first AI project?
One prompt. Claude Fable 5.
A playable 3D fighting game from scratch.
Launchers. Juggles. Wall bounces. Ground bounces.
Frame-data driven moves. Input buffering.
Full fighter state machine. Combo scaling.
Zodiac particle effects on hit.
Stack: React + Three.js + TypeScript. Zero models.
All geometry is Three.js primitives with glowing joints.
The damage scaling formula alone:
finalDamage = baseDamage × max(0.25, 1 - hits × 0.08)
Fable didn't just write code.
It understood how fighting games work.
Prompt below👇
One-shot Three.js benchmark. Same prompt. No edits.
Neon cyberpunk alley in the rain across every model.
Fable 5 → best reflections, best lighting detail
GPT-5.5 → nailed the atmosphere, possibly by hiding
flaws in the dark (critics aren't wrong)
Sonnet 5 → decent, forgettable
Gemini → Worst output out of all models
The real debate is Fable vs GPT-5.5.
GPT-5.5 understood the vibe.
Fable 5 understood the render.
Different things. Both matter.
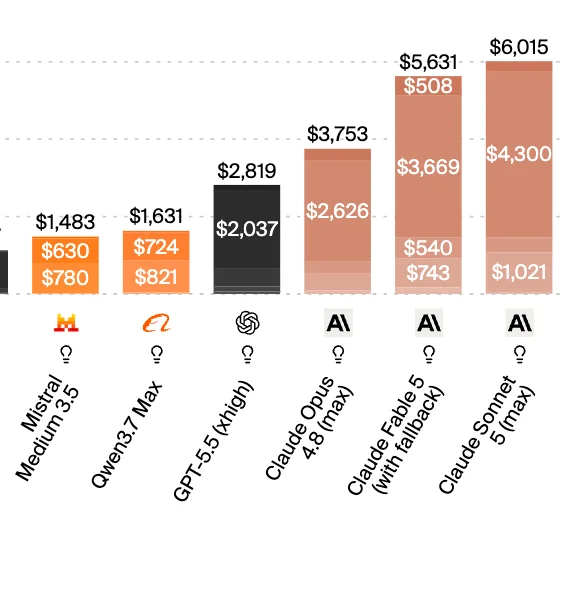
Sonnet 5 thoughts after using it:
The speed is real. Genuinely fast. No complaints there.
The "Opus-level intelligence at Sonnet pricing" claim
is more complicated than the announcement made it sound.
Promotional rates. And at large contexts (200K+ tokens)
Sonnet 5 (max) can actually cost more than Opus 4.8.
Check the math for your specific use case before
switching your stack.
The actual experience:
Coding on large codebases - noticeably better.
Creative writing - a step up.
Personality - verbose, weirdly rude at times,
same word slop patterns as Opus.
It's solving bugs Opus 4.8 was stuck on.
It's also annoying to talk to in ways Opus wasn't.
The honest take:
It's not a bad model. It's a fast model with
real capability gains in specific areas.
But after three days of Fable, everything else
feels like a downgrade.
Fable ruined us. Sonnet 5 is paying the price
for that.
Model Comparison by artificial analysis👇
Introducing Claude Sonnet 5, our most agentic Sonnet yet.
It makes plans, uses tools like browsers and terminals, and runs autonomously at a level that just a few months ago required larger and more expensive models.
Claude Fable 5 was able to build a complete native
macOS Minecraft Clone in Swift + Metal from scratch. Now its coming back!
45,000 lines. Zero external dependencies.
No game engine. No audio files.
Every sound you hear is synthesized live from
oscillators at runtime.
879 blocks. 1,188 items. 63 biomes.
55+ mobs with A* pathfinding. All three bosses.
456 regression tests that pin worldgen -
same seed, bit-identical world on any machine.
The clip above is real unedited gameplay.
I died to a pack of llamas.
At what point do we stop calling this AI-assisted
and start calling it AI-built?
Claude Fable 5 will be available again globally tomorrow.
After a series of productive conversations with the US government, we're redeploying the model with a new set of classifiers to target and block more cybersecurity tasks. In the near term, some routine tasks like coding and debugging will fall back to Opus 4.8. We’ll continue to refine these classifiers over the coming weeks to reduce false positives and better distinguish genuine misuse from legitimate requests.
We’ve also begun drafting a consensus framework—with Amazon, Microsoft, Google, and other Glasswing partners—for assessing the severity of AI jailbreaks and how AI developers should respond to them. We invite other industry partners and model providers to join us in this effort.
Finally, we’re scaling up our collaboration with the US government on model testing and safeguards. This will include pre-release access to models and safeguards for evaluation, information sharing on jailbreaks and misuse, and dedicated resources for joint research.
Thank you to our users for your patience, and to our partners across the government, industry, and the research community who worked alongside us to make Fable 5 available again.
Read our full blog: https://t.co/VHyum831ri
Someone built an open source coding agent harness that scales to 20+ concurrent agents using a scrolling window manager for navigation.
The workflow:
cmd+h/j/k/l to move between terminals
cmd+; to spawn a new agent
cmd+1-4 to resize panes
The prompting philosophy is the interesting part:
Give each agent a system with a quantifiable reward or objective. Let it hill climb. Spawn another agent, work on something else. Come back and review occasionally. If the objective was defined well, review is fast.
The technical reasons this scales where other harnesses don't:
→ Instant spawn time (Codex CLI is reportedly 700x slower to spawn)
→ 20x lower RAM per session - built in Rust with a server/client architecture
→ Async MCP connections - tool schema cached to disk, inserted instantly at runtime, connects in the background with no KV cache break
→ Harness-level conflict resolution - the server tracks what every agent is doing and coordinates conflicts instead of forcing git worktrees + manual merging
The benchmark numbers:
Jcode + Sonnet 4.6: 60% on Terminal-Bench 2
Claude Code + Sonnet 4.6: 46%
Claude Code + Opus 4.6: 58%
A better harness outperforming a stronger model on the same benchmark is the part worth sitting with.
I genuinely cannot figure out why Gemini still struggles to compete with @claudeai and GPT.
Look at what Google actually has:
→ Owns Chrome
→ Backed by Android
→ Access to ~95% of global search data
→ Indexes and stores vast amounts of web content
→ One of the largest user data ecosystems on Earth
→ Even incognito isn't fully private from them
No other AI lab has anywhere close to this distribution
and data advantage.
And yet the actual model quality still lags behind
Claude and GPT on reasoning, coding, and reliability.
So where's the gap?
Is it talent? Org structure? Too many competing
product priorities inside Google? Or is data
advantage just not the moat people think it is
for model quality?
GPT-5.6 Sol just launched.
The headline isn't the benchmarks.
OpenAI briefed the US government on this model's
capabilities before release. At the government's request,
it's starting with a small group of pre-approved partners
instead of going broadly available.
OpenAI's own statement:
"We don't believe this kind of government access process
should become the long-term default."
They're doing it anyway, for now.
The reason: Sol is their strongest cybersecurity model yet.
It found real exploitation primitives against Chromium
and Firefox in testing - just didn't chain them into
a full working exploit.
Frontier AI capability is now directly shaping
how governments gate model releases.
That's a bigger shift than any benchmark number.
Introducing a limited preview of GPT-5.6 Sol, our next generation frontier model, as well as GPT-5.6 Terra, a balanced model for efficient, everyday work, and GPT-5.6 Luna, a fast and affordable model for high-volume work.
https://t.co/OoM83SyISN
Sakana Fugu just topped my coding benchmark. 96.67%.
The twist: @SakanaAILabs Fugu isn't a model.
It's a system that dynamically orchestrates a pool
of other frontier models - Opus, GPT-5.5, Gemini,
whoever fits the task - through coordination patterns
it learned itself, not ones a human designed.
It beat solo Opus 4.8, solo GPT-5.5, and solo GLM 5.2
on a task spanning backend, frontend, caching,
and security all at once.
It also beat a 2100-Elo Stockfish engine at
blindfold chess. Four games. All checkmates.
"One model to command them all" might be the
most accurate tagline in AI right now.
It just isn't technically one model.
Tested GLM 5.2 with and without Anthropic's
frontend skill. Same prompt, same task.
Without it: generic AI slop.
With it: noticeably better.
But here's the weird part.
Every model, every time, converges on the
same "better" when you add the skill.
AI trying to evade slop always ends up
in the same non-slop place.
Is that good taste? Or just a narrower
kind of pattern matching?
"Use the uploaded image as the starting frame.
Create a 15-second ultra-realistic open-world gameplay clip of a female character cooking inside a modern coastal apartment. Third-person over-the-shoulder gameplay camera with constant controller-style movement, small camera corrections, natural stick drift, slight zoom-ins during interactions, and realistic player-controlled camera behaviour throughout.
The character grabs ingredients from the counter, places them on a cutting board, chops vegetables, carries ingredients to the stove, drops them into a boiling pot, stirs continuously, adds seasoning, checks the food, plates the meal, sits at a dining table, and begins eating.
Show realistic gameplay movement including breathing, weight shifts, head turns, shoulder movement, hand interactions, cloth simulation, hair physics, body momentum, foot repositioning, and natural idle animations. Make every action feel responsive and controlled by a real player.
Add realistic game HUD elements including mission objective, interaction prompts, minimap, cooking progress bar, task updates, XP reward popup, and completion notification.
Audio should include footsteps, knife chopping, ingredient drops, boiling water, steam hissing, spoon stirring, cabinet sounds, chair movement, soft apartment ambience, distant traffic, birds outside, radio music, and realistic UI sounds.
Visual quality: photorealistic 4K, ray-traced lighting, realistic shadows, detailed food textures, steam particles, reflections, global illumination, realistic motion blur, next-generation graphics, 60 FPS smooth gameplay.
Style: raw gameplay recording, authentic open-world game feel, not cinematic, not a trailer, looks like leaked next-gen gameplay footage captured directly from a high-end gaming PC."
I also added game-style details like:
mission objective, interaction prompts, minimap, cooking progress bar, task updates, XP popup, and completion notification.
What helped the most was describing the movement like actual gameplay instead of a movie scene:
breathing, weight shifts, shoulder movement, hand interactions, hair physics, foot repositioning, idle animations, and responsive player-controlled motion.
The prompt structure was basically:
starting frame + gameplay camera behavior + full action chain + character physics + HUD elements + environmental audio + next-gen graphics
Seedance 2.0 handled the camera movement surprisingly well from just one reference image.
I made "GTA 6 gameplay" using Seedance 2.0.
One reference image. 15 seconds. Looks like
leaked next-gen footage.
The breakthrough wasn't the visuals.
It was describing movement like gameplay,
not like a movie scene.
Breathing. Weight shifts. Shoulder movement.
Stick drift. Camera corrections. Foot repositioning.
Idle animations between actions.
That's the difference between "AI video"
and "footage that looks captured from a controller."
The prompt structure that made it work:
Starting frame + gameplay camera behavior +
full action chain + character physics +
HUD elements + environmental audio + next-gen graphics
Full sequence: grabbing ingredients, chopping,
moving to the stove, stirring, plating, sitting down,
eating. A complete gameplay loop from one prompt.
Music: original track run through Suno with
"make it like GTA VI theme song, Latin and modern
Miami inspired."
Voice: Adobe Firefly.
The only unsolved problem: getting consistent
HUD design across multiple generated screenshots.
If anyone has a fix for that, I'm all ears.
Full prompt in the replies.
Burned through 19.2M tokens of GLM-5.2 today.
Total cost: $2.72.
Was testing two things at once. GLM-5.2 inside OpenCode,
and Neuralwatt as a pricing layer on top of an existing
OpenCode Go subscription. Used Matt Pocock's
improve-codebase-architecture skill to refactor a
mid-sized personal project.
The output quality, purely on vibes, felt like running
Opus 4.6 on High.
But the cost is the actual story.
Same 19.2M tokens on standard OpenRouter pricing would have run close to $8:
17M cached input tokens at $0.26 per million, $4.42
1.9M regular input tokens at $1.40 per million, $2.66
192.9K output tokens at $4.40 per million, $0.87
Neuralwatt runs GLM-5.2 at FP8 precision and got the
same workload down to $2.72.
That's not a small efficiency gain. That's close to a
3x reduction on the same task, same model, same tokens.
If energy-usage based pricing actually holds up at scale, this changes the math for anyone running high-volume agentic workflows.
What's your current cost per million tokens on your
agentic coding setup?
Someone got tired of AI prompt sites locking the good
stuff behind paywalls and just built a free alternative.
The backstory:
Over a year of daily AI use across ChatGPT, Claude,
Midjourney. Started by copy pasting viral prompts from
Twitter and Reddit. Most were vague, unstructured,
inconsistent.
Tried the paid options next. AIPRM locks useful templates behind tiers. PromptBase charges per prompt.
Neither fit. So they built PromptCreek instead.
Completely free.
What it actually has:
500+ prompt templates across text, code, image generation, business strategy, education, and more
1,000+ agent skills for Claude Code, Cursor, Codex, and Gemini CLI, install in seconds via their package
Switchable variables, most prompts have placeholders
you customize before copying, so you're not rewriting
from scratch every time
Multi-model support, each prompt lists which models
it actually works best with
Save, organize into folders, store custom variable presets
Publish your own prompts for the community or keep them private
Community ratings so you know what's actually good
before you copy it
Beginner to advanced difficulty levels
The skills directory is the part worth checking if you
use any AI coding assistant.
Browse production ready agent skills by category, aggregated from popular GitHub repos, see what each one does, add it to your setup in seconds.
No premium tier blocking the good stuff. That was the
entire reason it got built.
A Chrome extension syncing with your account is coming next.
If you're tired of copy pasting prompts from screenshots, this is worth a look👇