Mission accomplie à Kinshasa : l’équipe Mediabox est de retour
Notre équipe revient d’une mission intense et structurante en République Démocratique du Congo, marquée par un engagement professionnel exemplaire et des échanges stratégiques de haut niveau avec des institutions partenaires. Ces discussions ont permis d’évaluer la faisabilité et la robustesse de plateformes et de systèmes applicatifs critiques en environnement souverain, tout en renforçant la confiance dans nos solutions.
Cette mission a confirmé ce qui distingue #Mediabox sur le terrain : la capacité à s’adapter, à intégrer des exigences institutionnelles complexes dans des délais contraints et à livrer avec rigueur et méthode, même dans des contextes sensibles. Chaque interaction a consolidé la crédibilité de notre approche opérationnelle et la solidité de nos dispositifs.
Mediabox s’affirme de plus en plus comme un intégrateur souverain, capable de concevoir, sécuriser et opérer des systèmes numériques critiques pour les États. Notre positionnement repose sur une double maîtrise : celle du terrain opérationnel et celle des cadres normatifs internationaux (qualité, sécurité de l’information, gouvernance IT, continuité d’activité), traduits en architectures concrètes, auditables et résilientes. Nous ne livrons pas uniquement des technologies, mais des capacités institutionnelles durables, alignées sur les standards internationaux et les réalités locales.
Au-delà des résultats immédiats, cette mission ouvre la voie à des projets structurants de grande ampleur, qui nécessiteront dans les mois à venir une coordination rigoureuse, une planification méthodique et une exécution sans compromis sur la qualité, la sécurité et la souveraineté des systèmes déployés. Nous nous retrouverons prochainement pour préparer collectivement ces prochaines étapes avec la méthode et l’exigence qui font notre force.
Un grand bravo à toute l’équipe pour son professionnalisme, sa résilience et son engagement.
Le terrain a parlé, et Mediabox a répondu présent.
🚀 Le meilleur reste à venir.
#Mediabox #MissionRDC #SouverainetéNumérique #InnovationPublique #SystèmesCritiques #Coopération #Excellence #Équipe #PartenariatStratégique #RDCongo
You must know these 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗦𝘆𝘀𝘁𝗲𝗺 𝗪𝗼𝗿𝗸𝗳𝗹𝗼𝘄 𝗣𝗮𝘁𝘁𝗲𝗿𝗻𝘀 as an 𝗔𝗜 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿.
If you are building Agentic Systems in an Enterprise setting you will soon discover that the simplest workflow patterns work the best and bring the most business value.
At the end of last year Anthropic did a great job summarising the top patterns for these workflows and they still hold strong.
Let’s explore what they are and where each can be useful:
𝟭. 𝗣𝗿𝗼𝗺𝗽𝘁 𝗖𝗵𝗮𝗶𝗻𝗶𝗻𝗴: This pattern decomposes a complex task and tries to solve it in manageable pieces by chaining them together. Output of one LLM call becomes an input to another.
✅ In most cases such decomposition results in higher accuracy with sacrifice for latency.
ℹ️ In heavy production use cases Prompt Chaining would be combined with following patterns, a pattern replace an LLM Call node in Prompt Chaining pattern.
𝟮. 𝗥𝗼𝘂𝘁𝗶𝗻𝗴: In this pattern, the input is classified into multiple potential paths and the appropriate is taken.
✅ Useful when the workflow is complex and specific topology paths could be more efficiently solved by a specialized workflow.
ℹ️ Example: Agentic Chatbot - should I answer the question with RAG or should I perform some actions that a user has prompted for?
𝟯. 𝗣𝗮𝗿𝗮𝗹𝗹𝗲𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻: Initial input is split into multiple queries to be passed to the LLM, then the answers are aggregated to produce the final answer.
✅ Useful when speed is important and multiple inputs can be processed in parallel without needing to wait for other outputs. Also, when additional accuracy is required.
ℹ️ Example 1: Query rewrite in Agentic RAG to produce multiple different queries for majority voting. Improves accuracy.
ℹ️ Example 2: Multiple items are extracted from an invoice, all of them can be processed further in parallel for better speed.
𝟰. 𝗢𝗿𝗰𝗵𝗲𝘀𝘁𝗿𝗮𝘁𝗼𝗿: An orchestrator LLM dynamically breaks down tasks and delegates to other LLMs or sub-workflows.
✅ Useful when the system is complex and there is no clear hardcoded topology path to achieve the final result.
ℹ️ Example: Choice of datasets to be used in Agentic RAG.
𝟱. 𝗘𝘃𝗮𝗹𝘂𝗮𝘁𝗼𝗿-𝗼𝗽𝘁𝗶𝗺𝗶𝘇𝗲𝗿: Generator LLM produces a result then Evaluator LLM evaluates it and provides feedback for further improvement if necessary.
✅ Useful for tasks that require continuous refinement.
ℹ️ Example: Deep Research Agent workflow when refinement of a report paragraph via continuous web search is required.
𝗧𝗶𝗽𝘀:
❗️ Before going for full fledged Agents you should always try to solve a problem with simpler Workflows described in the article.
Learn how to leverage these patterns hands-on in my End-to-end AI Engineering Bootcamp. Next cohort kicking off on January 12th: https://t.co/gWBu8OLTzn
🎁 Code NYRESOLUTION for 10% off.
What are the most complex workflows you have deployed to production? Let me know in the comments 👇
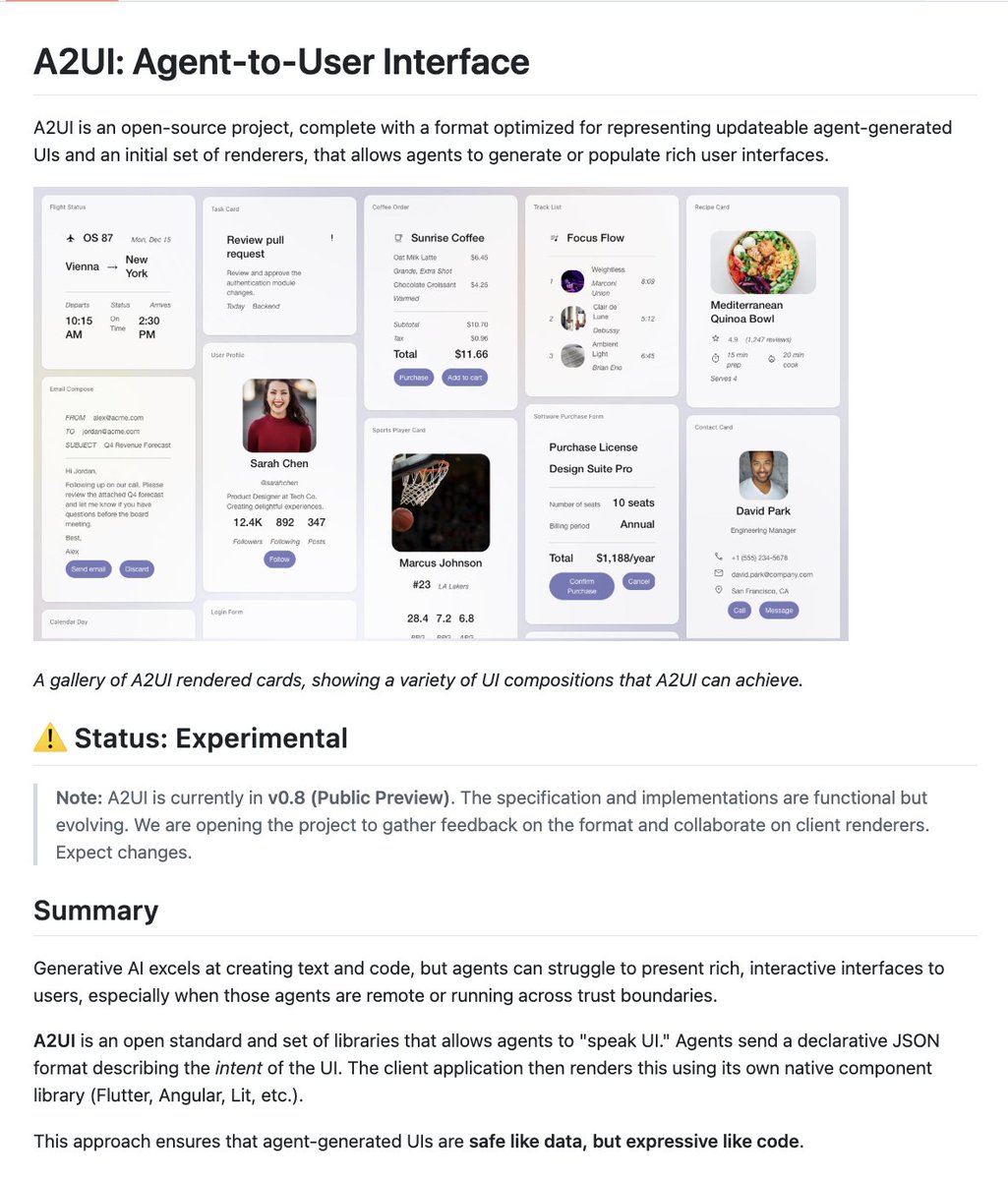
Google just opensourced Agent-to-User Interface (A2UI).
AI Agents can now generate native, interactive UIs on the fly.
Works with React, Flutter, SwiftUI, and any framework.
100% Opensource.
📞 Phone Calling Agents Course
Made by the LangChain Community
Learn to build production AI call centers from scratch. Create voice agents that handle real phone calls through Twilio with real-time conversations and property search capabilities.
📚 Course repo: https://t.co/1ZEXwblHDU
Google just launched a new browser... sort of. Meet "Disco" and "GenTabs." Powered by Gemini 3, it takes your open tabs and builds custom mini-apps on the fly. https://t.co/81ifBYqK6l
- Google Maps uses graph ML to predict ETA
- Netflix uses graph ML in recommendation
- Spotify uses graph ML in recommendation
- Pinterest uses graph ML in recommendation
Here are 6 must-know ways for graph feature engineering (with code):
Introducing Scheduled Tasks.
Continuous Integration meets Continuous AI.
Set the frequency: nightly package releases, weekly dependency updates, or monthly backlog sweeps. Jules not only can publish the release but can fix any errors while doing it, all in background while you focus on what matters (or get some sleep).
Available to all users today: https://t.co/pKENn6cr9R
Shipmas Day 2: Bonus Drop. 🚢🎁
We taught Nano Banana Pro to see like a user. 👀
Introducing Predictive Heatmaps.
Now you can run an instant attention audit on any screen you design. Ensure your users are focused exactly where you want them to be—before you write a line of code and without waiting for data.
Live now in the Generate menu.
We're in our Vibe Design era 💃
Our @GoogleLabs product Stitch just launched Prototypes, which lets you build an interactive experience with absolutely no code.
And yes, it's free and uses the amazing Gemini 3 model 💪
You can now select multiple screens and "stitch" them together into a fully functional, clickable user flow. (Get why we called the product Stitch??)
- Create clickable user flows
- Test interactions and animations
- Ask for edits by clicking divs on the screen
- Export the full context to AI Studio or other coding agents
I've tried a *lot* of AI tools, and for me @stitchbygoogle continues to be the easiest way to get from idea --> design...and now, to interactive prototype.
Would love to hear what you think!
(And tell me what you think about the song in this video if you have sound on 😂)
this project stores millions of text chunks inside a video file (mp4)
then runs sub-second semantic search on it
- no vector DB, no servers
- uses 10x less RAM & storage
- no internet required
it's called Memvid and it just broke my brain
The power of 𝗠𝗖𝗣 in 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗥𝗔𝗚 Systems.
To make it clear, most of the RAG systems running in production today are to some extent Agentic. How the agentic topology is implemented depends on the use case.
If you are packing many data sources, most likely there is some agency present at least at the data source selection for retrieval stage.
This is how MCP enriches the evolution of your Agentic RAG systems in such case (𝘱𝘰𝘪𝘯𝘵 2.):
𝟭. Analysis of the user query: we pass the original user query to a LLM based Agent for analysis. This is where:
➡️ The original query can be rewritten, sometimes multiple times to create either a single or multiple queries to be passed down the pipeline.
➡️ The agent decides if additional data sources are required to answer the query.
𝟮. If additional data is required, the Retrieval step is triggered. We could tap into variety of data types, few examples:
➡️ Real time user data.
➡️ Internal documents that a user might be interested in.
➡️ Data available on the web.
➡️ …
𝗧𝗵𝗶𝘀 𝗶𝘀 𝘄𝗵𝗲𝗿𝗲 𝗠𝗖𝗣 𝗰𝗼𝗺𝗲𝘀 𝗶𝗻:
✅ Each data domain can manage their own MCP Servers. Exposing specific rules of how the data should be used.
✅ Security and compliance can be ensured on the Servel level for each domain.
✅ New data domains can be easily added to the MCP server pool in a standardised way with no Agent rewrite needed enabling decoupled evolution of the system in terms of 𝗣𝗿𝗼𝗰𝗲𝗱𝘂𝗿𝗮𝗹, 𝗘𝗽𝗶𝘀𝗼𝗱𝗶𝗰 𝗮𝗻𝗱 𝗦𝗲𝗺𝗮𝗻𝘁𝗶𝗰 𝗠𝗲𝗺𝗼𝗿𝘆.
✅ Platform builders can expose their data in a standardised way to external consumers. Enabling easy access to data on the web.
✅ AI Engineers can continue to focus on the topology of the Agent.
𝟯. If there is no need for additional data, we try to compose the answer (or multiple answers or a set of actions) straight via an LLM.
𝟰. The answer gets analyzed, summarized and evaluated for correctness and relevance:
➡️ If the Agent decides that the answer is good enough, it gets returned to the user.
➡️ If the Agent decides that the answer needs improvement, we try to rewrite the user query and repeat the generation loop.
Are you using MCP in your Agentic RAG systems? Let me know about your experience in the comment section 👇
#LLM #AI #MachineLearning