🚀 Exciting News from AI4Finance Foundation! 🚀
As Founder and President, I'm thrilled to announce the official launch of our latest venture—the FinRobot Project! Our Github Repo: https://t.co/zqyHu7Wea9
#AI4Finance#FinRobot#OpenSource
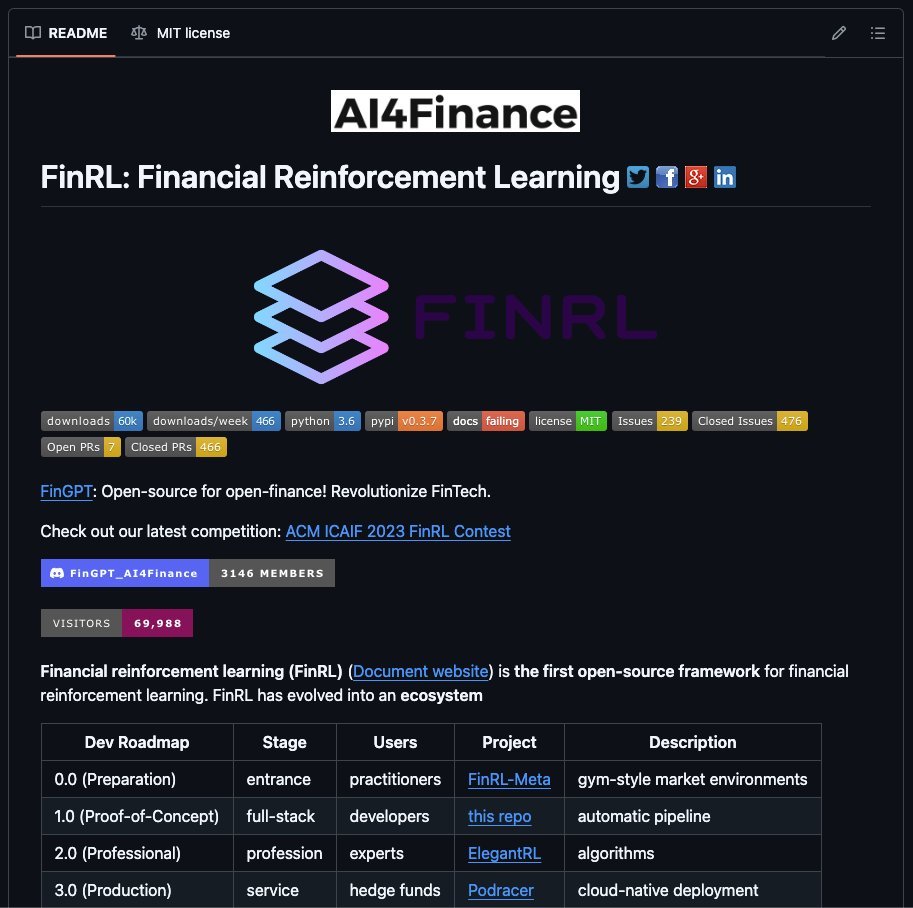
🚨 Holy shit.. someone just open sourced what quant funds pay $300K+ per year to build. Full RL trading infrastructure from research to live deployment.
It's called FinRL.
Most retail algo traders hit the same wall: you can find tutorials on backtesting or RL theory, but never a framework that covers the entire pipeline from research to live trading. FinRL does.
Here's what it actually does:
→ Gym-style market environments for stocks, crypto, forex, and portfolio optimization — same interface as training a game-playing AI
→ Full train-test-trade pipeline: train on historical data, validate out-of-sample, deploy to paper or live trading
→ Multiple RL algorithms out of the box: DQN, PPO, SAC, TD3, A2C, swap without rewriting your environment
→ Connects to real data sources: Yahoo Finance, Alpaca, Binance, and others
→ Paper trading support so you validate strategies without real capital at risk
→ Portfolio optimization environments for multi-asset allocation strategies
Here's how it works:
You define a trading environment: which stocks, what time period, what transaction costs. The RL agent trains on that environment using historical price data, learning to maximize cumulative reward (your returns minus costs). Test it on unseen data. If it holds up, move to paper trading.
Here's the wildest part:
This isn't a weekend project. The AI4Finance Foundation has published peer-reviewed papers using FinRL. 3,200 forks. 228 contributors. Last commit: 3 days ago.
The research-grade infrastructure for reinforcement learning in finance is free. The only remaining moat for institutional quants is proprietary data and actual capital.
Free. MIT license. 14.3K stars.
This paper is a big deal!
It's well known that RL works great for math and code.
But RL for training agents is a different story.
The default approach to training LLM agents today is based on methods like ReAct-style reasoning loops, human-designed workflows, and fixed tool-calling patterns. The issue is that these methods treat the environment as passive rather than interactive.
But in the real world, agents must make sequential decisions, maintain memory across turns, and adapt to stochastic environmental feedback.
That's fundamentally an RL problem.
This new research introduces Agent-R1, a framework for training LLM agents with end-to-end reinforcement learning across multi-turn interactions.
As agents move from predefined workflows to autonomous interaction, end-to-end RL becomes the natural training paradigm. Agent-R1 provides a modular foundation for scaling RL to complex, tool-using LLM agents.
Standard RL for LLMs assumes deterministic state transitions. You generate a token, append it to the sequence, done. But agents trigger external tools with uncertain outcomes. The environment responds unpredictably. State transitions become stochastic.
Therefore, the researchers extend the Markov Decision Process framework to capture this. State space expands to include full interaction history and environmental feedback. Actions can trigger external tools, not just generate text. Rewards become dense, with process rewards for intermediate steps alongside final outcome rewards.
Two core mechanisms make this work. An Action Mask distinguishes agent-generated tokens from environmental feedback, ensuring credit assignment targets only the agent's actual decisions. A ToolEnv module manages the interaction loop, handling state transitions and reward calculation when tools are invoked.
On multi-hop question answering, RL-trained agents dramatically outperform baselines. The weakest RL algorithm (REINFORCE++) still beat naive RAG by 2.5x on average EM. GRPO achieved 0.3877 average EM compared to 0.1328 for RAG.
Ablation results also confirm that the design matters. Disabling the advantage mask dropped PPO performance from 0.3719 to 0.3136. Disabling the loss mask caused further degradation to 0.3022. Precise credit assignment is essential for multi-turn learning.
Paper: https://t.co/BrIBT3AAxC
Learn to build effective AI agents in my academy: https://t.co/JBU5beIoD0
Updated the AI4Finance Foundation Executive Overview.
The deck summarizes our open-source work in financial AI — including FinGPT, FinRL, and FinRobot — along with current ecosystem metrics (30M+ views, 200K MAU, 43K+ stars).
PDF: https://t.co/i2caRPSegi
Slides from the AI4Finance Foundation deck:
1️⃣ Intro page — global nonprofit focused on AI + finance
2️⃣ About us — 501(c)(3) status, trademarks, mission, and impact
3️⃣ Our approach — Foundation / FinTech / Fund structure
4️⃣ Project impact — growth of FinGPT, FinRL, and FinRobot
🚨Check out my work with the AI team at @jpmorgan !!! 📜 "Grounding LLM Reasoning with Knowledge Graphs" explores the intersection of Knowledge Graphs and Reasoning strategies with LLMs which helps boosting answers in domain specific questions (1/4)
🧵👇
We’re thrilled to announce that Mostapha B. has joined us as an AI researcher, bringing his groundbreaking work to our community. Mostapha’s latest research: FinRL-DeepSeek: LLM-Infused Risk-Sensitive Reinforcement Learning for Trading Agents
https://t.co/7xlBrfnvs1
#AI4Finance
Excited to start my 7th semester teaching Columbia’s STAT GR5398 course! 🎉 'Teaching Without Teach’ philosophy-empowering students to take the lead in real-world AI projects. All materials are open-source for everyone to learn & contribute! #AI#Education#OpenSource
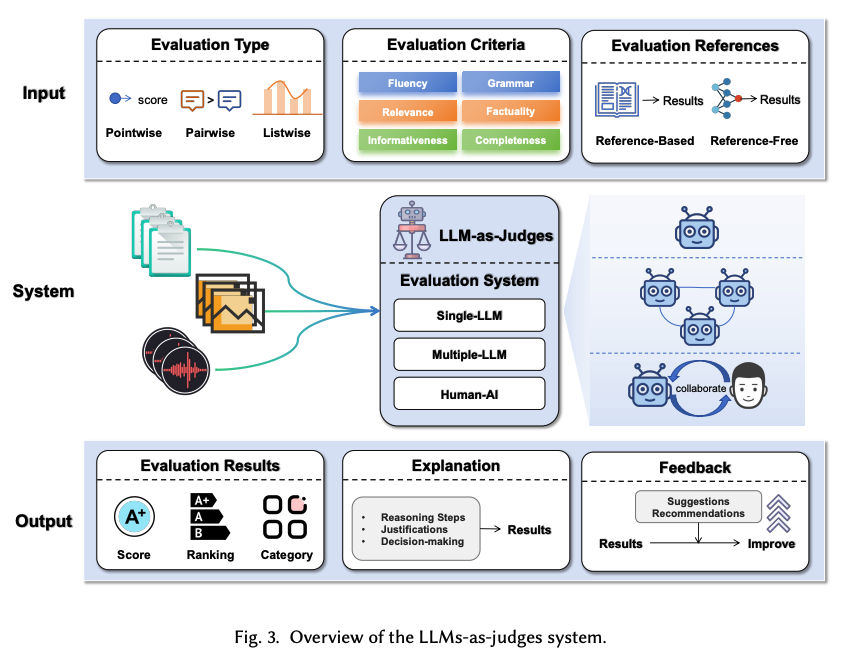
A Survey on LLMs-as-Judges
Presents a comprehensive survey of the LLMs-as-judges paradigm from five key perspectives: Functionality, Methodology, Applications, Meta-evaluation, and Limitations.
Gemini 2.0 real-time AI is absolutely wild!
Watch how I use it as an AI research assistant by sharing my screen and asking it about an AI paper.
10x your paper reading skills or just let Gemini summarize key points.
What an incredible time to be alive!




























![QFinancePapers's tweet photo. FinRL-X: An AI-Native Modular Infrastructure for Quantitative Trading
Hongyang Yang, Boyu Zhang, Yang She, Xinyu Liao, Xiaoli Zhang
https://t.co/j3Za0QV0Zh [𝚚-𝚏𝚒𝚗.𝚃𝚁 𝚌𝚜.𝙻𝙶 𝚚-𝚏𝚒𝚗.𝙲𝙿] https://t.co/x3FDp4agzn](https://pbs.twimg.com/media/HEKQTKSaIAMnWxa.png)