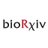Our preprint is out! We hacked the @nanopore sequencer to read amino acids and PTMs along protein strands. This opens up the possibility for barcode sequencing at the protein level for highly multiplexed assays, PTM monitoring, and protein identification!
https://t.co/hVdNFa7ti4
Yesterday we released our preprint showing how a @nanopore array morphs into a protein sequencer... Achieving LONG reads (hundreds of amino acids) and the capability to re-read individual molecules multiple times, all thanks to a protein-processive molecular motor.
Great news from COPO!
Reliably brokering sample #metadata is an essential step of the reference #genome production workflow.
Congratulations on this impressive milestone 🎉
@BioGenEurope@EarlhamInst
Structural #genome annotation with BRAKER & TSEBRA - workshop will take place on the 21st Nov. from 9am to 3pm, registration is free but capacity is limited to 35 participants - so hurry! https://t.co/8AjrUTPyyB #training#bioinformatics#genomics#biodiversity@erga_biodiv ERGA
Thrilled that our work “compleasm: a faster and more accurate reimplementation of BUSCO” is now published in Bioinformatics! 🎉 Huge thanks to our amazing lab @lh3lh3 and to the reviewers’ valuable comments. 🙏 Journal paper: https://t.co/nmbyvvJq0c
In a post #AlphaFold world, we can use protein structures in ways we never could before. Can we build phylogenies with them? Are they any good? Yes! Foldtree (https://t.co/GarG48Y21B) surpasses traditional sequence-based methods, even for closely related proteins.👇
Interested in #phylogenetics using whole #genome/#transcriptome/#proteome data? @C__Hahn and I are very happy to share phylociraptor with you: It facilitates explorative and reproducible phylogenomic analyses of thousands of genes and genomes. Preprint: https://t.co/IX2UpBzYZ8
Interested in #phylogenetics using whole #genome/#transcriptome/#proteome data? @C__Hahn and I are very happy to share phylociraptor with you: It facilitates explorative and reproducible phylogenomic analyses of thousands of genes and genomes. Preprint: https://t.co/IX2UpBzYZ8
Our CARD pilot paper with @KimberleyBill10@cornelisblauw @BenedictPaten and many others is online! We establish a wet + dry lab protocol for single nanopore flow cell sequencing, which generates state-of-the-art SNP and SV calls + assemblies. https://t.co/0P7utXOtx6
Snakemake has many technical benefits over Nextflow for writing bioinformatics workflows.
But there is no platform that supports the language.
Today we are releasing native support for Snakemake on the LatchBio Cloud.
https://t.co/ZC8NVILOIB
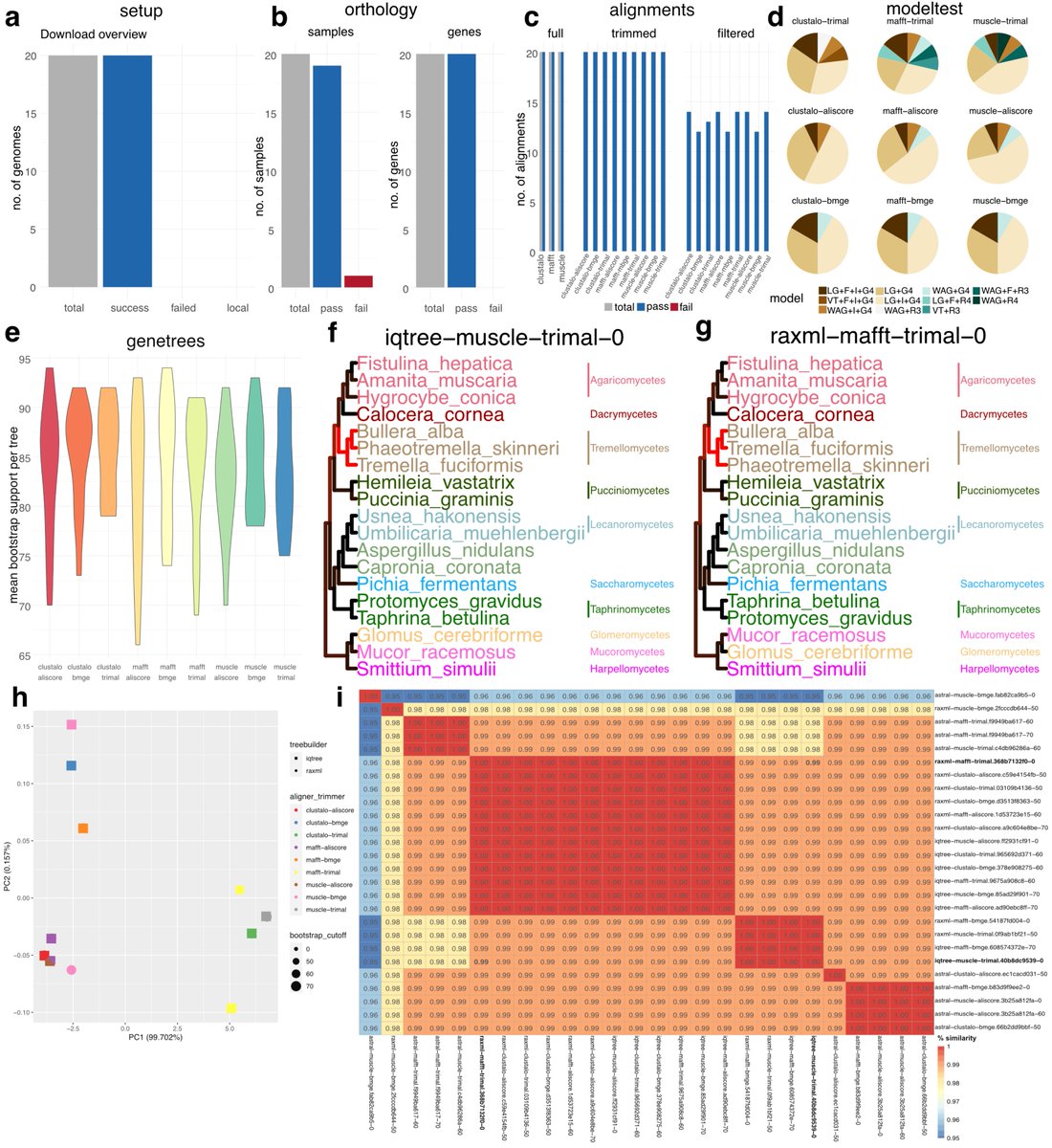
How do you stress the importance of replicates to improve the accuracy of #eDNA sampling?
Use pizza of course 🍕🍕🍕
A great talk by @N_P_Griffiths#fishimp2023