Life moves fast. Versions of you come and go without saying goodbye.
@gracezhhang and I built Time Capsule.
Write a letter to your future self.
Attach memories.
Open it after one year.
Made for the @contra x #FigmaMakeathon. Built with @Figma Make.
Try it in link below 👇
Excited to be part of the team at @open_ledger! We're transforming accounting by making financial data smarter, seamless, and more connected than ever before
I’m thrilled to announce the public launch of my new company, @open_ledger, alongside our $3 million pre-seed funding led by @KindredVentures and @blank_vc more below👇🏿
I’m thrilled to announce the public launch of my new company, @open_ledger, alongside our $3 million pre-seed funding led by @KindredVentures and @blank_vc more below👇🏿
any @_buildspace or other peeps interested in a Q1 sprint / mastermind / hackathon?
- limited to 500 people
- weekly mastermind (groups of 4 or 5)
- prizes at the end?
- suggestions?
comment below if you're interested and if you have any ideas
tags / RTs welcome for reach :)
We’re rolling out an early version of canvas—a new way to work with ChatGPT on writing & coding projects that go beyond simple chat.
Starting today, Plus & Team users can try it by selecting “GPT-4o with canvas” in the model picker. https://t.co/GoGZiRzCsB
@Jason We’re building Morpheus, an AI game dev copilot that helps you rapid prototype your dream games
Our goal is to 10x game creation:
- Turn ideas into a full game
- Nail the core gameplay loop
- Automate coding
- Create concept art
You direct, we build. @MorpheusAIGames
📣 Introducing Llama 3.2: Lightweight models for edge devices, vision models and more!
What’s new?
• Llama 3.2 1B & 3B models deliver state-of-the-art capabilities for their class for several on-device use cases — with support for @Arm, @MediaTek & @Qualcomm on day one.
• Llama 3.2 11B & 90B vision models deliver performance competitive with leading closed models — and can be used as drop-in replacements for Llama 3.1 8B & 70B.
• New Llama Guard models to support multimodal use cases and edge deployments.
• The first official distro of Llama Stack simplifies and supercharges the way developers & enterprises can build around Llama to support agentic applications and more.
Details in the full announcement ➡️ https://t.co/1bnEeLY9qf
Download Llama 3.2 models ➡️ https://t.co/DZoTQvESbG
These models are available to download now directly from Meta and @HuggingFace — and will be available across offerings from 25+ partners that are rolling out starting today, including @accenture, @awscloud, @AMD, @azure, @Databricks, @Dell, @Deloitte, @FireworksAI_HQ, @GoogleCloud, @GroqInc, @IBMwatsonx, @Infosys, @Intel, @kaggle, @NVIDIA, @OracleCloud, @PwC, @scale_AI, @snowflakeDB, @togethercompute and more.
With Llama 3.2 we’re making it possible to run Llama in even more places, with even more flexible capabilities. We’ve said it before and we’ll say it again: open source AI is how we ensure that these innovations reflect the global community they’re built for and benefit everyone. We’re continuing our drive to make open source the standard with Llama 3.2.
Here’s a sneak peek at Meta’s new small form glasses, called Orion. They’re fully standalone and feature eye, hand, and even neural tracking. Can’t wait to try these!
Meta presents Imagine yourself
Tuning-Free Personalized Image Generation
paper page: https://t.co/WVTywILWfH
Diffusion models have demonstrated remarkable efficacy across various image-to-image tasks. In this research, we introduce Imagine yourself, a state-of-the-art model designed for personalized image generation. Unlike conventional tuning-based personalization techniques, Imagine yourself operates as a tuning-free model, enabling all users to leverage a shared framework without individualized adjustments. Moreover, previous work met challenges balancing identity preservation, following complex prompts and preserving good visual quality, resulting in models having strong copy-paste effect of the reference images. Thus, they can hardly generate images following prompts that require significant changes to the reference image, \eg, changing facial expression, head and body poses, and the diversity of the generated images is low. To address these limitations, our proposed method introduces 1) a new synthetic paired data generation mechanism to encourage image diversity, 2) a fully parallel attention architecture with three text encoders and a fully trainable vision encoder to improve the text faithfulness, and 3) a novel coarse-to-fine multi-stage finetuning methodology that gradually pushes the boundary of visual quality. Our study demonstrates that Imagine yourself surpasses the state-of-the-art personalization model, exhibiting superior capabilities in identity preservation, visual quality, and text alignment. This model establishes a robust foundation for various personalization applications. Human evaluation results validate the model's SOTA superiority across all aspects (identity preservation, text faithfulness, and visual appeal) compared to the previous personalization models.
ML Grind | Day 5:
- math day! collecting those xp points🫡
- studied math preliminaries for ML (sets, matrices, calculus)
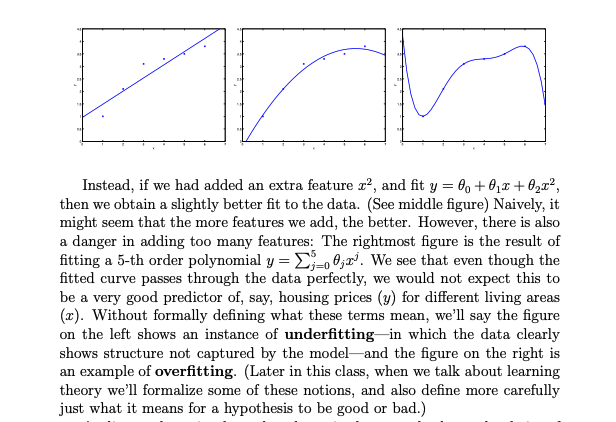
- reviewed section 1 of the cs229 lecture notes
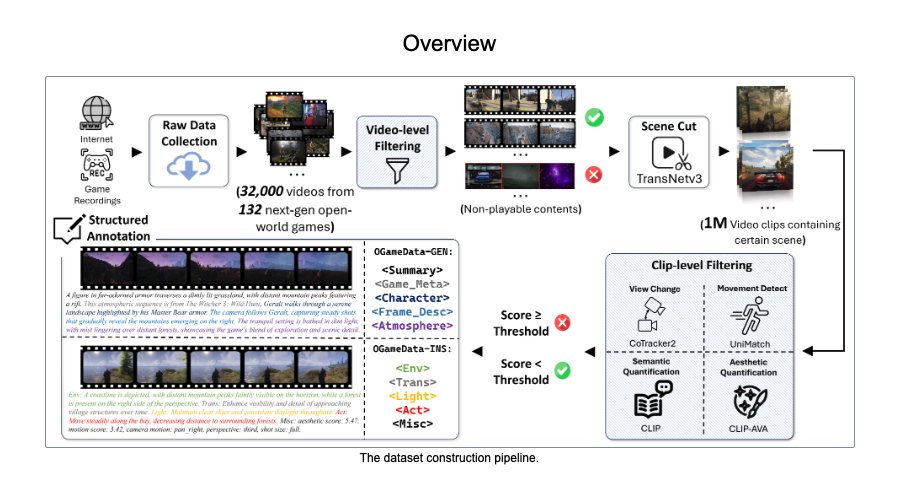
- read the overview of GameGen-O (patiently waiting for the arxiv drop)
Finally back to the fun stuff! ML grind continues🌱
Updated study plan:
+ review ML math concepts (math academy)
> basics of ML (finish stanford's CS229)
> read cool papers
+ work to better optimize my time to learn ML consistently + school + projects
@MayorKingAI Honestly I thought the DOOM engine was cool but this is on another level with the visuals, assets, and characters. Excited to see where they take this