‼️Position: AI coding agent research needs recalibration.
We've heavily optimized for solo autonomy, and far less for designing agents that empower the humans using them.
It’s time to build human-centered coding agents. 🧵
found a really good blog digging into how @AnthropicAI identifies and mitigates reward hacking during RL training. recommended by @sheriyuo. my notes:
Identifying Reward Hacking
1. frontier model reads training trajectories, summarizes them, flags hacky behavior. Running on hundreds of thousands of trajectories per run by 4.6.
2. 3 stress-test sets stay live during training: problems where past models hacked, impossible tasks that force failure (hacking usually shows up after honest attempts fail), and hack-frequency tracking on the training distribution itself.
3. hidden tests: hold out tests the model never sees. hack rate = solutions that pass visible tests but fail hidden ones. catches verifier overfitting cleanly.
4. agentic code behavior scores: 6 dim rubric on trajectories. instruction following, safety, verification, efficiency, adaptability, honesty.
5. impossible gui tasks for over-eagerness: container rigged so the user's request is actually impossible. Right move: ask the user. hacky move: fabricate and proceed.
6. prompt-injection differentials: run the eval with anti-hack and pro-hack prompts. the gap tells you hacking propensity vs just bad instruction-following.
7. white-box SAE monitoring: find features that fire on reward hacking, sample trajectories during training, flag anomalous activations. diagnostic only, not a training signal.
8. human reviewers alongside the automated stack. Their findings feed back into better classifiers over time.
Mitigating Reward Hacking
1. environment redesign: kill hackable surface area, tighten specs to match reward signals. the spec-reward gap is what hacks exploit.
2. reward signal hardening: rewards modified to be harder to game. specifics not disclosed.
3. instruction-following as a lever: once it's solid, a simple "don't hack" preamble drops hack rate sharply. size of the drop is itself a useful signal.
4. pre-exposure prompting: tell the model during training that the hacky behavior is expected. breaks the link between learning a specific hack and generalizing to broader misalignment.
5. stress tests run throughout training, not at the end. hacks get caught inside the run instead of after the model's already shaped around them.
6. disclosure gap worth flagging: detection is documented in depth, mitigation stays high-level. What they did, rarely how, no ablations.
Self-play led to superhuman Go performance, why hasn’t it for LLMs?
In practice, long run self-play plateaus like RL. We study why this happens, and build a self-play algorithm that scales better. It solves as many problems with a 7B model as the pass@4 of a model 100x bigger.
What if AI learned physics the way Newton did – by experiencing it?
We built Sim2Reason: train LLMs inside virtual worlds governed by real physics laws, zero human annotation.
Result: +5–10% improvement on International Physics Olympiad, zero-shot. 🧵
As AI agents accelerate coding, what is the future of software engineering? Some trends are clear, such as the Product Management Bottleneck, referring to the idea that we are more constrained by deciding what to build rather than the actual building. But many implications, like AI’s impact on the job market, how software teams will be organized, and more, are still being sorted out.
The theme of our AI Developer Conference on April 28-29 in San Francisco is The Future of Software Engineering. I look forward to speaking about this topic there, hearing from other speakers on this theme, and chatting with attendees about it. We’re shaping the future, and I hope you will join me there!
It is currently trendy in some technology and policy circles to forecast massive job losses due to AI. Even if they have not yet materialized, these losses certainly must be just over the horizon! I have a contrarian view that the AI jobpocalypse — the notion that AI will lead to massive unemployment, perhaps even rioting in the streets — won’t be nearly as bad as dire forecasts by pundits, especially pundits who are trying to paint a picture of how powerful their AI technology is.
Among professions, AI is accelerating software engineering most, given the rise of coding agents. According to a new report by Citadel Research, software engineering job postings are rising rapidly. So if software engineering is a harbinger of the impact AI will have on other professions, this expansion of software engineering jobs is encouraging.
Yes, fresh college graduates are having a hard time finding jobs. And yes, there have been layoffs that CEOs have attributed to AI, even if a large fraction of this was “AI washing,” where businesses choose to attribute layoffs to AI, even though AI has not changed their internal operations much yet. And yes, there is a subset of job roles, such as call center operator, that are more heavily impacted. Many people are feeling significant job insecurity, and I feel for everyone struggling with employment, whether or not the cause is AI-related. And many other factors, such as over-hiring during the pandemic and high interest rates, have contributed to the slowdown in the labor market, and the notion that AI is leading to unemployment is oversimplified.
In software engineering, I see a lot of exciting work ahead to adapt our workflows. It is already clear that: (i) As AI makes coding easier, a lot more people will be doing it. (ii) Writing code by hand and even reading (generated) code is not that important, because we can ask an LLM about the code and operate at a higher level than the raw syntax (although how high we can or should go is rapidly changing). (iii) There will be a lot more custom applications, because now it’s economical to write software for smaller and smaller audiences. (iv) Deciding what to build, more than the actual building, is becoming a bottleneck. (v) The cost of paying down technical debt is decreasing (since AI can refactor for you).
At the same time, there are also a lot of open questions for our profession, such as:
- In the future, what will be the key skills of a senior software engineer? And for junior levels, what should be the new Computer Science curriculum?
- If everyone can build features, what skills, strategies, or resources create competitive advantage for individuals and for businesses?
- What are the new building blocks (libraries, SDKs, etc.) of software? How do we organize coding agents to create software?
- What should a software team look like? For example, how many engineers, product managers, designers, and so on. What tooling do we need to manage their workflow?
- How do AI agents change the workflow of machine learning engineers and data scientists? For example, how can we use agents to accelerate exploring data, identifying hypotheses, and testing them?
I’m excited to explore these and other questions about the future of software engineering at AI Dev. I expect this to be an exciting event. Please join us!
[Original text: The Batch newsletter.]
https://t.co/i4bQevDG4i
Apple Research just published something really interesting about post-training of coding models.
You don't need a better teacher. You don't need a verifier. You don't need RL.
A model can just… train on its own outputs. And get dramatically better.
Simple Self-Distillation (SSD): sample solutions from your model, don't filter them for correctness at all, fine-tune on the raw outputs. That's it.
Qwen3-30B-Instruct: 42.4% → 55.3% pass@1 on LiveCodeBench. +30% relative. On hard problems specifically, pass@5 goes from 31.1% → 54.1%.
Works across Qwen and Llama, at 4B, 8B, and 30B. One sample per prompt is enough. No execution environment. No reward model. No labels.
SSD sidesteps this by reshaping distributions in a context-dependent way — suppressing distractors at locks while keeping diversity alive at forks. The capability was already in the model. Fixed decoding just couldn't access it.
The implication: a lot of coding models are underperforming their own weights. Post-training on self-generated data isn't just a cheap trick — it's recovering latent capacity that greedy decoding leaves on the table.
paper: https://t.co/YsT3OSmbq3
code: https://t.co/OX58FzDVqy
URAG: A Benchmark for Uncertainty Quantification in Retrieval-Augmented Large Language Models
Vinh Nguyen, Cuong Dang, Jiahao Zhang, Hoa Tran, Minh Tran, Trinh Chau, Thai Le, Lu Cheng, Suhang Wang
https://t.co/knkbebuJcN [𝚌𝚜.𝙲𝙻 𝚌𝚜.𝙰𝙸 𝚌𝚜.𝙸𝚁]
Thrilled to see our paper URAG: Benchmarking Retrieval-Augmented Generation via Uncertainty Quantification featured by Machine Brief! 🚀
Huge thanks to Machine Brief for the spotlight! 🙌
https://t.co/2YTrjwjVyj
If you work in AI you have to watch this talk by Moritz Hardt on the science of benchmarking. It talks about a lot of unexpected properties of benchmarks that I don't think most people are aware of; e.g. benchmarks can be incredibly noisy/imprecise and still be useful. 🔗⬇️
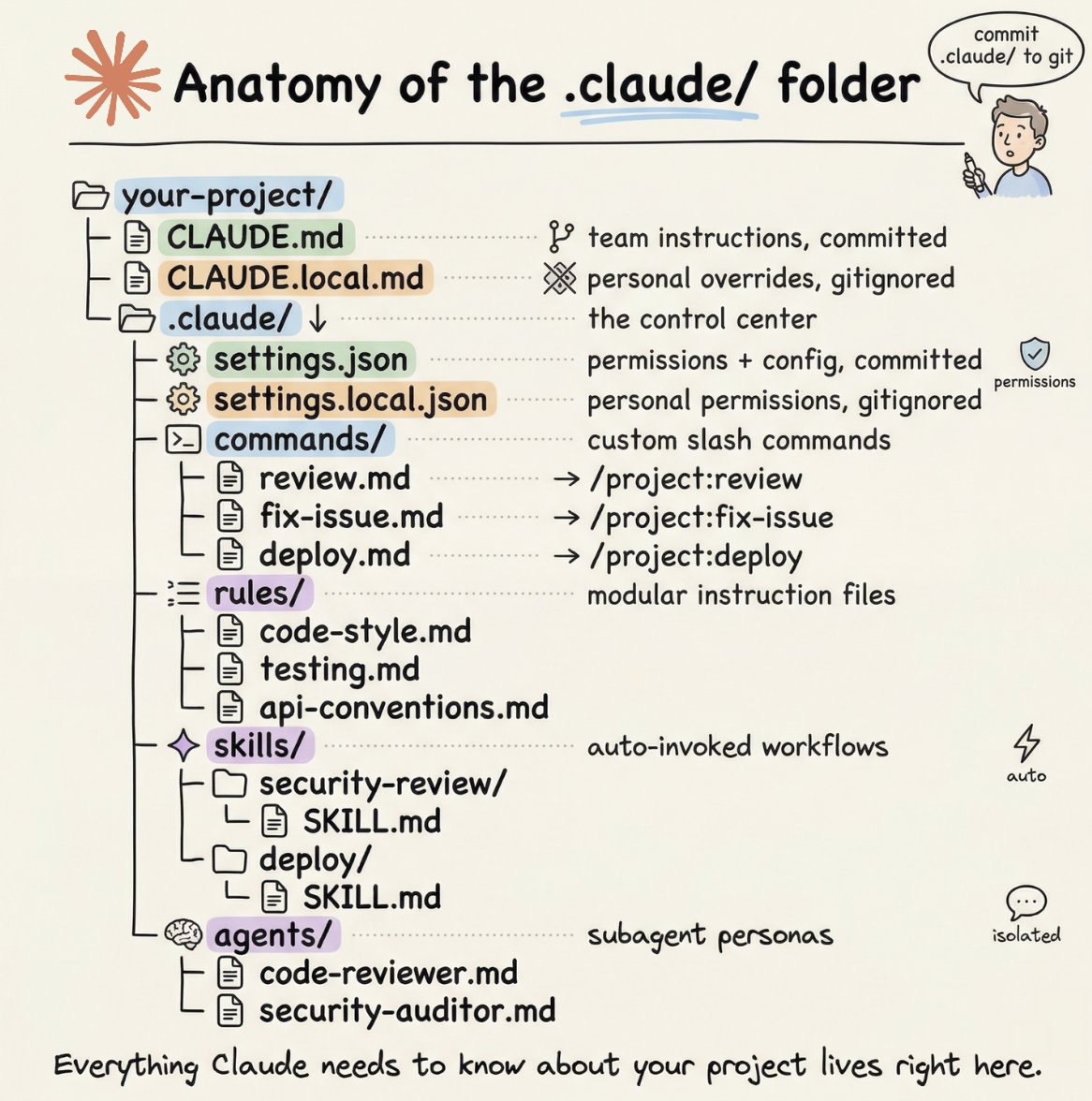
How to setup your Claude code project?
TL;DR
Most developers skip the setup and just start prompting. That's the mistake.
A proper Claude Code project lives inside a .𝗰𝗹𝗮𝘂𝗱𝗲/ folder. Start with 𝗖𝗟𝗔𝗨𝗗𝗘.𝗺𝗱 as Claude's instruction manual. Split it into a 𝗿𝘂𝗹𝗲𝘀/ folder as it grows. Add 𝗰𝗼𝗺𝗺𝗮𝗻𝗱𝘀/ for repeatable workflows, 𝘀𝗸𝗶𝗹𝗹𝘀/ for context-triggered automation, and 𝗮𝗴𝗲𝗻𝘁𝘀/ for isolated subagents. Lock down permissions in 𝘀𝗲𝘁𝘁𝗶𝗻𝗴𝘀.𝗷𝘀𝗼𝗻.
There are two .𝗰𝗹𝗮𝘂𝗱𝗲/ folders: one committed with your repo, one global at ~/.𝗰𝗹𝗮𝘂𝗱𝗲/ for personal preferences and auto-memory across projects.
The .𝗰𝗹𝗮𝘂𝗱𝗲/ folder is infrastructure. Treat it like one.
The article below is a complete guide to 𝗖𝗟𝗔𝗨𝗗𝗘.𝗺𝗱, custom commands, skills, agents, and permissions, and how to set them up properly.
🌍 In short, URAG provides a foundation for studying trustworthy RAG, making it easier to analyze when retrieval helps, when it hurts, and when it creates dangerous overconfidence. Feel free to play around with our codebase at https://t.co/MOe0L4Qbrb
📢I'm thrilled to share my paper: URAG — a benchmark for uncertainty in RAG. Instead of measuring only accuracy, URAG asks: when should RAG be uncertain? Using MCQA + conformal prediction, we study uncertainty across methods, domains, prompts, and noisy retrieval. 🔬📷 ⚠️
URAG: A Benchmark for Uncertainty Quantification in Retrieval-Augmented Large Language Models
Introduces a benchmark to evaluate both accuracy and uncertainty of RAG systems using conformal prediction across several domains.
📝 https://t.co/7KMEnVkY8K
👨🏽💻 https://t.co/R8QW9U5zIB
🔍 Some methods rely less on retrieval than others. The paper finds RAPTOR and REPLUG lean more on the model’s own parametric knowledge, while HyDE and REPLUG can increase certainty when the LLM already knows the answer.
🛡️ RAG systems are vulnerable to belief manipulation. In wrong-aware prompting, misleading confidence cues consistently reduce accuracy and increase uncertainty, suggesting a prompt-injection-like failure mode.
🧩 No single RAG method is universally reliable. Performance depends on the domain, prompt setting, retrieval quality, and how much the LLM already knows.
🚨 Retrieval can amplify overconfident errors. More retrieval, misleading confidence cues, and weak knowledge settings can all increase confident hallucinations rather than reduce them.



































![HEI's tweet photo. URAG: A Benchmark for Uncertainty Quantification in Retrieval-Augmented Large Language Models
Vinh Nguyen, Cuong Dang, Jiahao Zhang, Hoa Tran, Minh Tran, Trinh Chau, Thai Le, Lu Cheng, Suhang Wang
https://t.co/knkbebuJcN [𝚌𝚜.𝙲𝙻 𝚌𝚜.𝙰𝙸 𝚌𝚜.𝙸𝚁] https://t.co/CEceIVz27a](https://pbs.twimg.com/media/HEGYvPSaEAE1WdQ.png)