🎁Congrats to KayTrim for winning the @Cellhasher Kit Giveaway!
Please email me at [email protected]
This Giveaway was part of the video "Use your PHONE for Ai and Get Paid in Crypto!" https://t.co/RalGl45zpu
@Acurast
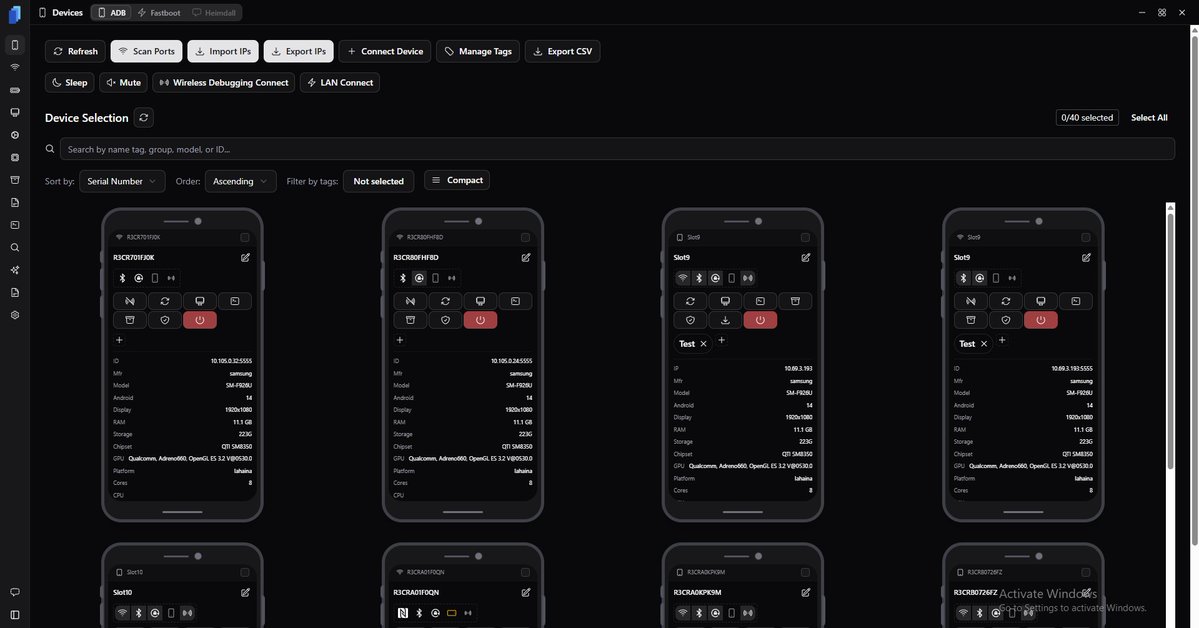
Here's an Up to date Breakdown on @Cellhasher with @YourFriendAndy
Code: ANDYSFRIENDS at checkout for DIY!
Code: ANDY at checkout for Pre-Built Units!
Watch it here:
https://t.co/p3HCR9d7cm
how much abstract xp do you get for rank #1?
jokes aside (it's not a joke @0xCygaar pls give xp), super polished, great sfx and vibe curation esp for a browser game
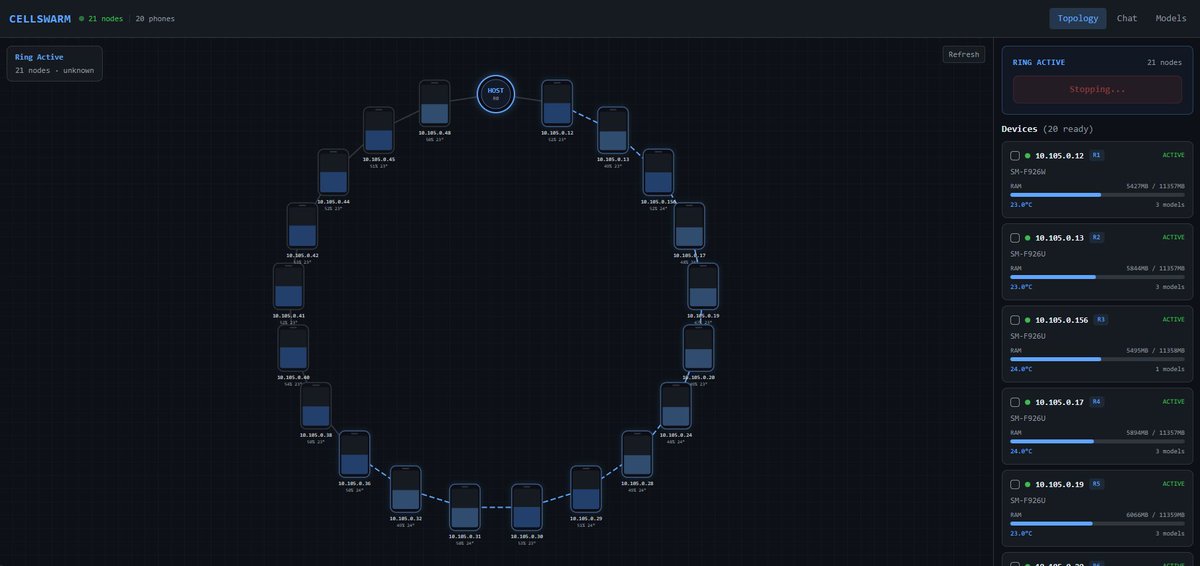
Wait till everyone finds out with @Cellhasher you can deploy your 20phone cluster into an full R&D Lab with various different agents,
Research,
Security,
Audit,
Routing,
Senior Engineer,
Vision,
func-call,
dev-01 developer
dev-02 developer
dev-03 developer
gateway developer1
guard developer
senses developer
reviewer
meta_engineer
research
devops
data-analyst
multilingual
writer
scout
reasoner
nanbeige
hot-spareguard
Imagine what happens when you use 20 phones all cooking at 10-20 token/s running 24/7 working for you
Here is a taste of one Android Phone, a simple deploy of QWEN3.5 running on a 5 year old Android. @Cellhasher
Here are Android AI @Cellhasher Qwen3.5 + DeepSeek 33B benchmarks.
TLDR: its actually worth it if you have old androids for the cheap less than 5w most of these phones operate at. Especially as agents become more deployable and 24/7 hands off or sit and forget. AI model companies will eventually start fine tuning even further to get models into more of a MOE style but tuned directly to the use with Routers, routing each request. Cellhasher is working on this as well. As demand for compute and energy continues, eventually companies will not keep making bigger models and not Company can keep pace with the big ones, they will focus on small local models for retail.
We will start with the 5 year old Chipset and Bring you up to speed with some wild results on a newest-chipset.
Device: Snapdragon 888 (5 years old chip)
CPU only
Non-root (28 GB/s memory cap)
Rooted devices (56 GB/s) scale ~1.8–1.9x.
(using the fastest 4 cores actually outperforms using all 8 cores)
Qwen3.5 - 0.8B
CPU (4 big cores):
12.54–13.01 tok/s
Rooted (1.8–1.9x): 22.6–24.7 tok/s
Vulkan GPU (NGL=24):
1.60–1.78 tok/s (7–8x slower)
Qwen3.5 - 2B
CPU (4 big cores):
9.15–9.36 tok/s
Rooted: 16.5–17.8 tok/s
Vulkan GPU (NGL=24):
0.78–0.86 tok/s (11–12x slower)
Large Models (Non-Root) #p stands for Number of Phones in a parallel pipeline ring made by Cellhasher Swarm AI
DeepSeek 33B → 5.89 tok/s (Best was 7.8 tok/s) average is still 5.89 tok/s
(12p, d=16, 81% accept)
Qwen3.5-35B-A3B → 3.75 tok/s (best was 5.1 tok/s)
(3p, d=8, 71.5% accept)
Qwen3.5-32B (Coder) → 2.85 tok/s (best 4.8 tok/s)
(7p, same-family draft)
Rooted Estimate (56 GB/s)
DeepSeek 33B → ~10–11 tok/s
Qwen3.5-35B → ~6.5–7 tok/s
Qwen3.5-32B → ~5–5.5 tok/s
Snapdragon 8 Elite Gen 5 plus + 24gb RAM (Android Phone)
~75–85 GB/s memory bandwidth
INT4/INT8 NPU usable
Well-tuned pipeline
Qwen3.5 - 0.8B Model
CPU only: 30–45 tok/s
CPU + NPU: 70–100+ tok/s
Qwen3.5 - 2B Model
CPU only: 18–25 tok/s
CPU + NPU: 40–60 tok/s
DeepSeek 33B
CPU only: 15–20 tok/s
CPU + NPU (blended): 20–28 tok/s
(30 tok/s possible with ideal tuning)
Qwen3.5-35B-A3B
CPU only: 11–15 tok/s
CPU + NPU: 16–22 tok/s
Qwen3.5-32B (Coder)
CPU only: 10–14 tok/s
CPU + NPU: 15–20 tok/s
(CPU+NPU is slightly tricky and prefill along with ring pipeline can determine alot, KV cache catching is something i haven't played around with yet)
33B class ~2.5��3.5x over Snapdragon 888
Small models see major NPU uplift
Memory bandwidth remains the limiter on large models
@Cellhasher has come along way driving inspo from @exolabs over the last few months although things needed to change in order to be correctly managed for android really none of the EXO features are now used, we have our own modification to llama.cpp that overs this ring pipelined parallelism for running LARGE models across however many phones it takes.
What's hard is sometimes less phones doesn't always compute to high tokes as some would think less hops will do the trick, in some cases it does other cases like Spec drafting sometimes it doesn't. Regardless Automously running agents 24/7 if i Can run a 80b model at 1-5tok/s on 5 year old Android hardware that runs at 5-15w depending on the amount of phones used, ill take it.
If you make the upgrade to the latest generations of phones you get to experience amazing breakthrough of NPU sync and bandwidth optimization that can get you that amazing 20-70 tok/s feel depending per model for every day use.
And now im thinking about taking the plunge into 20 of these new phones 20k for 160cores, and 480gb RAM i could possible run the latest and greats at maybe speeds of 10 tok/s.... who knows let me know if you want me to try!
(All Phones benchmarked on Ethernet as it offers the best latency over Wifi) (Wifi Still works just slower)
@lukewrightmain@danieldalen@claudeai Our software supports this, A few more updates for 1-2 click deploys will come in this week as-well! Fun times, Helping people who are just getting started.