LLM post-training used to mean fine-tuning to a downstream task
Robotics has been stuck in this setting, needing task-specific fine-tuning for best performance
π07 changes this: It works out of the box & outperforms fine-tuned specialists
Details: https://t.co/QbO3E4D3QN
LLM RL optimizes for sequential reasoning
We also optimize over the reasoning strategy, incl parallel trains of thought, aggregation of parallel traces, & sequential reasoning
This allows the model to better explore & allocate compute at test time
https://t.co/DkTSllkmvp
The most capable reasoning systems in AI scale inference compute along several axes: sequential compute to think longer, parallel compute to sample many independent attempts, and aggregative compute to synthesize prior traces into a new improved one. But during training, we only optimize how models use sequential compute. This creates a fundamental mismatch between how we ultimately deploy these systems and how we train them, leaving much of search and synthesis unoptimized.
We introduce SPIRAL, an RL framework for making all inference-compute primitives end-to-end learnable: models learn to coordinate sequential, parallel, and aggregative reasoning using only the reward of the final output. Work with @ifdita_hasan (co-lead), @michaelyli_ , @oshaikh13 , @yoonholeee , @DorsaSadigh , @chelseabfinn , @noahdgoodman 🧵
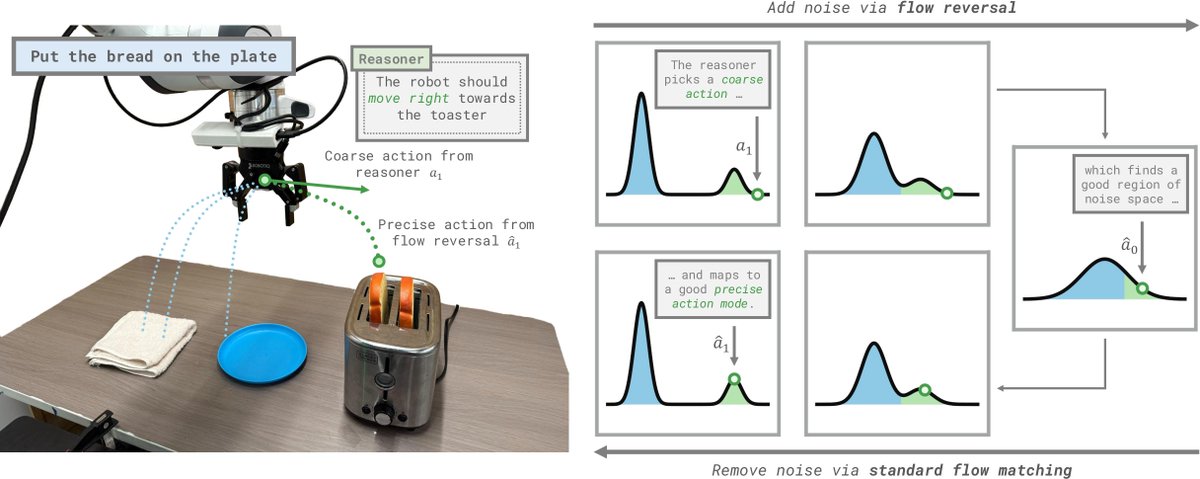
Can we translate a rough sense for what to do + VLA prior into successful behavior?
Flow reversal steering:
1) runs the VLA's flow ODE backwards to back out noise that's closest to coarse traj
2) runs flow forwards to get closest good behavior
Paper: https://t.co/FUDqDEpeJq
Generalist robot policies learn many useful skills, but struggle to select good behaviors for new tasks. To solve this, we introduce Flow Reversal Steering (FRS), a method to refine coarse semantic guidance into precise, in-distribution motions.
https://t.co/uCR6KmoDo8
1/N
How does test-time scaling impact robots?
We find that larger models, more thinking, and more context help significantly for some prompts but not others.
Like LLMs, we can also train a router to for a better performance/latency tradeoff!
Paper: https://t.co/HEjjCkrsen
Can robot foundation models collaborate with themself?
We finetune a VLA to be able to control any robot in a team.
- matches or outperforms training separate models or a single centralized model for all robots
- readily scales to large teams
Paper: https://t.co/yqdSOQ7ead
🤔 Can we train one VLA policy to control multi-robot teams without any explicit communication?
✨ Introducing CHORUS: a single policy for decentralized, multi-embodiment collaboration
🧵⬇️
We show that robots can learn high-level task semantics, such as sorting rules, skill composition, and rule-based ordering, directly from human demos.
This is useful because if your target task is a composition of the robot's existing skills, you could just collect human demos for it without collecting further robot data.
Introducing Ego-Pi: VLA fine-tuning for egocentric human and robot data, a collaboration between @Stanford and @Meta.
Website: https://t.co/dIF6n4QGy3
Paper: https://t.co/3GFk6KQw9P
1/6
Scaling RL to long horizons remains a major challenge.
Long-horizon Q-learning (LQL) prevents compounding bootstrapping errors by bounding the difference in value over long horizons.
It shows large gains over 1-step TD and n-step returns!
Paper: https://t.co/OTk3M6cz8p
In RL, what if we could learn from any experience from any policy in a way that is reliable and scalable?
This would be helpful in domains like robotics where new data is expensive.
We introduce Long-horizon Q-learning (LQL) to tackle this https://t.co/1Ckb5ZePyo.
Excited to share that I’ll join @NUSComputing as an Assistant Professor in 2027
🏛️ I’ll build LEMA Lab: https://t.co/qzKA7dpA00, study the principles of embodied intelligence, & empower every lab member to thrive
📢 Recruiting 3-6 PhD students in the next application cycles
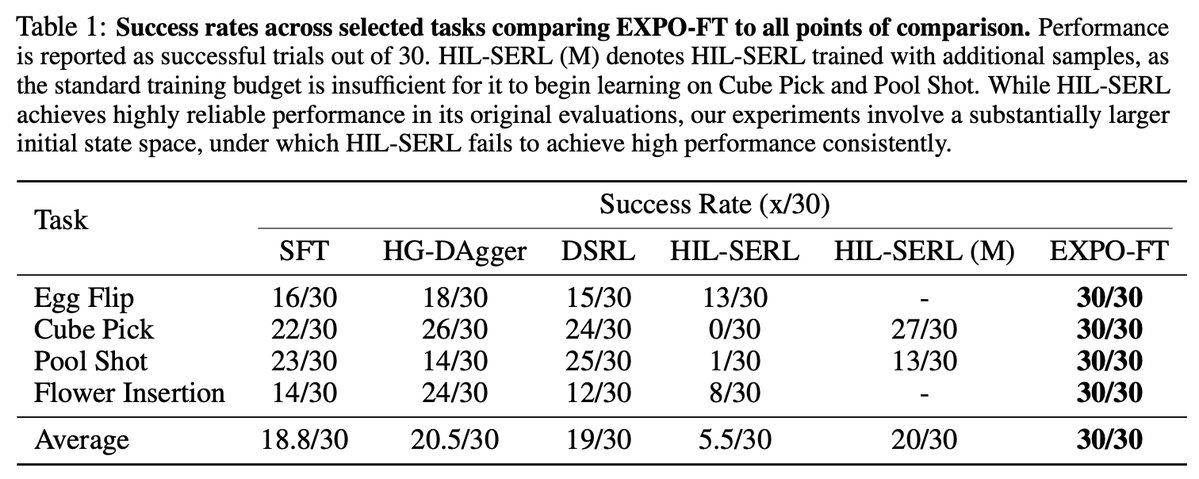
How can VLAs achieve 95+% reliability?
Using RL post-training with EXPO-FT:
- π0.5 improves to 30/30 success on all 8 tasks tested
- uses only 19 min of RL data on average
Paper & videos: https://t.co/54nO9tFU0Z
Introducing EXPO-FT – Efficient, Reliable & Open-Source VLA Finetuning!
EXPO-FT unlocks π0.5 for challenging manipulation tasks:
Routing string lights & inserting the power connector to illuminate them
Striking pool ball into pocket
Inserting flower into wine bottle
(1/5)
EXPO-FT extends EXPO to fine-tune VLAs in the real world, using image observations, action chunking, and DAgger data.
Compared to past methods, EXPO-FT
- reaches higher reliability with less data
- handles wider set of initial states
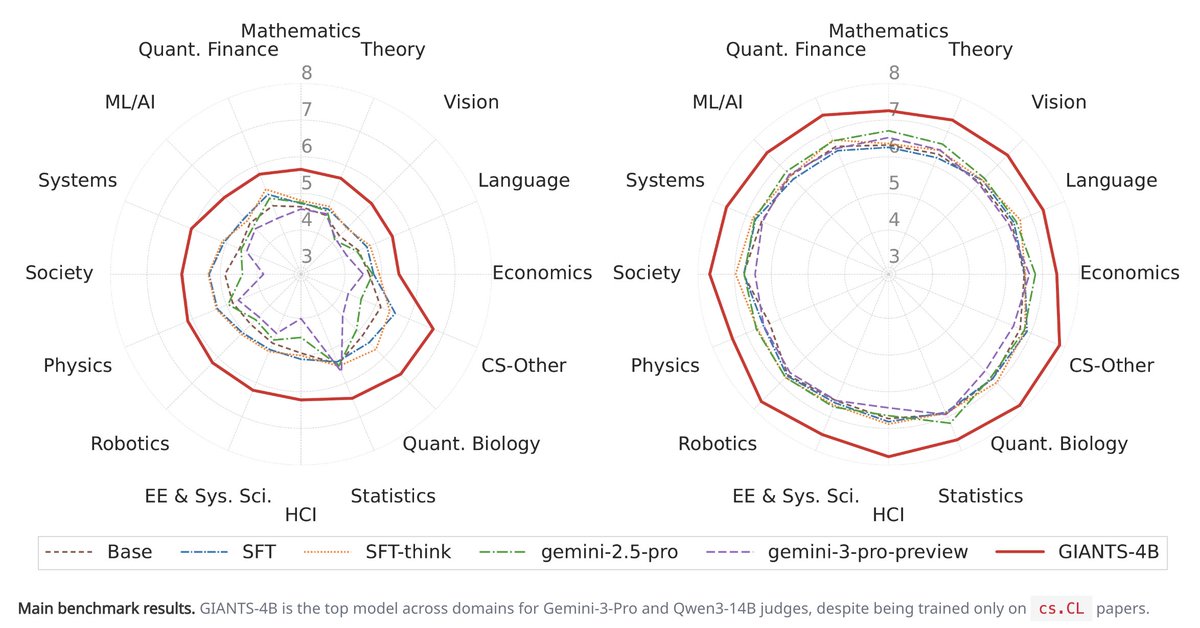
Can LLMs generate new insights that build on prior research?
GiantsBench is a new scientific discovery benchmark, that tests whether models can synthesize new insights given two parent papers.
Paper + data + code: https://t.co/25q0F2jhpi
Scientists often make breakthroughs by synthesizing ideas across papers. In our new paper, we ask whether a language model can anticipate this process: given two parent papers, can it generate the core insight of a future paper built on them? 🧵⬇️
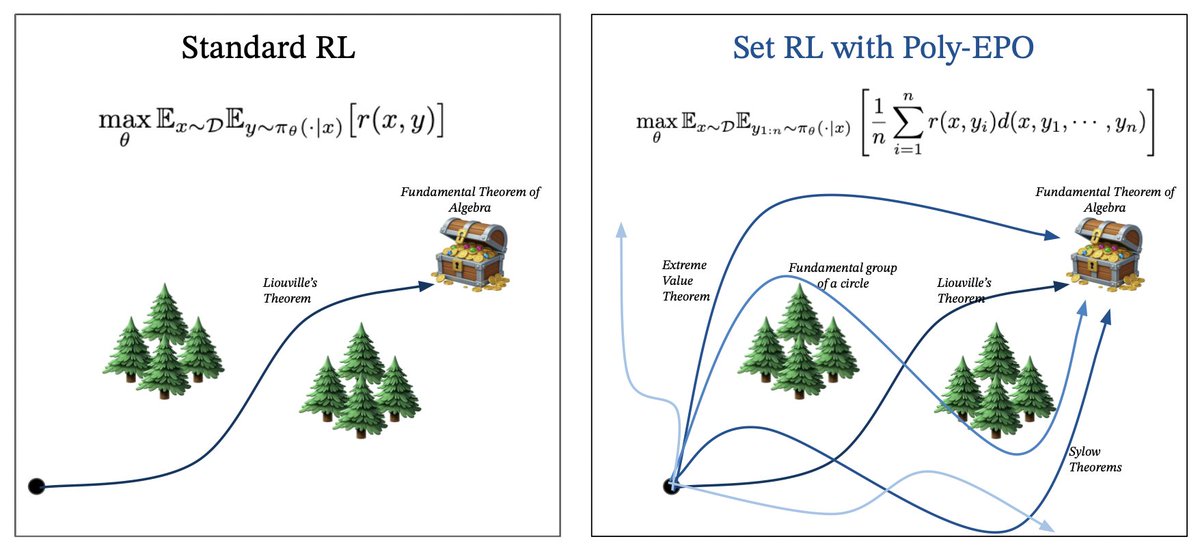
RL fine-tuning often prematurely collapses LLM entropy.
Poly-EPO is a scalable set-RL algorithm that optimizes for a set of accurate solutions with diverse reasoning strategies.
Paper: https://t.co/0HVe8YHr56
Deploying language models in scientific discovery domains requires extraordinary amounts of test-time compute for search algorithms. An ideal training algorithm should be designed with this goal in mind - that we want agents to learn how to not only exploit but also optimistically explore novel strategies. The agent should learn how to synergistically explore and exploit.
We propose Poly-EPO, a set RL algorithm that explores and discovers diverse reasoning paths. Work with @jubayer_hamid (co-lead), Shreya, @ShirleyYXWu, @HengyuanH, @noahdgoodman, @DorsaSadigh, and @chelseabfinn.
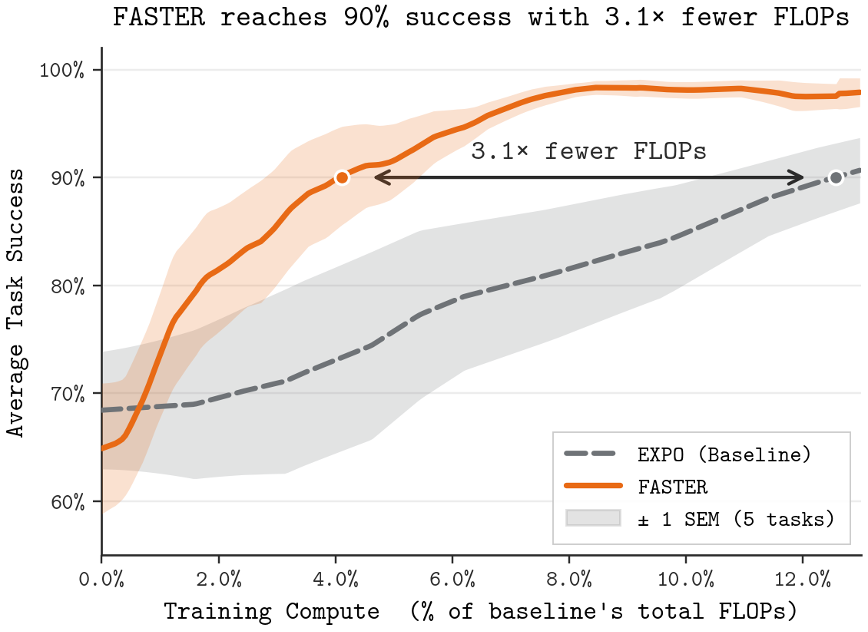
FASTER makes top diffusion RL algos (eg IDQL, EXPO) computationally cheaper while retaining performance
Key idea: a denoising critic that operates on noise, enabling best-of-N filtering before diffusing
Paper + code: https://t.co/ylVWZxu4L9
Top RL algorithms today are getting powerful — but they can be prohibitively expensive, relying on test-time scaling techniques such as best-of-N sampling
We propose FASTER, a method that maintains the performance gains while eliminating the computational costs
(1/6)
I remember sitting down at my desk for the first time, @QuanVng showing me the starter project: let’s make pre-trained models work without fine-tuning?
With π0.7, our pre-trained model works out of the box across so many tasks, matching or even outperforming SFT or RL specialists!
https://t.co/OXxvem0FT0
1/ We just released π0.7 — a steerable generalist robot model with emergent capabilities.
I want to share a bit of the backstory, because π0.7 taught me something surprising about where robot learning is heading. A thread on bittersweet lessons 🧵