VLAs are great, but most lack long-term memory humans use for everyday tasks. This is a critical gap for solving complex, long-horizon problems.
Introducing MemER: Scaling Up Memory for Robot Control via Experience Retrieval.
A thread 🧵 (1/8)
The most capable reasoning systems in AI scale inference compute along several axes: sequential compute to think longer, parallel compute to sample many independent attempts, and aggregative compute to synthesize prior traces into a new improved one. But during training, we only optimize how models use sequential compute. This creates a fundamental mismatch between how we ultimately deploy these systems and how we train them, leaving much of search and synthesis unoptimized.
We introduce SPIRAL, an RL framework for making all inference-compute primitives end-to-end learnable: models learn to coordinate sequential, parallel, and aggregative reasoning using only the reward of the final output. Work with @ifdita_hasan (co-lead), @michaelyli_ , @oshaikh13 , @yoonholeee , @DorsaSadigh , @chelseabfinn , @noahdgoodman 🧵
🚨New time series generative model just dropped.
Paper: https://t.co/2pdg4Y1Ig4
Demo: https://t.co/llqVryo2tg
⏰Meet ABC: Any-Subset Autoregressive Diffusion Bridges in Continuous Time & Space.
With @StefanoErmon@elon_lit@Jose_Blanchet@thanawatsornwan@lutong_hao
VLAs are great, but most lack long-term memory humans use for everyday tasks. This is a critical gap for solving complex, long-horizon problems.
Introducing MemER: Scaling Up Memory for Robot Control via Experience Retrieval.
A thread 🧵 (1/8)
We’re releasing OmniReset, a framework for training robot policies using large-scale RL and diverse resets for contact-rich, dexterous manipulation.
OmniReset pushes the frontier of robustness and dexterity, without any reward engineering or demonstrations.
Try the policies yourself in our interactive simulator! https://t.co/3hW3nYx2vD
(1/N 🧵)
Understanding generalization in robotics can be tricky. If a robot does the dishes in a new kitchen, does this require new behavior, or is the countertop just a new color?
Excited to share RADAR 📡, work I did at @GoogleDeepMind towards better characterizing robot evaluations.
Robot memory methods are growing fast, but systematic evaluation is largely lacking. 📉
Introducing RoboMME: a new benchmark for memory-augmented robotic manipulation! 🤖🧠
Featuring 16 tasks across temporal, spatial, object, and procedural memory
🔗 https://t.co/4ELtnhDwrt
We equipped PI policies with memory!
And taught our robots to do long-horizon real world tasks such as preparing the items for a recipe, cooking a grilled cheese and cleaning the kitchen!
My journey at UC Berkeley is coming to an end as I return to Japan. Over the past four years, I’ve had the privilege of collaborating with @svlevine and his students and I sincerely appreciate their support and contributions. I’ve learned and grown tremendously through our works
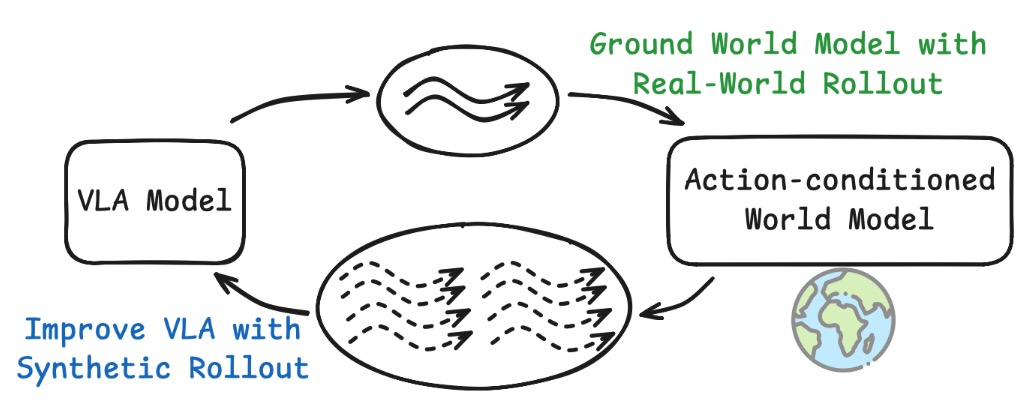
Excited to share VLAW: Iterative Co-Improvement of Vision-Language-Action Policy and World Model
We explore improving VLA inside a learned world model, and find that the key is to jointly improve VLA and WM!
Website: https://t.co/Hfkff47bHZ
Robotic foundation models generalize well—but high inference latency limits real-time deployment.
🚀 AsyncVLA enables real-time control of large robotic models, even under network delays.
Great collaboration with @CatGlossop ,@shahdhruv_ & @svlevine !
#EmbodiedAI#EdgeAI
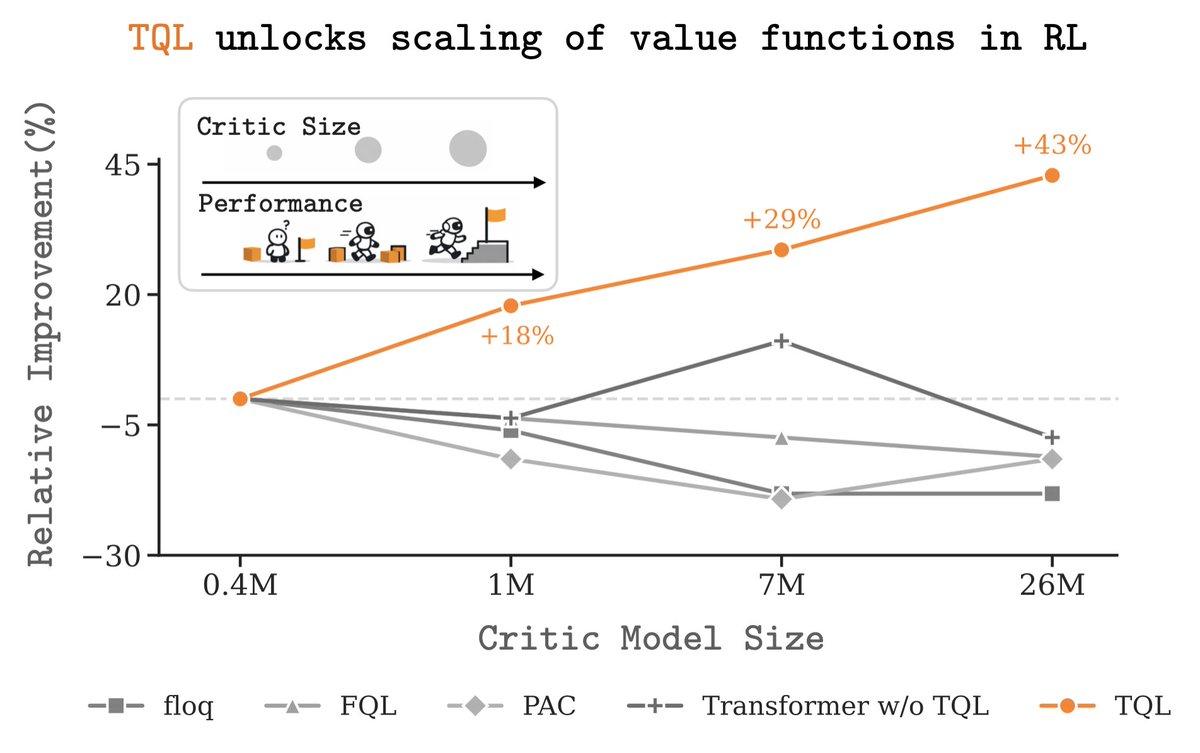
Reinforcement learning doesn't scale like supervised learning—yet
We introduce Transformer Q-Learning (TQL): a method that unlocks scaling of transformer-based value functions in RL
We show that value-based RL can also achieve performance gains through scale
(1/7)
VLAs nowadays enable robotic manipulation to perform impressive tasks like folding clothes, making coffee, and cleaning dishes. However, surprisingly, most VLAs lack memory. Unlike their close relatives LLMs, VLAs have no context window and no access to history. This causes them to repeatedly fail in the same way without learning from online experience.
But why? Why not simply extend the context window like LLMs? It's not that we don't want to -- it's because it's extremely difficult. Here, I share a talk by @chelseabfinn at NeurIPS that scope the challenges in developing long-horizon autonomy for embodied agents. At the end, there's a reading list on memory for robotics. ⭐
Data collection remains a bottleneck in imitation learning for robotics: it’s tedious & often needs access to a robot. Can we make the data collection process more accessible and engaging? We introduce RoboCade, a platform for gamifying remote robot data collection 🎮🤖
(1/6)
Do you ever find finetuning VLA overfits to the target task, to the point where generalist ability is lost and even minor deviations beyond the SFT data break the policy?
We found an extremely simple solution: directly merge the base and finetuned policy in weight space 🤯
👇🧵
Most robot policies today still largely lack memory: they make all their decisions based on what they can see right now. MemER aims to change that by learning which frames are important; this lets it deal with tasks like object search. @ajaysridhar0, @jenpan_,
and @satviks107Sharma tell us about how to achieve this fundamental capability for long-horizon task execution.
Watch Episode #54 of RoboPapers with @micoolcho and @chris_j_paxton to learn more!
Meet Scanford 📚🤖: a robot that improves foundation models by doing useful work in the wild.
Deployed for 2 weeks in the Stanford East Asia Library, Scanford scans books, helps librarians, and continually improves the VLM it relies on.
🔗 https://t.co/r2ZXyeKaIf
🧵1/8
My group @Princeton is hiring!
We are looking for strong postdoc and PhD candidates to join our quest for intelligent robots in open-world environments. Read more below and get in touch 🤖🐅🧡
https://t.co/7o35pwPZCz
How can we create a single navigation policy that works for different robots in diverse environments AND can reach navigation goals with high precision?
Happy to share our new paper, "VAMOS: A Hierarchical Vision-Language-Action Model for Capability-Modulated and Steerable Navigation"!
📜 Paper: https://t.co/XmyuBnrM1D
🌐 Website: https://t.co/Jt80tySWzQ
@yoyu0203 Good point - the HLP is finetuned to predict the labeled indices of the keyframes from the context. We use a subset of subtask transition frames as labels. We only pick useful ones (e.g., last frame of "look inside bin") and skip others (no frames from "reset scooper").
VLAs are great, but most lack long-term memory humans use for everyday tasks. This is a critical gap for solving complex, long-horizon problems.
Introducing MemER: Scaling Up Memory for Robot Control via Experience Retrieval.
A thread 🧵 (1/8)