New work: On-policy distillation with question-specific rubrics as rich and fine-grained supervision.
This is especially useful for hard-to-verify domains!
Check out Siyi's thread for details:
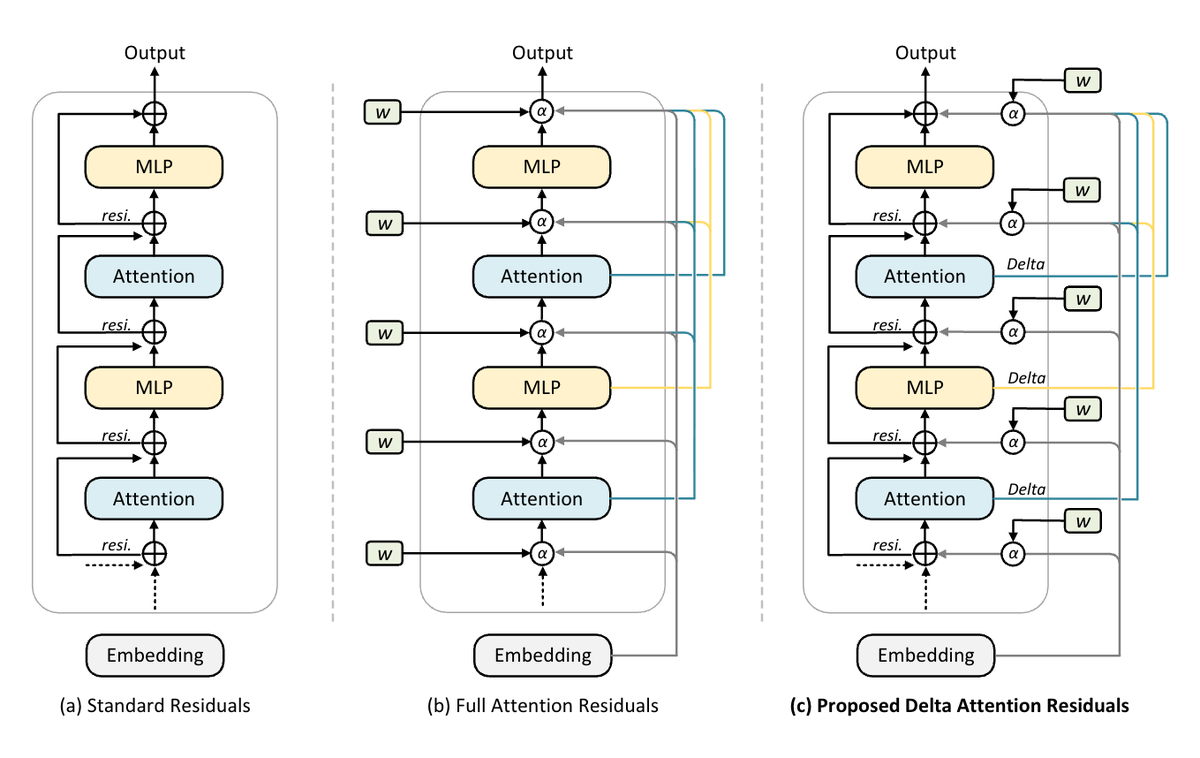
@HeMuyu0327@askerlee@iofu728 Sure it is correct. What is different is that attention residual treats it as a value and uses it to replace the following layer; instead, we treat it as a delta for accumulation.
attention residual = value + replacement
delta attention residual = delta + accumulation
We're excited to release 𝐃𝐞𝐥𝐭𝐚 𝐀𝐭𝐭𝐞𝐧𝐭𝐢𝐨𝐧 𝐑𝐞𝐬𝐢𝐝𝐮𝐚𝐥𝐬, a drop-in upgrade to residual connections that
learns which past layers to route from — without the routing collapse that breaks prior cross-layer
attention at scale. 🚀
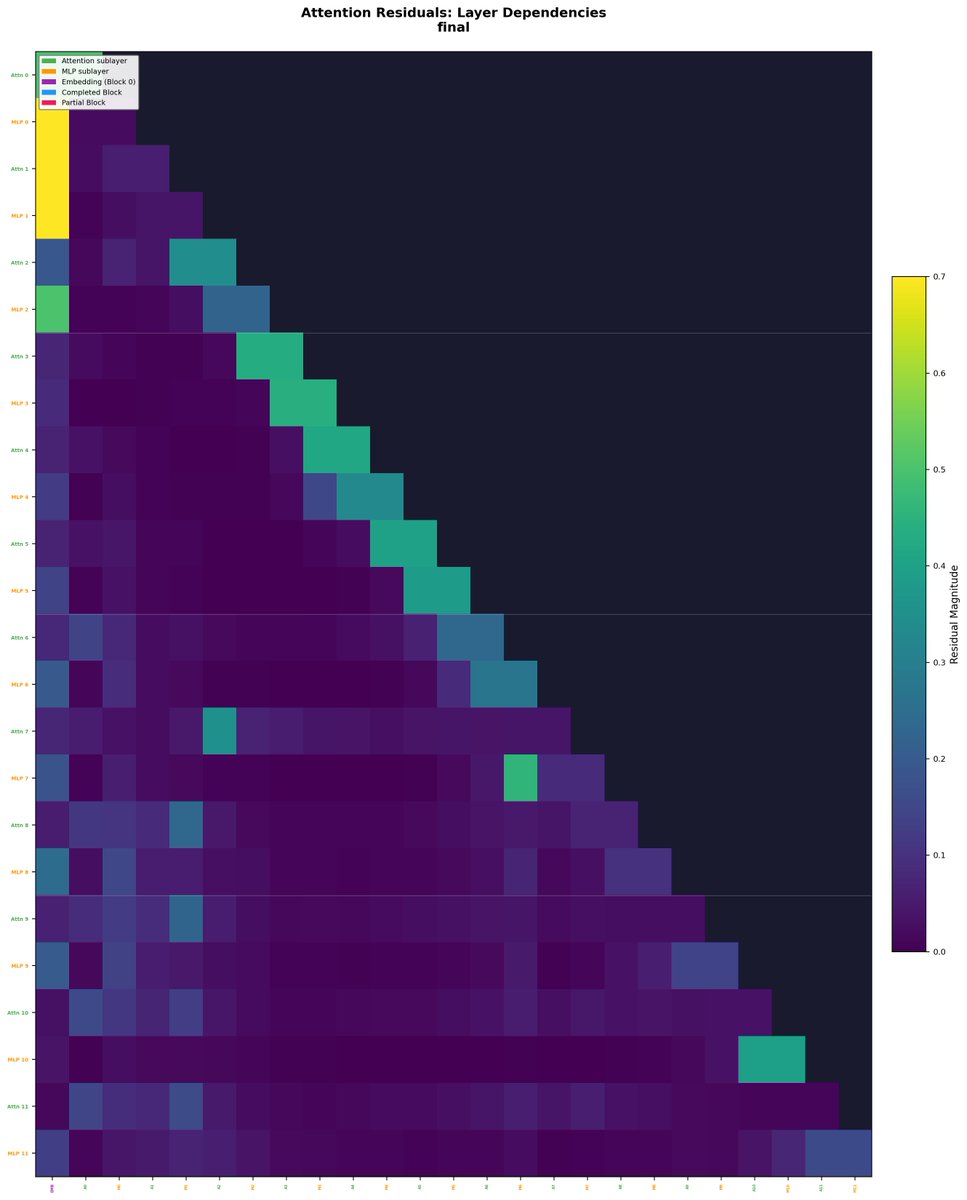
Attention Residuals route over cumulative hidden states, but those are highly redundant, so routing
collapses to near-uniform (max weight ~0.2) in deep layers. Delta Attention Residuals route over
𝐝𝐞𝐥𝐭𝐚𝐬 (vᵢ = hᵢ₊₁ − hᵢ) — what each sublayer actually contributed — and natively enable:
⚡ 𝟏.𝟖× 𝐬𝐡𝐚𝐫𝐩𝐞𝐫 𝐜𝐫𝐨𝐬𝐬-𝐥𝐚𝐲𝐞𝐫 𝐫𝐨𝐮𝐭𝐢𝐧𝐠
Deltas are structurally diverse, lifting max attention weight from ~0.2 → ~0.6 (0.62 vs 0.35 avg)
and curing routing collapse in deep layers.
📉 −𝟖.𝟐% 𝐯𝐚𝐥𝐢𝐝𝐚𝐭𝐢𝐨𝐧 𝐏𝐏𝐋 𝐚𝐭 𝟕.𝟔𝐁
Consistent gains from 220M → 7.6B (1.7–8.2% lower PPL), beating both standard residuals and
Attention Residuals — the latter actually degrades below baseline at scale (18.58 vs 17.43).
🔌 𝐃𝐫𝐨𝐩-𝐢𝐧 𝐟𝐢𝐧𝐞-𝐭𝐮𝐧𝐢𝐧𝐠 𝐨𝐟 𝐩𝐫𝐞𝐭𝐫𝐚𝐢𝐧𝐞𝐝 𝐦𝐨𝐝𝐞𝐥𝐬
Additive, zero-init routing is identity at initialization, so you can convert pretrained
checkpoints (e.g. Qwen3-0.6B) into Delta Attention Residuals via standard fine-tuning — beating the
original on 8 downstream benchmarks (55.6 vs 55.0).
🪶 ≤𝟎.𝟎𝟏% 𝐩𝐚𝐫𝐚𝐦𝐞𝐭𝐞𝐫 𝐨𝐯𝐞𝐫𝐡𝐞𝐚𝐝
Delta Block adds just 589K params (0.008% at 8B) and ~3% memory — and runs faster + lighter than
Attention Residuals (14.0k vs 12.5k tok/s, 42.7 vs 44.0 GB).
💻 Code: https://t.co/c8E4NXCZWn
📄 Paper: https://t.co/Mj1W07qOm2
@dandingsky Great observation. It should be true that our non-negative softmax over deltas is exactly a signed combination over the original cumulative states. An ablation (signed-weight vanilla AttnRes) can be considered for next work.
Thanks for your attention, we totally agree on the intuition that routing over cumulative states would certainly be worse. I thought the same for attention residual, but found that their figure and pseudocode speak differently. Although the original AttnRes code isn't public, our "AttnRes" baseline is a faithful reimplementation of the described mechanism
Delta routing keeps max weight ~0.6 regardless of depth, so its edge over cumulative-state routing widens with scale, and vs a plain baseline our largest gain shows up at our largest run (8B, −8.2%). So no sign of it washing out up to ~8B — but 1T is honestly an extrapolation I wouldn't bet on yet. I hope it can work there
@nrol_ling thanks for the attention, we currently not have the plan or resources to scale up to 1T but we are interested in how this works out for large scale
🌟 Announcing the 2nd Workshop on Efficient Reasoning (ER) at @colm2026 — Oct 9!
📣 We welcome submissions! Submit your work here: https://t.co/loVmlunK87
🗓️ Deadline: July 12, 2026 (AoE)
🔗 Website: https://t.co/FRgQ95CcAd
💬 Topics include (but aren't limited to):
🔹 Multimodal, spatial & embodied reasoning under efficiency constraints
🔹 Curating high-quality reasoning datasets under resource constraints
🔹 Algorithmic innovations for efficient training & RL fine-tuning
🔹 Fast inference: pruning, compression, progressive generation, KV-cache tricks
🔹 Benchmarks & theory on time-/space-complexity and faithfulness
🔹 Systems to deploy long-CoT or on-device reasoning in the wild
🔹 Safety & robustness of efficient reasoning pipelines
🔹 Real-time applications in healthcare, robotics, autonomy, and more
🤝 We invite perspectives from ML, systems, natural & social sciences, and industry practitioners to rethink reasoning under tight compute, memory, latency, and cost budgets.
Hope to see you there! 🚀
🚨 New paper alert !!
🎥 Video VLMs are strong at high-level semantics and long-range temporal understanding.
🧠 JEPA is almost the opposite: better at dense, high-frequency dynamics, local physical consistency, and fast corrective control, but are less suited for rich semantic reasoning and long-horizon reasoning.
We try to get the best of both:
🧩 A VLM as a cortex-like reasoner for semantics and long-horizon planning
⚡ A JEPA branch as a cerebellum-like controller for fine-grained dynamics, physical consistency, and rapid corrections
Proudly, we present ThinkJEPA: a VLM-guided latent world model that FiLM-fuse the pyramid repr of VLMs encoding long-horizon semantic reasoning into the JEPA repr for fine-grained, physically consistent dynamics prediction.
🔗 Project: https://t.co/quro6Pf8un
📄 Paper: https://t.co/yO5rv3ZJT7
@HeMuyu0327 Thanks for your comment. You are correct, the blocks have some problem, we have now updated it with refering KIMI's paper. v_i = f_i(h_i) (The output of the i-th layer's sub-layer—i.e., the increment) h_l = Σ α_{i→l} · v_i (A weighted sum of all preceding increments)
We open-source Attention Residuals — replacing standard additive residuals with learned cross-layer attention in transformers.
Block AttnRes reduces WikiText-2 perplexity by 7.7% with only 0.03% extra parameters.
Includes visualization of how layers route information across depth.
Code: https://t.co/6aBEDlIn1Y
Blog: https://t.co/3VMF7u1PlW
we updated our implemtation based on KIMI's paper.
v_i = f_i(h_i) (The output of the i-th layer's sub-layer—i.e., the increment)
h_l = Σ α_{i→l} · v_i (A weighted sum of all preceding increments)