@_virgil19@rohitgandikota@bfl_ml The text tokens are actually discarded at the end of each denoising step, and they receive no supervision loss during training time; the only supervision is on the image tokens. We show causality through the attention knockout and I2I-to-I2I patching experiments.
For more qualitative and quantitative results, check out our paper and project page.
Project: https://t.co/8z0uPQBZo3
Code: https://t.co/oCRwcHuK5x
Paper: https://t.co/Ao41099M4f
This work was done in collaboration with @rohitgandikota, Antonio Torralba, and @TamarRottShaham
FLUX.2's @bfl_ml text tokens aren't just holding your prompt.
During image editing, they absorb reference image content, and some of that absorbed content, like color and style, causally drives the output appearance.
New paper 🧵👇
Our findings suggest an efficiency opportunity: for some image editing tasks, once the text tokens have absorbed the reference content, the reference image no longer needs to participate in the rest of the computation.
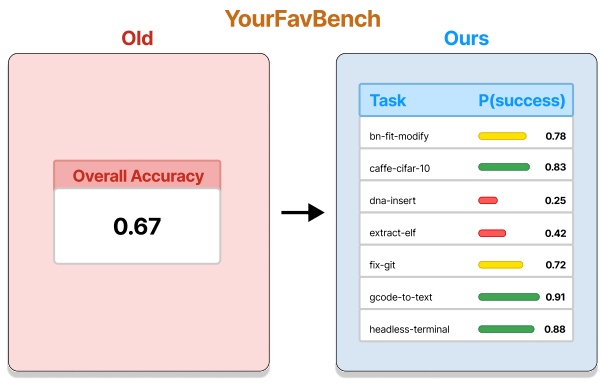
Today’s coding agent evals = single-number benchmark accuracies.
But this obscures important details: which tasks in a benchmark are harder, and why?
We study agent performance at the task level, and predict how new agents perform on new tasks.
📃To appear at ICLR 2026 AIWILD!
🚨 We're open-sourcing Druids, a library for coordinating and deploying coding agents across machines.
Our beta users have used Druids to work on open math problems, conduct ML "autoresearch," and make software faster.