SN102 @ConnitoAI It’s time for loading up ConntoAI ! This correction is a gift 🎁
Distributed training framework !! People are asking what if we train 100B parameters , 1T parameters …!! It 1T is possible then it will he done on ConnitoAI SN102!
🧠 AMA Recap — Isabella Liu $TAO subnet @ConnitoAI SN102
The Nerds hosted Isabella Liu, subnet owner of @ConnitoAI and founding engineer at OTF since 2021.
She was there before subnets existed. The first OTF network was a distributed training task. Five years later, she is back to finish what she started.
This is not an agent subnet. Not inference. Not data scraping.
This is distributed training, the hardest problem in the Bittensor stack.
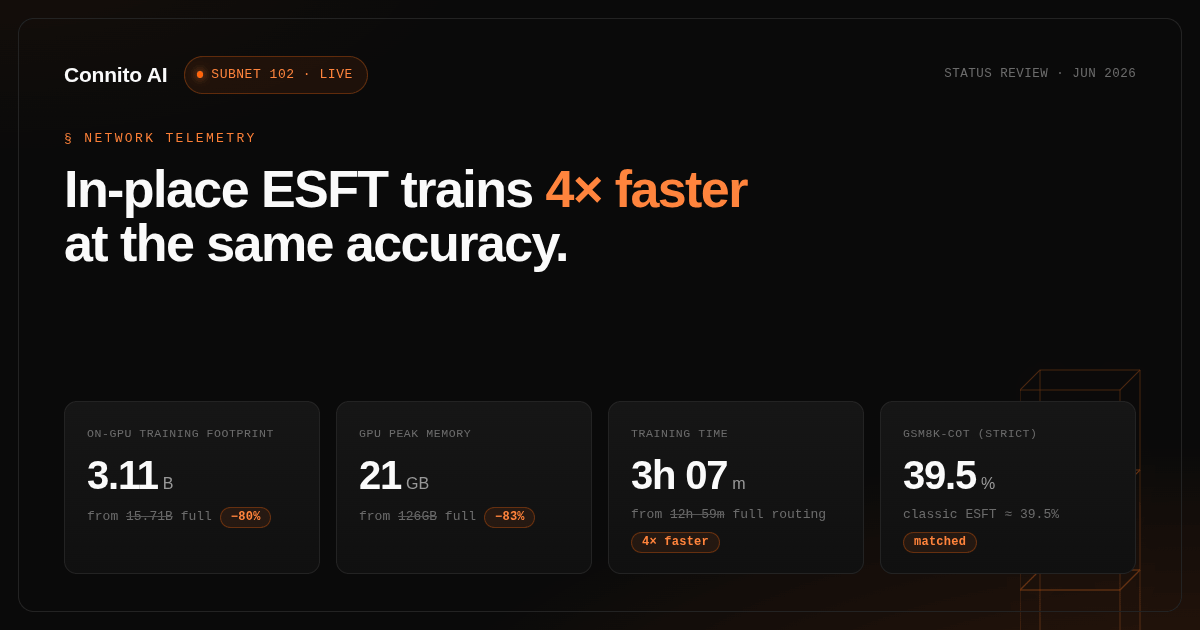
The core issue is simple. Traditional distributed training tops out around 40B to 80B parameters. SOTA models are now 600B to 1T. A single miner cannot afford to train at that scale. If Bittensor relies on traditional architectures, it will always be playing catch-up with centralized labs.
Isabella’s answer is to stop forcing distributed training into architectures built for centralized compute. Reinvent the architecture for distributed from the ground up.
That is where Mixture of Experts comes in.
Each miner trains different experts locally with no communication during training. At step X, the pieces merge back into one model through weight-based merging in a DiLoCo-style setup.
Real example from the AMA: take a 16B model with 64 experts per layer. A miner grabs 8 experts most relevant to a math task, finetunes locally, then passes weight updates back to the validator for loss evaluation.
Cost per miner drops compared to data parallel training. Communication overhead drops compared to pipeline parallel training.
To prevent drift between independently trained experts, there is a shared expert acting as a communication channel. Attention layers are frozen to serve a similar stabilizing role.
This builds on Meta’s Branch-Train-Mix, AI2’s FlexoLMoE, and DeepSeek’s ESFT paper, which showed expert-specific training can outperform LoRA.
The new part is combining those ideas with a decentralized incentive mechanism.
Isabella made a point that stuck with me. The current miner-as-GPU model is limiting. If you want a subnet’s output model to match OpenAI, you would need the owner’s research team to be as big as OpenAI’s.
That is not happening.
But if miners have flexibility in what they train on, and you treat Bittensor’s talent pool as the research team, then you have a real shot.
@ConnitoAI is designed around that thesis.
The team is Isabella and George, her university alumni who did post-grad research in distributed training. They are backed by Crucible Labs for packaging and go-to-market.
The roadmap is research-first.
Next deliverable is a research paper analyzing design choices from the whitepaper. Purpose is to build credibility and attract collaboration with research firms. Then comes a working pilot. Then the goal is to convert collaborations into paying customers.
They are open to B2B and B2C, anyone who needs a model trained on specialized data.
Long term, the vision is training-as-a-service with the modular advantages MoE provides.
Isabella was direct about marketing. Product before marketing. Engineers before marketing hires. The whitepaper dropped before this AMA.
The honest gaps:
Data privacy for defense and healthcare is still unsolved, and she said so.
Man hours are a real constraint. Two-person research team with more to build than they can currently cover.
No paying customer yet. Go-to-market is a plan, not a pipeline.
This is early stage, research-heavy, and technically ambitious.
But Isabella has been thinking about this problem longer than most people have known Bittensor exists. The architecture is differentiated from every other distributed training attempt in the ecosystem. I am willing to bet that she will succeed
We’re excited to share the Connito whitepaper V1: a framework for decentralized, composable MoE adaptation.
We trains sparse expert subsets, validates updates through Proof-of-Loss, and turns open-model improvement into a distributed expert-level market.
Read the whitepaper: https://t.co/KKkGVnMIRF