Former Meta top-tier engineer:
"I don't review the code anymore. I got to a point where I never catch anything the agents don't catch."
He runs 20-30 agents at once and ships 20-40 PRs a day, work that used to take a full team a month.
In 55 minutes he explains everything he knows and builds a fully working workflow from scratch.
Watch it, then read the full guide on building loops below.
Attention is a lookup. Each token builds a query, compares it against every key in the sequence, and pulls value vectors weighted by the match. Stack that 96 layers deep and you get a frontier model.
Video covers the full pipeline: Q/K/V, attention scores, encoder blocks.
Part 2 of our 𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗔𝗜 𝗜𝗻𝗳𝗲𝗿𝗲𝗻𝗰𝗲 series is now live on Red Hat Developer: 𝘖𝘱𝘵𝘪𝘮𝘪𝘻𝘪𝘯𝘨 𝘋𝘪𝘴𝘵𝘳𝘪𝘣𝘶𝘵𝘦𝘥 𝘈𝘐 𝘐𝘯𝘧𝘦𝘳𝘦𝘯𝘤𝘦: 𝘈𝘥𝘷𝘢𝘯𝘤𝘦𝘥 𝘋𝘦𝘱𝘭𝘰𝘺𝘮𝘦𝘯𝘵 𝘗𝘢𝘵𝘵𝘦𝘳𝘯𝘴.
In Part 1, we covered prefill/decode phases and the 5D parallelism framework. Part 2 dives into the three optimization levers that deliver most of the cost and latency improvements once your parallelism layout is set:
- 𝗣/𝗗 𝗗𝗶𝘀𝗮𝗴𝗴𝗿𝗲𝗴𝗮𝘁𝗶𝗼𝗻: Not a feature to toggle on - it's a deployment topology. We share how to measure whether the prefill-to-decode imbalance in your traffic justifies the split, with 25-40% cost reductions on chat and RAG workloads in our benchmarks.
- 𝗞𝗩 𝗖𝗮𝗰𝗵𝗲 𝗔𝗿𝗰𝗵𝗶𝘁��𝗰𝘁𝘂𝗿e: Tiering across HBM, DRAM, and NVMe with LMCache, the difference between prefix sharing and KV reuse (they're not the same thing), and when FP8/FP4 quantization pays off.
- 𝗦𝗽𝗲𝗰��𝗹𝗮𝘁𝗶𝘃𝗲 𝗗𝗲𝗰𝗼𝗱𝗶𝗻𝗴: EAGLE 3.1 now extends gains into long-context regimes with 2x longer acceptance length than EAGLE-3. But watch out - acceptance rates collapse under constrained decoding (JSON mode, tool calls), so measure before enabling on tool-calling traffic.
One insight that keeps coming up: cache-aware routing via @_llm_d_ is what turns disaggregation from a checkbox into a working system. Round-robin leaves cache hits on the table.
Co-authored with Fatih E. Nar, Yuchen Fama, and Greg Pereira. Part 3 covering deployment blueprints and troubleshooting recipes is coming soon - follow along to catch it.
Read Part 2: https://t.co/ozlVsXYUjd
Prefill & decode in LLM inference.
Have you ever noticed that the first token from an LLM always takes a moment to appear? But the subsequent tokens stream out smoothly?
That pause isn't a network lag, but rather it's a structural property of how LLMs fundamentally work.
Inference happens in two phases that share the same model and the same code path, but the workload looks completely different in each, with different bottlenecks.
> Prefill stage starts when you submit a prompt.
The model processes every input token in one parallel pass, computing Q, K, and V for all of them at once.
Attention runs as a matrix multiplication, and the GPU chips run at high utilization, doing fast math.
Prefill is compute-bound, and the metric that captures it is time-to-first-token (TTFT).
> Decode stage starts once the first token is out.
To generate the next one, the model only computes Q, K, and V for that single new token, because everything before it is already cached.
So the model loops one token per forward pass, multiplying a single query against the cached keys instead of a full matrix. This makes the inference fast due to the tiny computation.
But the GPU still has to load every weight and every cached entry from memory to do that tiny computation, so the bottleneck flips and compute sits idle while memory bandwidth becomes the limiting factor.
Decode is memory-bound, and the metric that captures it is inter-token latency (ITL).
GPU utilization peaks during prefill and drops sharply during decode because memory, not compute, is the bottleneck in the second phase.
Throwing more compute at a slow-streaming model often does nothing because the fix for memory-bound workloads is faster memory or a smaller cache, not more FLOPs.
Long contexts feel disproportionately slow because the KV cache grows with every token, and every decode step has to read all of it.
But maintaining the cache is an important optimization since it makes decoding viable.
- Without KV cache, every new token would force a recomputation of attention over the entire growing sequence.
- With KV cache, the cache is built once during prefill, then grows by exactly one entry per decode step, with existing entries reused rather than recomputed.
The cache lives in GPU memory and grows linearly with sequence length, so a 13B model roughly requires 1 MB per token, which means a 4K context consumes 4 GB of VRAM on the cache alone.
The entire field is now optimizing around this constraint with quantized caches, sliding windows, grouped-query attention, and PagedAttention, while DeepSeek's V4 series goes further and redesigns attention itself so the cache stays small from the start.
The practical takeaway is that when someone says their model feels slow, the first question is whether it's slow to start or slow to stream.
Slow to start means prefill and a compute bottleneck, while slow to stream means decode and a memory bottleneck.
The article below is a first-principles guide to LLM inference that walks through everything between your prompt and the streamed response, covering tokenization, embeddings, attention, the prefill and decode split, KV caching, and quantization.
It will give you a complete mental model of how inference actually works under the hood.
Read it below.
Can LLMs keep learning new skills without updating their weights?
Modern LLMs can already master & combine many skills. But teaching them new skills in a scalable way without catastrophic forgetting remains an open challenge
@icmlconf we introduce a new approach: skill neologisms
DO NOT USE OBSIDIAN UNTIL YOU READ THIS DOCUMENT FROM KARPATHY
I was perfectly happy relying on NotebookLM and Obsidian, but applying this specific framework completely broke my understanding of what a local agent can do
it genuinely feels like early access to Claude Fable 5
here is the exact file explaining how it works 👇
KARPATHY WROTE THIS DOCUMENT TO COMPLETELY AUTOMATE OBSIDIAN WITH CLAUDE
I was ready to abandon my second brain
manual cross-referencing was destroying my workflow, but finding this exact document opened my eyes to a completely different approach
it is incredibly convenient -> Karpathy's method turns the AI into a full-time maintainer for your Zettelkasten:
> the LLM reads every new source and integrates it into a structured wiki
> Obsidian becomes your visual IDE while Claude operates as the backend
> the agent runs automated checks to find contradictions across your notes
> your entire vault compounds automatically without you typing a single link
the friction is completely gone. I just feed it raw documents and the agent organizes my entire life
here is the official document from Karpathy explaining the architecture 👇
Matt Pocock just dropped a free 2-hour workshop on the exact workflow he uses to ship code with AI agents.
This is the most practical breakdown of AI-assisted development you'll find anywhere.
People are paying $500 for courses that teach less than this.
Watch it, then read the step by step guide on AI coding workflows below.
Andrej Karpathy joined Anthropic five weeks ago.
Yesterday my friend on his team sent me the Claude.md file he actually uses.
It completely changed how I work with Claude.
From the very first message, the difference was obvious.
With this file, Claude finally stops fighting me and starts working exactly the way I need it to.
Bookmark it before it gets taken down.
Read it now, then check the article below.
How I use LLMs as a staff engineer in 2026
https://t.co/KDzmfiUF87
The biggest AI workflow change in 2026: treating agents as capable collaborators for coding, debugging, testing, and codebase research—while still keeping humans responsible for judgment, communication, and review.
Skip transformer math to build AI agents in 2026.
You just need these 6 (+1) core architectural pillars.
𝟭. 𝗠𝗼𝗱𝗲𝗹 𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗣𝗿𝗼𝘁𝗼𝗰𝗼𝗹 (𝗠𝗖𝗣)
Think "USB-C for AI." One universal standard that lets any agent plug into external tools and data — instead of hand-building an integration for every tool. Anthropic introduced it; the industry adopted it fast.
𝟮. 𝗔𝗴𝗲𝗻𝘁 𝗟𝗼𝗼𝗽𝘀
The engine behind every agent. A cycle of: perceive → think → act → observe → repeat. The agent keeps looping until the task is done, or it decides it's stuck. No loop, no autonomy.
𝟯. 𝗦𝗸𝗶𝗹𝗹𝘀
The agent's job description. MCP handles the connection and tools expose the API, a Skill is the higher-level logic that orchestrates them into a finished outcome.
𝟰. 𝗦𝗶𝗻𝗴𝗹𝗲 𝘃𝘀 𝗠𝘂𝗹𝘁𝗶-𝗔𝗴𝗲𝗻𝘁 𝗔𝗿𝗰𝗵𝗶𝘁��𝗰𝘁𝘂𝗿𝗲
Two ends of one spectrum. Single-agent: one LLM runs the whole pipeline. Multi-agent: specialized agents split the work, one retrieves, one validates, one writes, trading simplicity for scale.
𝟱. 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗥𝗔𝗚
RAG with a brain. The agent can route queries to specialized knowledge sources, validate retrieved context, and make dynamic decisions about what information to use.
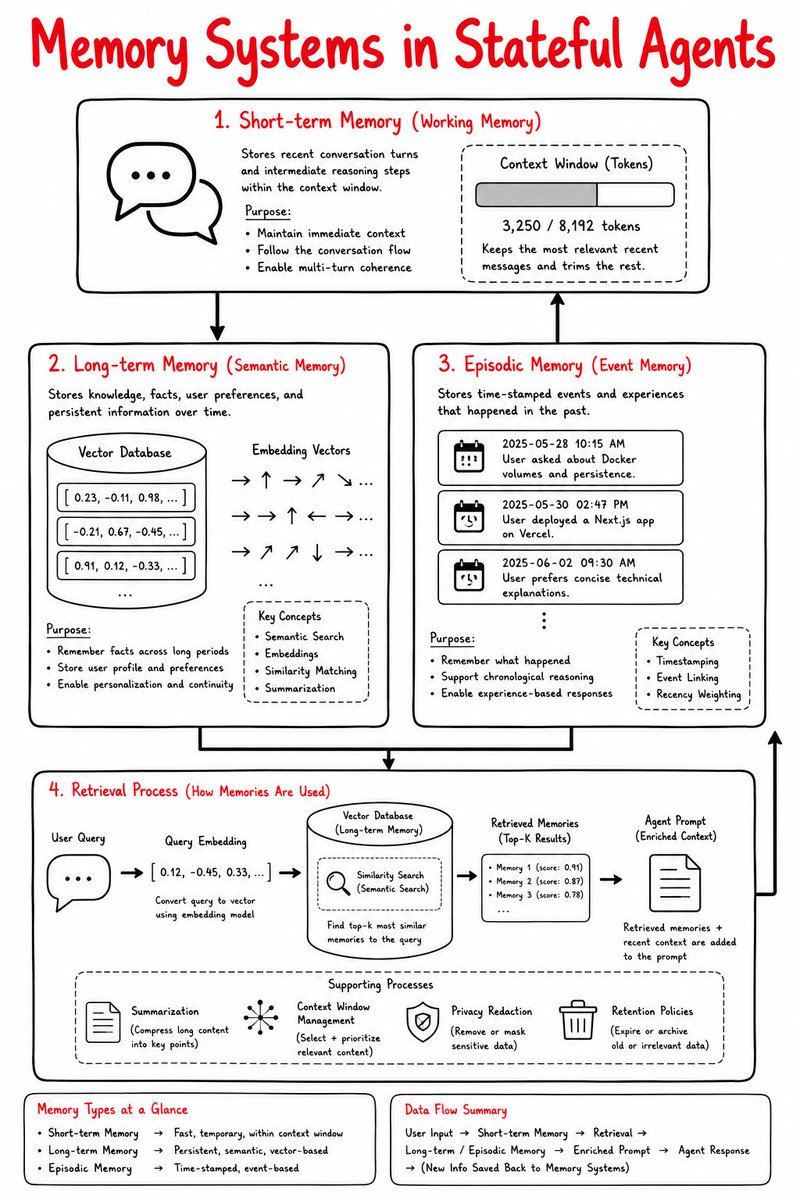
𝟲. 𝗔𝗴𝗲𝗻𝘁 𝗠𝗲𝗺𝗼𝗿𝘆
Short-term lives in the context window; long-term is pulled on demand from external stores (knowledge bases or vector databases). It's what keeps agents coherent across interactions, and lets them learn from past ones.
𝟳. 𝗛𝘂𝗺𝗮𝗻-𝗶𝗻-𝘁𝗵𝗲-𝗟𝗼𝗼𝗽 (𝗛𝗜𝗧𝗟)
The ultimate guardrail. Autonomous loops are powerful, but pure autonomy is dangerous for high-stakes tasks. HITL inserts human checkpoints for approval or correction before critical actions run.
Which term would you add? 🤔
Anthropic just dropped a 33-page blueprint for building effective AI agents. Zero theory, just production architecture patterns used by Claude, Coinbase, Stripe, and Intercom.
Every system follows one cycle: Perceive -> Decide -> Act -> Evaluate -> Repeat.
Here are the 5 core patterns to know:
Single Agent: One model in a loop. Solves 80% of problems, don't over-engineer it.
Sequential: Step-by-step handoffs. Predictable and easy to audit.
Parallel: Tasks split across agents at once, then merged. Built for speed.
Hierarchical: A supervisor agent managing a team of specialists.
Evaluator-Optimizer: A 2-agent loop (generator + critic) refining quality over 2-4 cycles.
The Bottom Line: Multi-agent architectures outperform single models by 90.2% on complex tasks. Just match your complexity to the value.
Read the manual, then check out the "Loop engineering" article below.
𝗧𝗵𝗲 𝟮𝟬 𝘀𝗼𝗳𝘁𝘄𝗮𝗿𝗲 𝗲𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 𝗹𝗮𝘄𝘀 𝗲𝘃𝗲𝗿𝘆 𝗲𝗻𝗴𝗶𝗻𝗲𝗲𝗿 𝗺𝘂𝘀𝘁 𝗸𝗻𝗼𝘄
1. 𝗚𝗮𝗹𝗹'𝘀 𝗹𝗮𝘄: A complex system that works evolves from a simple one that did.
2. 𝗞𝗜𝗦𝗦: Keep it simple. Anything beyond that is overhead.
3. 𝗖𝗼𝗻𝘄����𝘆'𝘀 𝗹𝗮𝘄: Organizations design systems that mirror their communication structure.
4. 𝗛𝘆𝗿𝘂𝗺'𝘀 𝗹𝗮𝘄: With a sufficient number of users of an API, it does not matter what you promise in the contract. All observable behaviors of your system will be depended on by somebody.
5. 𝗖𝗔𝗣 𝘁𝗵𝗲𝗼𝗿𝗲𝗺: Pick two: consistency, availability, partition tolerance.
6. 𝗭𝗮𝘄𝗶𝗻𝘀𝗸𝗶'𝘀 𝗹𝗮𝘄: Every program expands until it can read mail.
7. 𝗕𝗿𝗼𝗼𝗸𝘀'𝘀 𝗹𝗮𝘄: Adding people to a late software project makes it later.
8. 𝗥𝗶𝗻𝗴𝗲𝗹𝗺𝗮𝗻𝗻 𝗲𝗳𝗳𝗲𝗰𝘁: Individual members of a group become increasingly less productive as the size of the group increases.
9. 𝗣𝗿𝗶𝗰𝗲'𝘀 𝗹𝗮𝘄: Half the work is done by the square root of the people.
10. 𝗗𝘂𝗻𝗻𝗶𝗻𝗴-𝗞𝗿𝘂𝗴𝗲𝗿 𝗲𝗳𝗳𝗲𝗰𝘁: People with low ability at a task tend to overestimate their ability, while experts tend to underestimate theirs.
11. 𝗛𝗼𝗳𝘀𝘁𝗮𝗱𝘁𝗲𝗿'𝘀 𝗹𝗮𝘄: It always takes longer than you expect, even accounting for this law.
12. 𝗣𝗮𝗿𝗸𝗶𝗻𝘀𝗼𝗻'𝘀 𝗹𝗮𝘄: Work expands to fill the time available for its completion.
13. 𝗚𝗼𝗼𝗱𝗵𝗮𝗿𝘁'𝘀 𝗹𝗮𝘄: When a measure becomes a target, it stops being a good measure.
14. 𝗚𝗶𝗹𝗯'𝘀 𝗹𝗮𝘄: Measuring imperfectly is better than not measuring at all.
15. 𝗞𝗻𝘂𝘁𝗵'𝘀 𝗽𝗿𝗶𝗻𝗰𝗶𝗽𝗹𝗲: We should forget about small efficiencies about 97% of the time. Premature optimization is the root of all evil.
16. 𝗔𝗺𝗱𝗮𝗵𝗹'𝘀 𝗹𝗮𝘄: The speedup from improving one part of a system is limited by the fraction of time that part is actually used.
17. 𝗠𝘂𝗿𝗽𝗵𝘆'𝘀 𝗹𝗮𝘄: Anything that can go wrong will go wrong.
18. 𝗣𝗼𝘀𝘁𝗲𝗹'𝘀 𝗹𝗮𝘄: Be conservative in what you send, liberal in what you accept.
19. 𝗦𝘁𝘂𝗿𝗴𝗲𝗼𝗻'𝘀 𝗹𝗮𝘄: Ninety percent of everything is crap.
20. 𝗖𝘂𝗻𝗻𝗶𝗻𝗴𝗵𝗮𝗺'𝘀 𝗹𝗮𝘄: The best way to get the right answer on the internet is not to ask a question. It is to post the wrong answer.
Which one resonates with you the best?