Chief AI Scientist, Oracle, and the Eduardo D. Glandt Distinguished Professor, CIS, University of Pennsylvania. Former VP/Distinguished Scientist, AWS AI Labs.
Social Impact Award:
"AccessEval: Benchmarking Disability Bias in Large Language Models"
by Srikant Panda, Amit Agarwal, and Hitesh Laxmichand Patel
https://t.co/tcT69fbM42
10/n
📷 New #EMNLP2025 Findings survey paper!
“Conflicts in Texts: Data, Implications, and Challenges” Paper: https://t.co/Tav9i9mYvP
Conflicts are everywhere in NLP — news articles reflecting different perspectives or opposing views, annotators who disagree, LLMs that hallucinate or contradict themselves, and personal/enterprise document collections that grow apart and are conflicting. Most research tackles these in isolation, and our survey provides the first unified view of conflicting information in NLP. We chart the path toward conflict-aware, reliable NLP systems.
Builds on our earlier work on:
- Multi-perspective dataset https://t.co/ZMk3RuTbWv and search https://t.co/9KJ01DascE
- Hallucination detection https://t.co/CUSXbakDeL
- Open-domain QA with conflicting contexts https://t.co/qVMyjFStgh
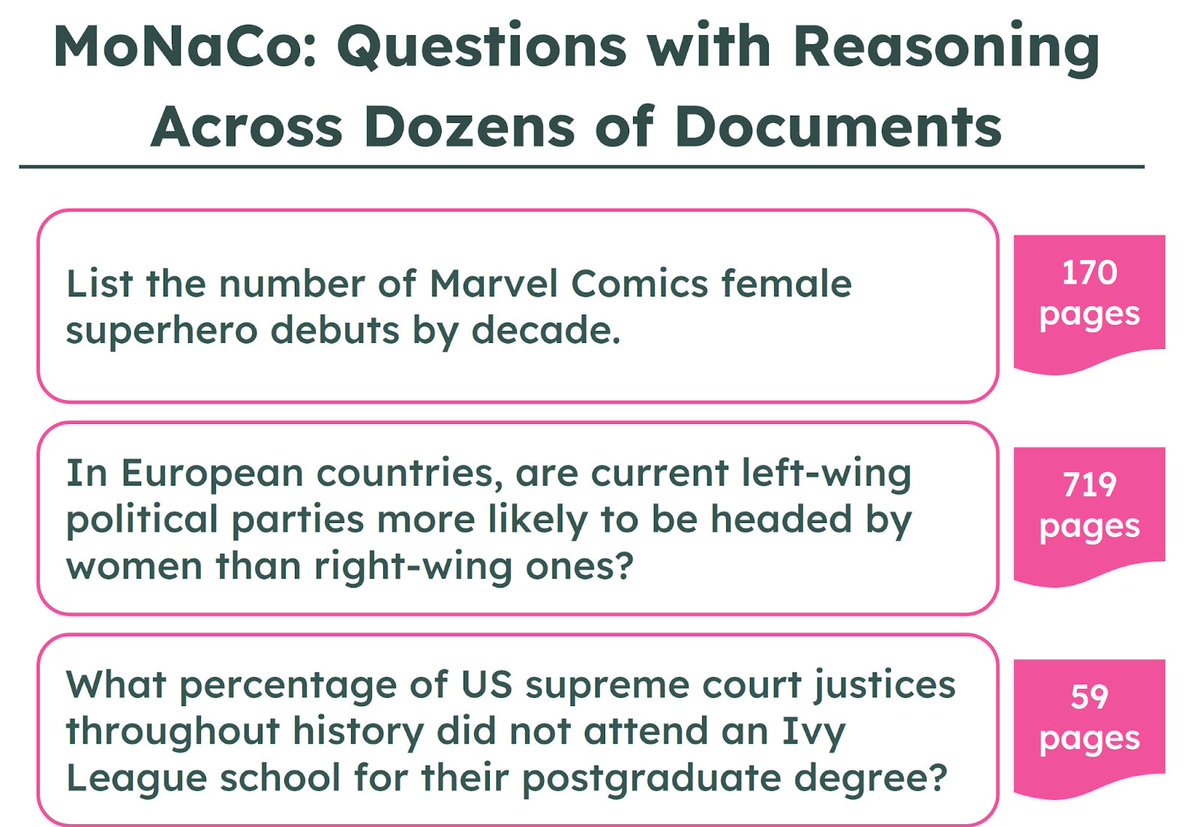
✨Yesterday we released MoNaCo, an @allen_ai benchmark of 1,315 hard human-written questions that, on average, require 43.3 documents per question!✨
The three aforementioned questions were actually some of the easier ones in MoNaCo 😉 (8/)
https://t.co/Ad9FrWiwtn
MoNaCo evaluates complex question-answering with:
📚 1,315 multi‑step queries
🔎 Retrieval, filtering & aggregation across text and tables
🌟 Avg 43.3 distinct documents per query
LLMs power research, decision‑making, and exploration—but most benchmarks don’t test how well they stitch together evidence across dozens (or hundreds) of sources. Meet MoNaCo, our new eval for question-answering cross‑source reasoning. 👇
Augmenting GPT-4o with Visual Sketchpad ✏️
We introduce Sketchpad agent, a framework that equips multimodal LLMs with a visual canvas and drawing tools 🎨 . Improving GPT-4o's performance in vision and math tasks 📈
🔗: https://t.co/I6ul5406E6
🔥Highlights of the Commonsense-T2I benchmark:
📚Pairwise text prompts with minimum token change
⚙️Rigorous automatic evaluation with descriptions for expected outputs
❗️Even DALL-E 3 only achieves below 50% accuracy
(2/n)
Can Text-to-Image models understand common sense? 🤔
Can they generate images that fit everyday common sense? 🤔
tldr; NO, they are far less intelligent than us 💁🏻♀️
Introducing Commonsense-T2I 💡 https://t.co/CTcmCbGUhX, a novel evaluation and benchmark designed to measure commonsense reasoning in T2I models 🔥🔥
Paper: https://t.co/Csu2Q0453s
(1/n)
Best-fit Packing completely eliminates unnecessary truncations while retaining the same training efficiency as concatenation with <0.01% overhead tested on popular pre-training datasets like @TIIuae's RefinedWeb and @BigCodeProject's Stack.🧵5/n
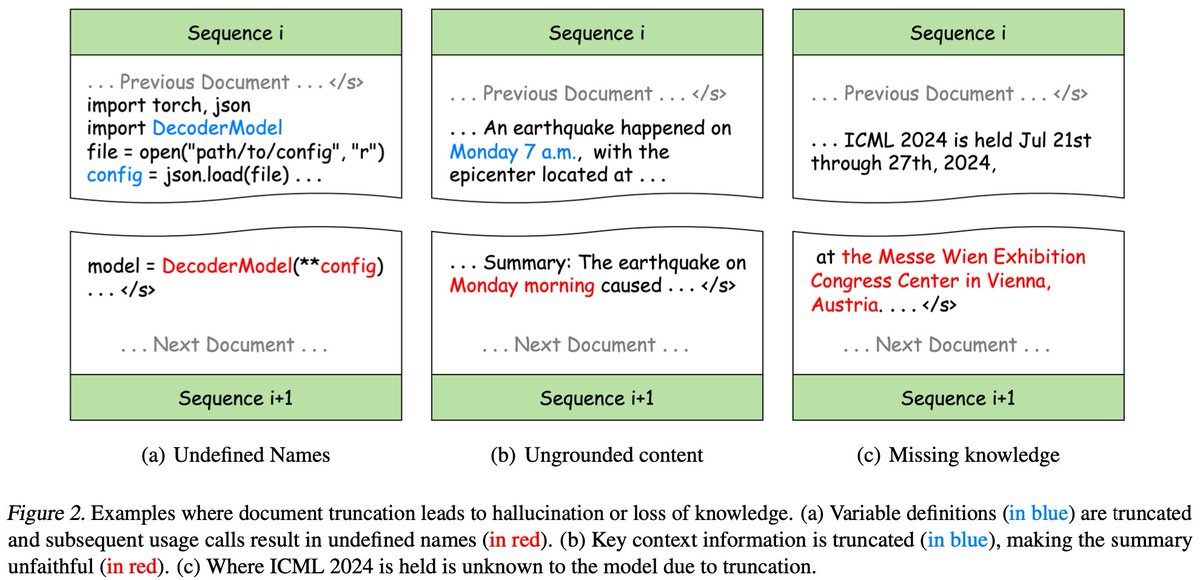
The common practice in LLM pre-training is to concat all docs then split into equal-length chunks. This is efficient but hurts data integrity: doc fragmentation leads to loss of info, and causes next-token prediction to be ungrounded, making model prone to hallucination.🧵2/n
🚀Introducing "Fewer Truncations Improve Language Modeling" at #ICML2024
We tackle a fundamental issue in LLM pre-training: docs are often broken into pieces. Such truncation hinders model from learning to compose logically coherent and factually grounded content.
👇🧵1/n
Can GPT-4V and Gemini-Pro perceive the world the way humans do? 🤔
Can they solve the vision tasks that humans can in the blink of an eye? 😉
tldr; NO, they are far worse than us 💁🏻♀️
Introducing BLINK👁 https://t.co/EGDh0bMnyJ, a novel benchmark that studies visual perception abilities NOT yet “emerged” in Multimodal LLMs 🔥🔥
Paper: https://t.co/teFGLiXU12
(1/n)
We are thrilled to announce our second workshop on natural language interfaces, held in conjunction with the prestigious IJCNL-AACL conference! In collaboration with researchers from AWS AI Labs, Google Research, Meta AI Research, and Microsoft Research, this workshop aims to
https://t.co/duGiOK8wBP is really neat. Helps you code faster, checks for security vulns, discloses licenses of code it drew from, and works great for AWS APIs. Boom! @awscloud putting ML to work for developers