Run Polars' distributed engine on your own infrastructure.
Deploy a distributed Polars cluster on any Kubernetes setup (EKS, AKS, GKE, or minikube) and get a query dashboard with past queries, advanced query profiling, Open-lineage support, and more.
Sign up and install with a single Helm command. Connect via `ClusterContext` and run distributed queries.
Read all about it at https://t.co/PnKfBF2wZ2
We've released Python Polars 1.41. Some of the highlights:
• Faster Parquet metadata decoding
Parquet metadata is now decoded with a hand-written, specialized Thrift parser instead of the generic auto-generated one. Speedup scales with table width: 1.6× for 100-column tables, up to 3.3× for 10,000-column tables.
• Nested common subplan elimination
The query optimizer now eliminates duplicate subplans at all nesting depths.
• LazyFrame.gather()
Row selection by integer index is now available in lazy mode, without collecting first.
Blog post: https://t.co/r5vnzQ4HkJ
We're big @DataPolars fans at marimo. The Polars team has been working on something new: it's early, it's fancy, and it ships with a few features that are directly relevant to marimo.
Livestream with @thijsnieuwdorp on May 22, 2026. Link below ⬇️
Polars supports a full Iceberg roundtrip on the streaming engine. You can scan an Iceberg table with scan_iceberg(), transform it lazily, and write the result back with sink_iceberg().
Useful for workflows like data redaction or compliance cleanup: scan the table, redact the matching user's PII, and overwrite the table with the cleaned result. That overwrite is committed as a new Iceberg snapshot, and after you validate it you can expire older snapshots as part of your cleanup workflow.
Handling schema changes in Polars.
Our latest blog post maps the four shapes of schema change (a new column appears, an expected one disappears, a type drifts, or one breaks) to the Polars solution that handles each, across CSV, multi-file Parquet, Delta Lake, and Apache Iceberg.
Read the full breakdown here: https://t.co/JouEgqDbaS
We've released Python Polars 1.40. Some of the highlights:
• Streaming grouped AsOf join
AsOf joins with a `by` argument are now supported in the streaming engine, extending last release's streaming AsOf support to grouped time-series joins.
• Basic over() in the streaming engine
Elementwise window expressions using over() can now run in the streaming engine.
• More expressions lowered to streaming
cov(), corr(), interpolate(), skew(), kurtosis(), and entropy() are now natively supported in the streaming engine.
Link to the complete changelog: https://t.co/P7pkxZrNuk
We've been busy in Q1 2026.
12 releases. 778 PRs. 95 contributors (thank you!).
The streaming engine now covers more join types, all major formats have a streaming scan implementation, Delta and Iceberg both have full read/write support, and Polars Cloud gained a query profiler that helped us run a TPC-H benchmark 54% faster at 64% lower cost.
Read all the highlights in the latest Polars in Aggregate:
https://t.co/Eppegzhmas
Polars loves sorted data!
If your data is already sorted, you can get a performance boost up to 18x when joining your datasets.
Read all about it in our latest blog post: https://t.co/kO8X3rMcEq
Realtime query profiling of Polars
In this post we use the query profiler in Polars Cloud to optimize the infrastructure configuration for a specific query. This results in a 54% faster and 64% cheaper query with only five runs.
Read all about it here: https://t.co/FxX1WHKzHX
We've released Polars Cloud client 0.6.0. Some of the highlights:
• Improved UX for query profiling
Data skew is now included in the metrics, showing how long workers take to execute the stage and the size of partitions. You can now also see resource metrics per stage.
• Compute Scratchpad Alpha
We've released a new interactive scratchpad functionality for ad-hoc computation that runs on your Polars Cloud cluster.
• Improved distributed query planning
Various improvements in the distributed query planning to improve stability & performance.
• Breaking: `LazyFrameRemote.execute` is now blocking by default
Previously fire-and-forget, `.execute()` now blocks until the query completes. Providing the parameter `blocking=False` triggers the old behavior.
Quoting Jensen: "All of these platforms are processing DataFrames. This is the ground truth of business. This is the ground truth of enterprise computing. Now we will have AI use structured data. And we are going to accelerate the living daylights out of it."
Polars DataFrames are at the core of the AI revolution.
https://t.co/bs8Jb18rCg
We've released Python Polars 1.39. Some of the highlights:
• Streaming AsOf join
join_asof() is now supported in the streaming engine, enabling memory-efficient time-series joins.
• sink_iceberg() for writing to Iceberg tables
A new LazyFrame sink that writes directly to Apache Iceberg tables. Combined with the existing scan_iceberg(), Polars now supports full read/write workflows for Iceberg-based data lakehouses.
• Streaming cloud downloads
scan_csv(), scan_ndjson(), and scan_lines() can now stream data directly from cloud storage instead of downloading the full file first.
Link to the complete changelog: https://t.co/62Mx2ZJWVh
A one liner will route every .collect() call through the streaming engine: pl.Config.set_engine_affinity("streaming").
Put it at the top of your script and all subsequent .collect() calls will prefer the streaming engine. You can also pass engine="streaming" directly to a single .collect() call if you only want to opt in for only one query.
The streaming engine processes data in chunks rather than loading everything into memory at once. It's 3-7x faster than the in-memory engine, and for workloads that exceed available RAM it's the only viable option. We will soon set the streaming engine as the default engine, but this way you can already enjoy its benefits.
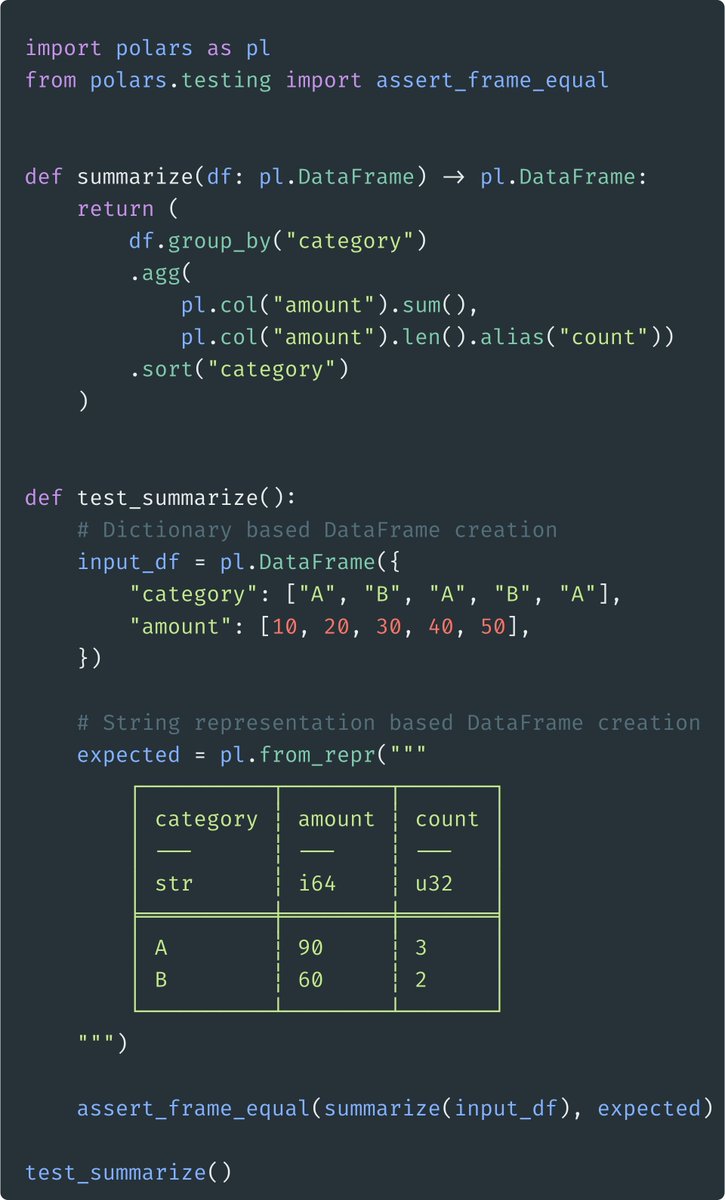
pl.from_repr() constructs a DataFrame or Series directly from its printed string representation. This can be useful in unit tests: instead of rebuilding expected DataFrames through dictionaries with typecasting, the schema is encoded in the header and the values are right there in the table. You can see at a glance what the test is asserting.
Easily scale Polars queries from @ApacheAirflow
Our latest blog post walks through different patterns to run distributed Polars queries using Airflow: fire-and-forget execution, parallel queries, multi-stage pipelines, and manual cluster shutdowns.
Read more here: https://t.co/Zixvy8oIpd
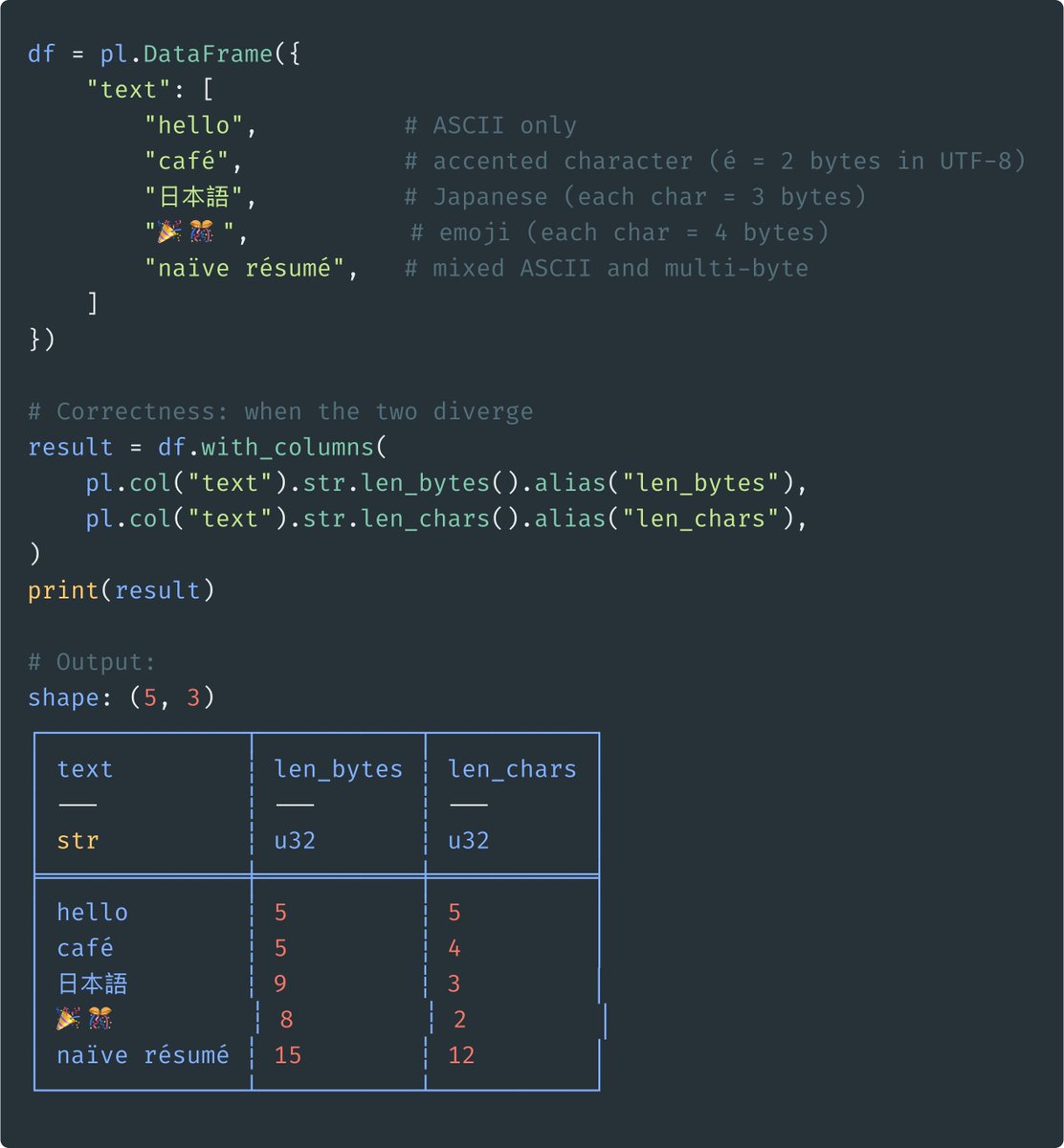
Polars exposes two ways to measure string length: str.len_bytes() and str.len_chars(). The difference matters more than you'd think.
In terms of precision: len_bytes counts raw UTF-8 bytes. len_chars counts Unicode code points. For pure ASCII text, they return the same number. However, the moment you have accented characters, CJK text, or emoji, they diverge. For example, Japanese characters take 3 bytes each. Emoji take 4.
In terms of performance: on a dataset with 5 million rows, len_bytes runs about 20x faster than len_chars. That's because determining the number of bytes is a single metadata lookup on the underlying buffer, which doesn't need to traverse (complexity: O(1)). len_chars has to walk every string byte-by-byte to find code point boundaries (complexity: O(n)).
So which one should you use?
• len_bytes: If you're working with guaranteed ASCII data (such as hashes, IDs, standard codes) ,when an approximation of the length is close enough, or when you need to know how many bytes the string takes in memory.
• len_chars: If your data contains any user-generated text, names, addresses, or anything multilingual, or you want to be sure of the precise and correct length.
Benchmark code: https://t.co/QCZeqw8zZ3