This one is for all the United fans and @MarcusRashford lovers. Created a dashboard showing our star boy’s stat so far in the 22/23 campaign. 🔥🔥🔥. Let me know your thoughts and which United player I should do next!!
Design was done by @daniel____aj
I worked on Data Engineering, Data Analytics, ML Engineering, MLOps, Agentic AI, and Frontend in the last 2 months.
Here’s what I learned in each area:
1. Data Engineering:
- Most important and evergreen role as data is the new crude oil.
- It’s more about designing orchestration flows than tools.
- Understand OLAP vs OLTP: it simplifies everything.
- Cover edge cases before optimizing.
- Data pipelines are hardest to debug, failures can take hours to surface.
- Batching and sharding are core principles.
- Vibe-coding works for syntax but you need deep pipeline knowledge.
2. Data Analytics:
- Use Polars instead of Pandas.
- Check nulls, skewness, outliers, value counts, basic stats.
- Segment data to show business behavior across groups.
- Use AI heavily to write code and create plots.
- Feed plots and stats to AI to generate reports.
- Automation becomes very easy with AI.
3. Machine Learning:
- Feature engineering is the most important part.
- Build models from a business perspective, not just ML metrics (which can be improved later).
- Start with simple models; if performance is decent, move to production.
- Monitor training closely.
- Automate inference logic and FastAPI endpoints with AI.
4. MLOps:
- More about system design and business/UI needs than tools.
- Docker, FastAPI, MLflow, and Redis are mandatory.
- AI writes modular code well but can miss loop logic and focus on edge cases like in data engineering.
- Kubernetes and AWS take real learning; vibe-coding confuses debugging.
- Terraform is your friend for shipping entire ML systems to any cloud, learn it now.
5. Agentic AI:
- Prefer orchestration tools like LangGraph and CrewAI.
- Use LangChain only for sub-modules.
- One vector DB, one LLM, and one embedding model are enough for any prototype.
- System design is critical you can’t build good agents without understanding UI and technical flow.
- Observability is essential to evaluate agent outputs.
- Coding is easy with AI.
6. Frontend:
- Just use AI. It’s already dead otherwise.
I’m planning my next big project on distributed LLMs. Stay tuned! You’ll love it.
Day 7 ✅ A commit every weekday.
Built NaijaPrep this week — AI meal prep for Nigerian professionals 🇳🇬🍲
🔗 https://t.co/B0I8cToQmA
💻 https://t.co/9htcllToIh
#BuildInPublic#NaijaPrep#AI#WebDev
Wish you could see your entire ChatGPT history in one place?
I built a small tool for a problem I kept hitting with ChatGPT.
I brain-dump ideas there, outline projects, and do research. Then months later I want to find that one conversation… and search does not help.
So I made ChatGPT Data Viewer.
What it does:
✅ Loads your ChatGPT data export
✅ Builds a local index
✅ Lets you browse history via a GitHub-like contribution calendar
✅ Fast full-text search across all conversations
Everything runs locally. No uploading your chats anywhere.
Preview video 👇
I wrote about the tool here: https://t.co/vUosCUjVUe
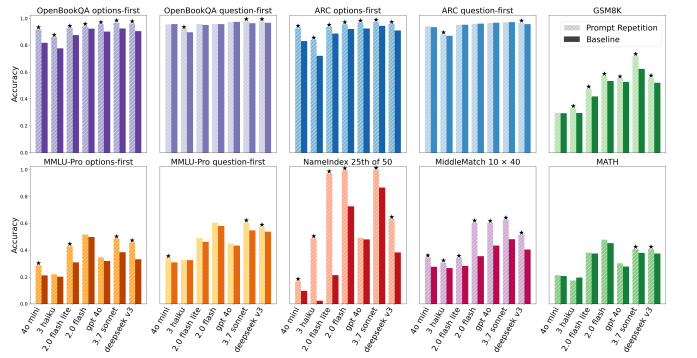
Day 3 Learning: Sometimes the simplest prompt hack wins.
Today I read “Prompt Repetition Improves Non-Reasoning LLMs” (Leviathan, Kalman & Matias, Google Research).
Big insight:
If you're not using reasoning, just repeat the entire prompt.
Instead of:
<QUERY>
Use:
<QUERY><QUERY>
Key takeaway for me:
Before adding complex techniques like chain-of-thought, try structural prompt tweaks. Sometimes the architecture’s constraints are the real bottleneck.
Day 2:
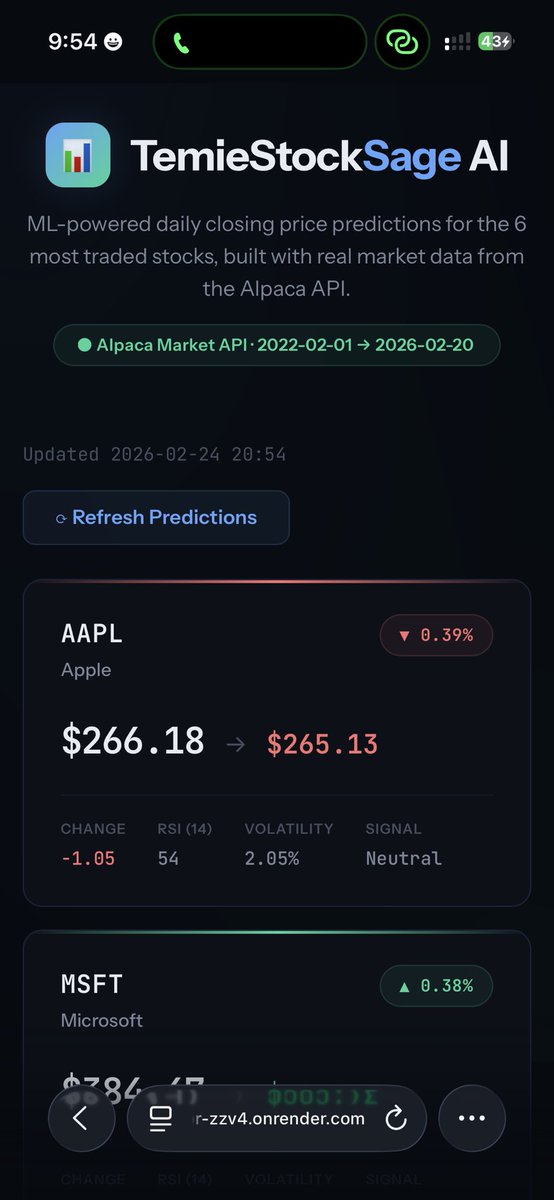
My ML stock predictor was predicting AMZN +147% in a single day. That’s not a prediction now is it?😂😂😂
You can interact with it: https://t.co/7g8Qnw9csO
Output:
The predictions now look like real markets.
Direction accuracy across 6 stocks: 46-55%. In a market that’s supposed to be random, I will take it.