Hello world!
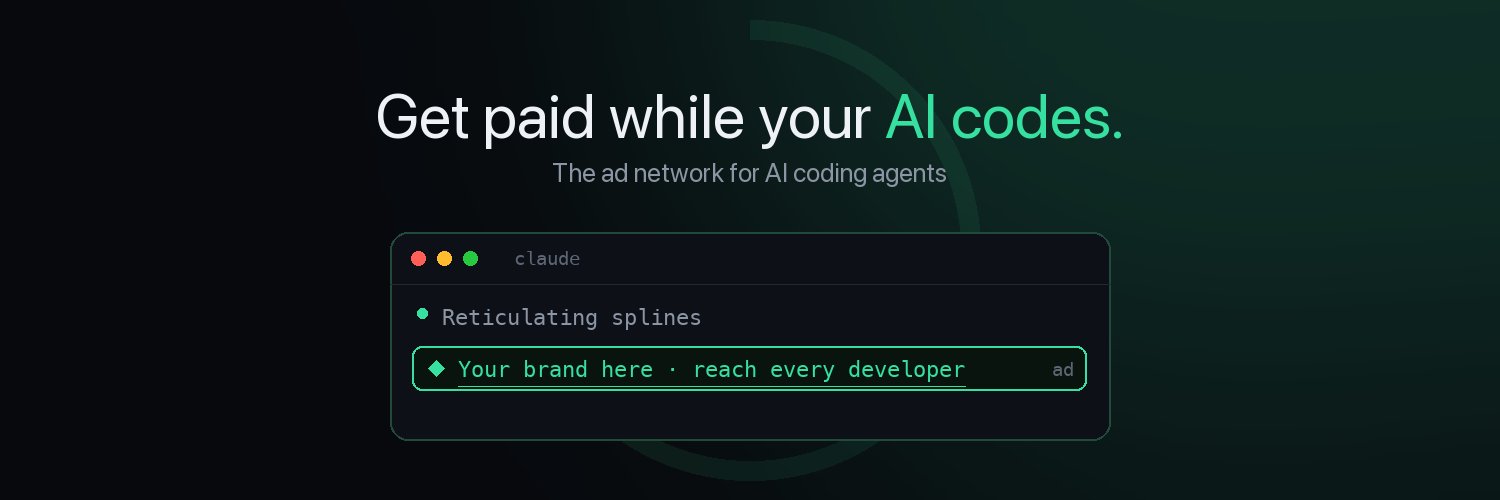
Introducing SpinnerPay - get paid while your AI codes.
One terminal command adds a clickable sponsored slot to your Claude Code spinner.
You keep 50% of the ad revenue.
Check out https://t.co/hnO3cuIvow
I met a 19 year old who makes $200,000+ building apps with AI and he can't even code.
1 year ago he was literally working at TJ Maxx.
He made a deck called "How to scale your app to $10k/month (easy mode)" and gave away the entire playbook on the pod:
1. Pick an idea you're actually passionate about. He proved this the hard way. The app he hated got 1.8M views and made $35. The app he loved made $17,000. Same month.
2. Build one "gotcha feature" anyone gets in 5 seconds. Take a picture of food, get calories. That's the whole pitch. 90% of distribution is nailing this. Gotcha features that include AI are working a lot right now.
3. Onboarding is where the money is. Educate, add social proof, personalize to create sunk cost, then hit them with FOMO right before the paywall.
4. Your IG is both a sales funnel for users and your credibility when pitching influencers. Three demos, clean bio, collab posts.
5. Distribution is a numbers game. Tailor your feed to your ideal customer, scroll and DM all day, hire a VA, get creators on the phone fast.
His name @GeorgeLampro20. It was fun hearing him share what is working in real-time from his POV.
Might get your creative juices flowing if building mobile apps with AI is exciting to you.
I love how simple his deck he showed is.
Full episode on @startupideaspod
Watch
The takeaway from Fable 5 being BANNED by the government: GET GOOD AT LOCAL MODELS SO YOU HAVE 100% CONTROL.
My entire weekend was going to be building my craziest ideas with Fable 5. That's now cancelled.
So instead of building with Fable this weekend, I've decided I'll go deep on local models:
1. Start with the runtime. Download Ollama or LM Studio first. This is the thing that actually runs models on your machine.
2. Match the model to your hardware. A model's size is measured in billions of parameters (7B, 32B, 70B). Bigger is smarter but needs more memory. Rule of thumb: a 7B model runs on almost any laptop, a 32B needs a good Mac with 32GB+ RAM, a 70B needs serious hardware like a DGX Spark or a maxed-out Mac Studio.
3. Know which model for which job. Qwen 3 is the best all-around choice for most tasks. DeepSeek for reasoning and coding. Gemma 4 when you need something tiny that runs on a phone. Llama when you want the biggest community and the most fine-tunes.
4. Quantization. You can shrink a model to run on weaker hardware with barely any quality loss. Look for versions labeled Q4 or Q5. This is how a model that "needs" a server runs on your laptop. Learning this one concept changes everything.
5. Connect it to your agent. Point Hermes or your agent stack at a local model.
6. Context window is your real constraint locally. Cloud models give you huge context for free. Local models make you pay for it in memory. A bigger context window eats RAM fast. Keep your sessions tight and your prompts lean or your machine chokes.
7. Learn to give local models tools. A smaller local model with web search, file access, and code execution beats a giant model with none. The capability gap closes fast when you wire up the right tools. The model is the engine but the tools are the wheels.
8. Fine-tuning is more accessible than you think. You don't need this on day one, but know it exists. You can take an open model and train it on your own data so it gets good at your specific domain.
I'll probably do a breakdown at some point on this @startupideaspod if people are into it.
The lesson from this ban is basically don't build your entire workflow on something that can disappear with a single letter. Own part of your stack. Local models are insurance.
It reminds me when people realized they don't own social media accounts. And then you saw people build email lists etc.
I remember running a startup and my biggest traffic source was organic FB. All of a sudden, algo changed, and I lost 99% of my traffic.
Same sorta moment (but bigger) for AI.
This is a wake up call.
The takeaway from Fable 5 being BANNED by the government: GET GOOD AT LOCAL MODELS SO YOU HAVE 100% CONTROL.
My entire weekend was going to be building my craziest ideas with Fable 5. That's now cancelled.
So instead of building with Fable this weekend, I've decided I'll go deep on local models:
1. Start with the runtime. Download Ollama or LM Studio first. This is the thing that actually runs models on your machine.
2. Match the model to your hardware. A model's size is measured in billions of parameters (7B, 32B, 70B). Bigger is smarter but needs more memory. Rule of thumb: a 7B model runs on almost any laptop, a 32B needs a good Mac with 32GB+ RAM, a 70B needs serious hardware like a DGX Spark or a maxed-out Mac Studio.
3. Know which model for which job. Qwen 3 is the best all-around choice for most tasks. DeepSeek for reasoning and coding. Gemma 4 when you need something tiny that runs on a phone. Llama when you want the biggest community and the most fine-tunes.
4. Quantization. You can shrink a model to run on weaker hardware with barely any quality loss. Look for versions labeled Q4 or Q5. This is how a model that "needs" a server runs on your laptop. Learning this one concept changes everything.
5. Connect it to your agent. Point Hermes or your agent stack at a local model.
6. Context window is your real constraint locally. Cloud models give you huge context for free. Local models make you pay for it in memory. A bigger context window eats RAM fast. Keep your sessions tight and your prompts lean or your machine chokes.
7. Learn to give local models tools. A smaller local model with web search, file access, and code execution beats a giant model with none. The capability gap closes fast when you wire up the right tools. The model is the engine but the tools are the wheels.
8. Fine-tuning is more accessible than you think. You don't need this on day one, but know it exists. You can take an open model and train it on your own data so it gets good at your specific domain.
I'll probably do a breakdown at some point on this @startupideaspod if people are into it.
The lesson from this ban is basically don't build your entire workflow on something that can disappear with a single letter. Own part of your stack. Local models are insurance.
It reminds me when people realized they don't own social media accounts. And then you saw people build email lists etc.
I remember running a startup and my biggest traffic source was organic FB. All of a sudden, algo changed, and I lost 99% of my traffic.
Same sorta moment (but bigger) for AI.
This is a wake up call.
Our room for the coming days in Houston. I don’t even know what to say about this. This is just unreal. No words.
Huge huge thank you to JJ Watt for giving me and my friends the opportunity to stay at a place like this🙏🙏🙏
My Instagram timeline is filled with international visitors experiencing America for the first time for the World Cup and I can’t get enough of it.
It’s so wholesome!
@FreddyLA7 and @shaunvlog_ keep it coming! Thanks for documenting your journey here! I love it all!
Great breakdown from @gregisenberg as always!
And remember, if you are still coding with Claude code in your terminal - use https://t.co/hnO3cuIvow to make money.
Fable is banned. Long live local AI.
Full episode breaking down exactly how to get good at local models. the runtime, the hardware, quantization, connecting it to Hermes agent and local AI startup ideas (25 minutes)