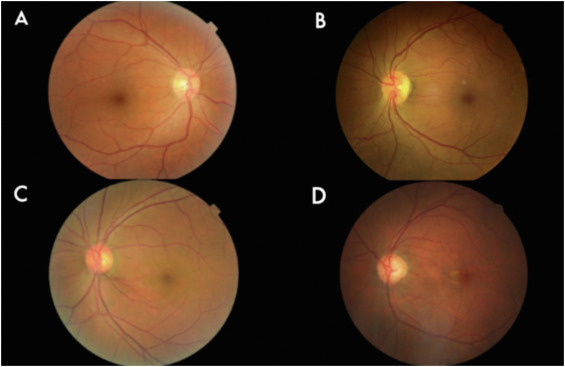
Ophthopedia Update: Risk of Retinal Detachment After Intravitreal Injection of Anti-VEGF: A Systematic Review and Meta-Analysis https://t.co/aZoXd8XDEw #Ophthalmology#Ophthotwitter#Scicomm
Researchers are demonstrating that large language models can be used to support the diagnosis and management of a variety of eye conditions. https://t.co/lPZ2awES11 #AIinMedicine#Ophthalmology#DigitalHealth
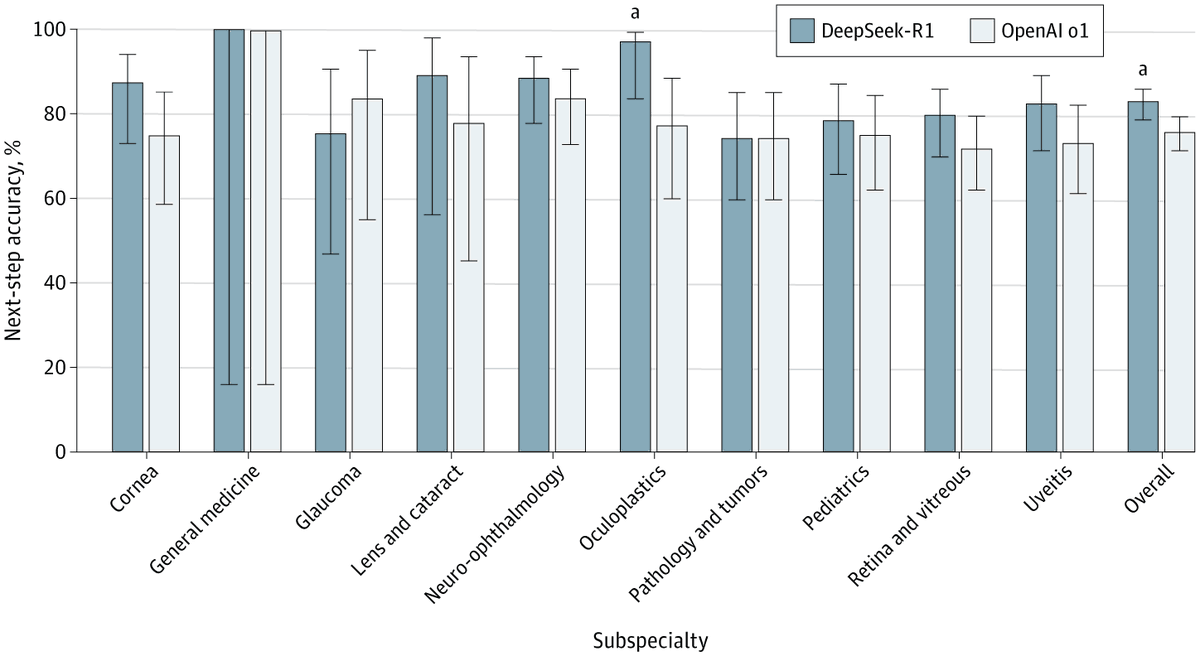
DeepSeek-R1 demonstrated superior performance compared to OpenAI o1 in clinical diagnosis and management across subspecialties, while also reducing operating costs.
https://t.co/oIe1NOnpjh
DeepSeek-R1 demonstrated superior performance compared to #OpenAI o1 in clinical diagnosis and management across subspecialties, while also reducing operating costs. https://t.co/FomIrl2uTw @DanielMiladMD@FaresAntaki@theMichaelBalas@pearsekeane
GPT-5 (with high reasoning effort) achieves near-perfect accuracy on a high-quality ophthalmology question-answering dataset.
Based on these other reports, GPT-5 seems to be a very strong model at medical reasoning.
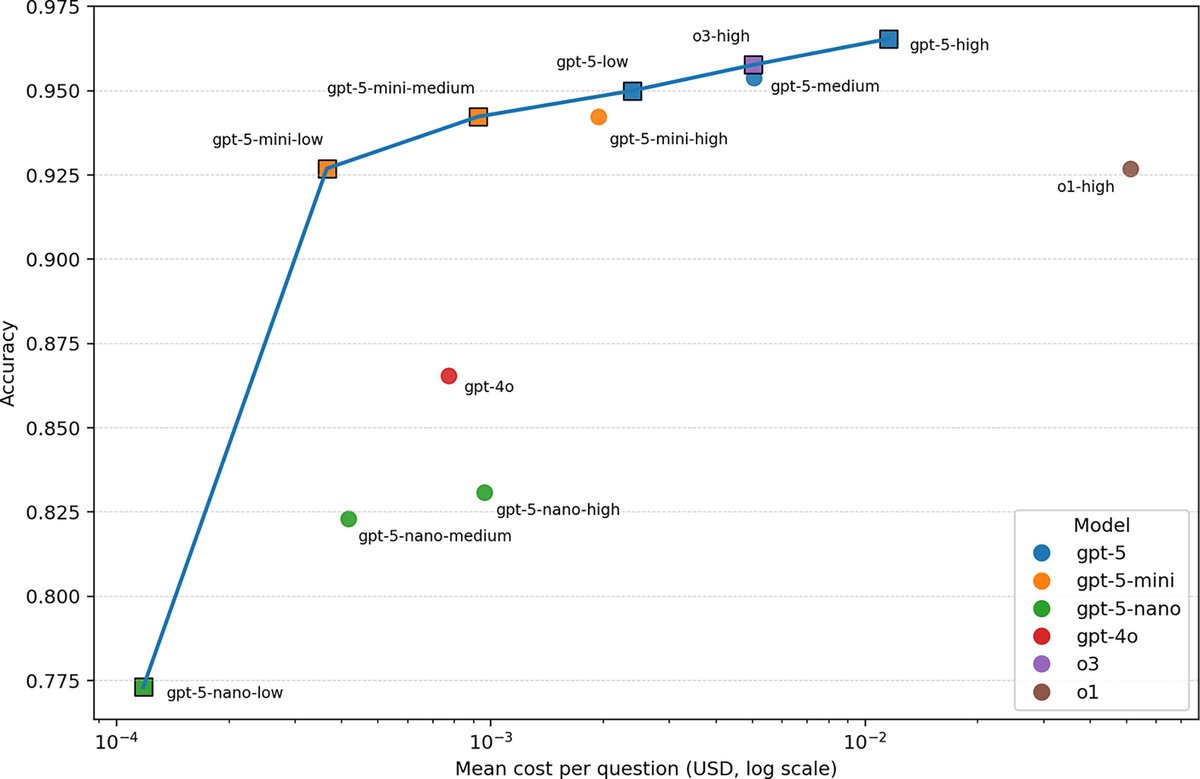
GPT-5 delivers near‑perfect ophthalmology answers, and the mini‑low mode gives the best accuracy per dollar.
The study pits 12 GPT‑5 configurations against o1, o3, and GPT‑4o on 260 closed American Academy of Ophthalmology Basic and Clinical Science Course questions, then checks accuracy and explanation quality.
Questions were answered with no examples in the prompt, and each reply had to be a single letter plus a 1‑sentence justification, so grading stayed strict and simple.
GPT‑5 exposes a “reasoning effort” control, from low to high, that increases the model’s private thinking tokens before it speaks, the minimal setting underperformed and was dropped.
Top result, GPT‑5‑high hit 96.5% accuracy, o3‑high scored 95.8%, o1‑high 92.7%, GPT‑4o 86.5%, while GPT‑5‑nano‑low trailed at 77.3%.
Head‑to‑head strength was estimated with a Bradley‑Terry model, which turns pairwise wins into a single “skill” score, GPT‑5‑high was 1.66x stronger than o3‑high and 5.10x stronger than o1‑high on accuracy, and 1.11x stronger than o3‑high on rationale quality.
Rationales were graded by an LLM judge that compared each 1‑sentence explanation to the official reference text and picked the closer one, which scales cleanly beyond small human panels.
Cost mattered, plotting accuracy against mean cost per question showed a Pareto frontier from GPT‑5‑nano‑low to GPT‑5‑high, and GPT‑5‑mini‑low sat on that frontier as the best low‑cost high‑performance point, meaning nothing else was both cheaper and more accurate.
Practical read, GPT‑5‑high fits settings where every point of accuracy matters, GPT‑5‑mini‑low fits budgeted scale, and GPT‑5‑medium tracks close to o3‑high on performance and cost.
----
Paper – arxiv. org/abs/2508.09956
Paper Title: "Performance of GPT-5 Frontier Models in Ophthalmology Question Answering"
🚨 Excited to share our new preprint benchmarking OpenAI’s GPT-5 series for ophthalmology question answering.
Using the AAO BCSC dataset, we tested GPT-5 (including mini & nano) across four reasoning levels vs three older LLMs. GPT-5 with high reasoning scored an impressive 96.5%, ranking first in our LLM arena for both accuracy and justification quality. The most cost-efficient configuration was GPT-5-mini with low reasoning. We also introduce a scalable new method for evaluating long-form answers using LLM-as-a-judge autograding.
🔗 https://t.co/syLfmzHPFd
@DanielMiladMD@SumitSharmaMD@pearsekeane@YihTham
Excited to share our systematic review + meta-analysis published in @AJOphthalmology evaluating AI models for epiretinal membrane (ERM) diagnosis.
Check it out! https://t.co/Zu1YGmrCbq
Could clinicians with no coding experience build their own AI models for detection of glaucoma?
Our colleagues present a persuasive proof-of-concept study ⬇️