The Flyte 2.0 SDK is officially here: This release brings some really exciting local development features that you can right out of the box even with connecting to Kubernetes or Docker!
The features I've been loving to my local AI workflows:
- Terminal User Interface (live workflows and history)
- HTML Reports (tracks to workflow version
- Caching (skip rerunning a task by reading from cache)
- Retries (auto retry a task if it fails - super useful for API calls)
- And more
All this together gives you:
- great lightweight experiment tracking
- a lift in reliability
- a great interface for debugging large pipelines or AI agent runs
I can't wait to show you whats next in both Flyte and @union_ai
It's that time of the year again when I pack my bags and tackle the 21hr journey to meet my awesome colleagues at @union_ai's HQ. As usual, I try to use the time to take on my reading backlog while people around are watching Netflix 😅
@abarbap Que bueno que a alguien mas le guste!
Hace poco redescubri la Eroica dirigida por Barenboim. Escucharla con Apple Music Classical en Dolby Atmos, es toda una experiencia.
@DominikTornow Thank you. I thought in Chapter 2 you'd build an agent from scratch, no frameworks. I've struggled to find a resource like that 😀
Anyways, eagerly awaiting (pun intended) any new chapter.
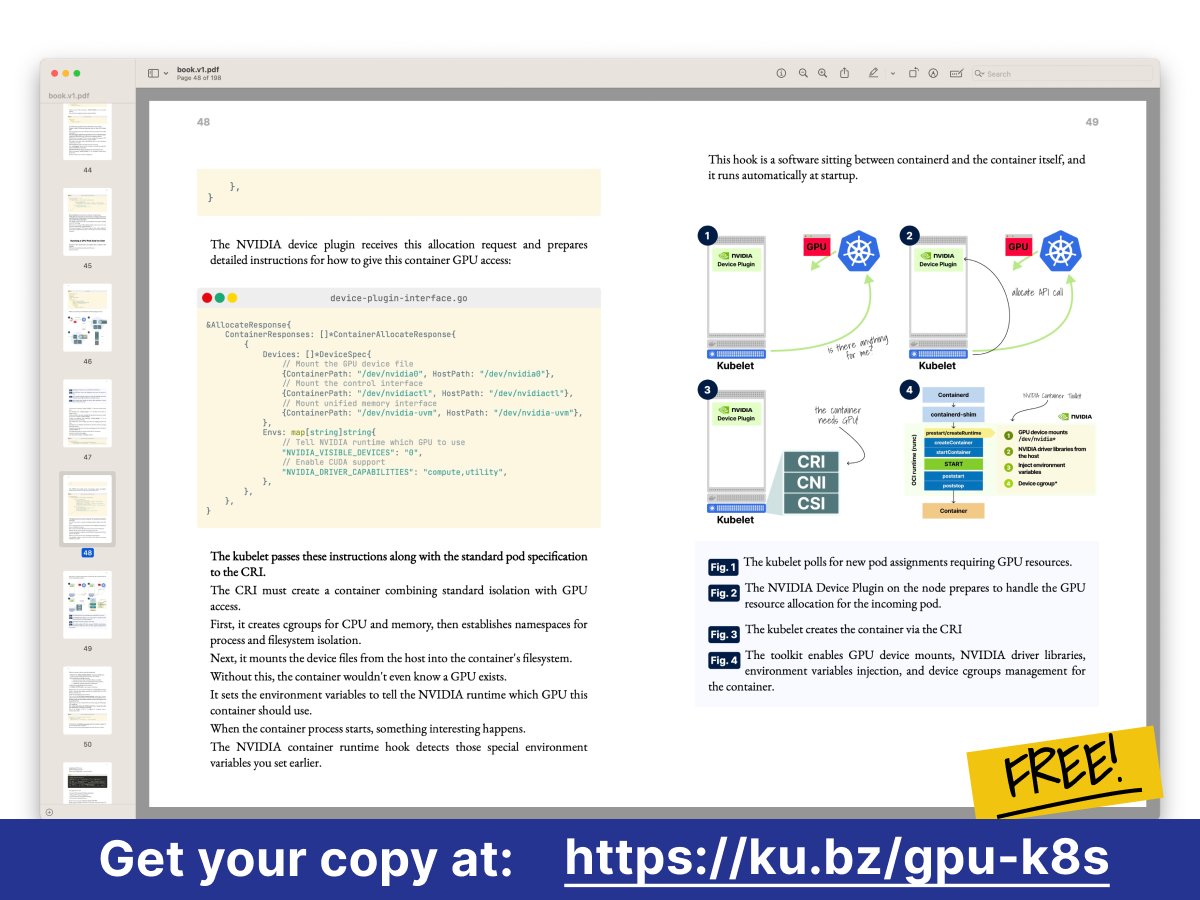
🚀📕 The GPU + Kubernetes book is finally here. After six months of rabbit holes, I finally understood why this problem was so hard.
When I started, I thought GPUs were just fancy parallel processors. Mount the device, set some resource limits, and done. Then I learned that GPUs can't even pause a running kernel. Once computation starts, it runs to completion - no preemption, no time-slicing in the CPU sense, nothing. The hardware was designed this way for maximum throughput, and no amount of software can change it.
This fundamental difference breaks every assumption Kubernetes makes about resources. The Linux kernel sees and controls every CPU cycle and memory page. But GPU operations? They happen in a black box managed by the NVIDIA driver. The kernel is completely blind.
So I wrote this book. Six chapters that trace the problem from hardware to orchestration:
1️⃣ Why containers work beautifully for CPUs (syscalls, cgroups, namespaces) and why GPUs break every one of these assumptions. You'll understand exactly how device plugins trick Kubernetes into accepting GPUs it can't actually manage.
2️⃣ How traditional Kubernetes isolation completely fails for GPUs. When two pods share a GPU, there's no cgroup enforcement, no memory isolation, nothing. One pod can crash everything.
3️⃣ The truth about "GPU sharing" tools. KAI-Scheduler and NVIDIA's "time-slicing" don't share anything - they just orchestrate turn-taking. Your pods still wait in line for exclusive GPU access.
4️⃣ MIG vs HAMi vs vGPU. When you actually need hardware partitioning (spoiler: probably never), and why seven T4s might serve you better than one H100 with MIG.
5️⃣ Why nvidia-smi lies to you, Kubernetes metrics lie differently, and DCGM reveals that 60-70% of your GPU budget is wasted on idle resources.
6️⃣ How to share GPU clusters across teams without namespace chaos. Virtual clusters give each team its own control plane while efficiently sharing the underlying hardware.
Download the free book here: https://t.co/qzbxkjFegw
Huge thanks to Saiyam who co-authored this, bringing real production experience I lacked. To the vCluster team (Rahul Patwardhan!!!) who believed in this project and sponsored my research time. And to Gulcan who edited countless drafts into something readable.
💡 If you want to go deeper, join me for a live discussion this Wednesday, where I will answer your GPU questions and explain how the book came to be https://t.co/GKzqH1anYY
Amazon S3 Vectors + Flyte 2.0 = simpler, cheaper AI pipelines
Flyte 2.0 users can now use S3 Vectors.
That means no separate vector database, cut up to 90% of related costs, fewer moving parts to manage.
Learn how it works: https://t.co/sWQJGCTp7u
#S3#orchestration#agents
✈️ Introducing Flyte 2.0 ✈️
Dynamic, crash-proof, resource-aware AI orchestration.
Plus, a fully functional agent runtime. This is big.
Learn more and access the beta:
https://t.co/RKc6M8Os3n
Pandera passed 100 million downloads this weekend!
(not the sandwich shop, the open source data validation project)
Huge thanks to our incredible OSS community at https://t.co/BXih2WRJID.
Here’s to 100 million more!
https://t.co/KwYGxOftmr
@ketanumare Agree :)
The fact that objects bring immutability and simplicity is maybe what contributed to S3's unparalleled success. Design decisions that remain right 19 years after its inception are a good substrate to build on!
🚨We’re at GTC (booth 2022) with a huge announcement—Union now serves AI models and apps!
Learn common AI serving mistakes in our whitepaper: https://t.co/PnrCBhRhfb
Union serves 2x faster than SageMaker, in any cloud.
#GTC2025#MLOps#Serving#Inference#CompoundAI
🚀 Exciting news! Union is heading to #gtc2025 next week! 🎉
Join us at Booth 2022 to see how we’re revolutionizing AI workflows and model serving. Want to see it in action? Want to learn how Union can Unify your AI Development?
🔗 Book a chat: https://t.co/1JGM3K9xzl
How is AI orchestration powering the future of #bioinformatics? Union’s platform empowers researchers to tackle computationally intensive problems like protein folding with ease, scalability, and precision. Learn more in our latest blog. #ML https://t.co/bLKNQUTNpH
@akshaykagrawal@themylesfiles Very interesting, thanks for sharing!
Also, check out how we're also trying to add reproducibility, versioning, and container-based execution environments to Notebooks
https://t.co/Gh556U2OmC
Just tried @genmoai's Mochi model for video generation on @union_ai serverless with an A100 GPU 🎥✨
The video quality is impressive! Check it out: https://t.co/OANDjiQU64