Here's an attempt at posting the brochure for my course offerings this year. If you're interested in Modern DiD, Advanced Multilevel Modeling, and Bayesian Multilevel Modeling then take a look. You can register on my website or @ICPSRSummer
I am teaching my Causal Inference in Econometrics asynchronous workshop with Statistical Horizons from April 13-May 11 of this year. Learn about the tools of causal inference and go at your own pace. Get more info, and sign up if you're interested, here:
https://t.co/Z6N9DF9yG2
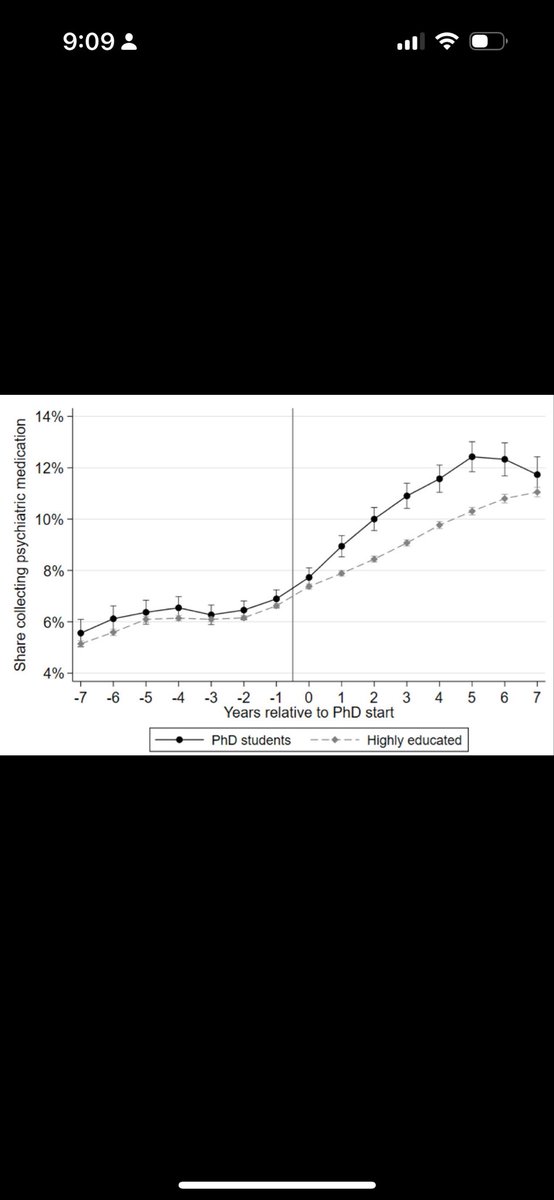
These results suggest that getting a PhD causally worsens mental health, or at least receiving psychiatric medicines. The reversal post PhD degree is particularly convincing.
But the up trend among the control group is intriguing. The highly educated are in distress.
1/ Our meta-analysis of 49 top political science publications using two-way fixed effects (TWFE) models w/ panel data is conditionally accepted at American Political Science Review. [https://t.co/mmEJdumNHJ] w/ @itsalbertchiu@liuziyi233@Lan1Xingchen 🧵
Somewhere along the way “correlation is not causation” morphed into “until the causal link is proven beyond a reasonable doubt, ideally with a large scale RCT with global external validity, than the correlation likely reflects the impact of some unobserved factor I can’t name.”
@PhDemetri What makes it so interesting to you? I know the basics of it from going down a rabbit hole of shrinkage techniques, but I've never actually used it for anything.
@stephenjwild It's more or less how I write equations with specific examples for course notes. The big difference is I align the + with one object on each line vertically. Looking at this makes my skin crawl
Is it really true that, for something like Poisson regression with panel data -- say, in a nonlinear diff-in-diffs setting -- R does not allow an option for clustered standard errors within the command? If so, that's a serious shortcoming of R. Big win for Stata.
@AdanBecerraPhD @jmwooldridge@pedrohcgs@EpiEllie@ajordannafa@camjpatrick I say go with whichever you think you can most clearly describe the substantive effect. By convention that's going to be something like ATT or ATE but if you can talk about it in predictive terms as expected additional $ or something then it doesn't hurt
@AdanBecerraPhD @jmwooldridge@pedrohcgs@EpiEllie@ajordannafa@camjpatrick You mean the coefficients are different? Because they would almost have to be since they're on different scales. But if you calculate marginal effects after they should be the same as the ols coefficients
@AdanBecerraPhD @jmwooldridge@pedrohcgs@EpiEllie@ajordannafa@camjpatrick Nothing wrong with that in principle but since everyone talks about ATEs or something similar you'd end up having to report marginal effects anyway just to communicate the results. At that point you're just using a linear model with extra steps
@stephenjwild@rubenarslan GLMs are really fragile to model misspecification to begin with so they'll be more likely to break if you enter don't model a random effect or you get the wrong distribution of the REs from whatever tool you're using to estimate it
@rubenarslan Your intuition is partly right. In cases where you've got Simpsons paradox and don't use group means then the random slope will help debias the main effect some but not totally. Otherwise it's just showing you that there is variation in effects around the average.
I'm teaching my Modern DiD class for @ICPSRSummer in a few weeks. Reviewing my notes reminds me how quickly this literature has grown! I think im going to have to add in a lecture just for strategies to keep track of updates
This is a must-read for anyone interested in causal inference methods, especially if TMLE or DML are opaque to you. Well written as always @ildiazm. Your clarity, rigor, and expertise are inspiring.
It's INCREDIBLE that longitudinal admin data on tax records, recidivism, health, and much more, are now publicly and freely available. Wow! So many diff in diffs to run!! Congratulations @UM_CJARS! I am proud to have you as my colleagues!



























![xuyiqing's tweet photo. 1/ Our meta-analysis of 49 top political science publications using two-way fixed effects (TWFE) models w/ panel data is conditionally accepted at American Political Science Review. [https://t.co/mmEJdumNHJ] w/ @itsalbertchiu @liuziyi233 @Lan1Xingchen 🧵 https://t.co/BDxaTis5nE](https://pbs.twimg.com/media/GilpngfbYAEGVZt.jpg)
























