Founded in 2019, DeepRoute is dedicated to the research, development and application of autonomous driving technology, with a mission to create AGI in robots.
Physical AI isn't a concept. It's what we ship.
• 300K vehicles deployed
• 1.3B km real-world data
• Near hourly system updates
Every km makes us stronger.
Next stop: million-scale by 2026. 🚀
Come experience it till May 3:
📍 Booth A410 (Hall A4)
#PhysicalAI#AutoChina2026
Happy to share our latest from #AutoChina2026: DeepRoute Physical AI 🚀
Our 3 Leaps:
🧠 Cognitive: 40B Foundation Model
⚡️ Efficiency: 10x Faster AI Loop
⚙️ Organizational: Human-AI Synergy
📍 See it at Booth A410 (Hall A4)
#DeepRoute#PhysicalAI
Auto China 2026 is here! 🚗 Join https://t.co/1Cdnzaqlgs as we unveil the next chapter of #PhysicalAI and our mass-produced #AutonomousDriving solutions. Peace of mind, woven into every journey.
📍 Booth A410, Hall A4, CIECC
📅 Apr 24 - May 3, 2026
See you in Beijing! 👇
#AI
Proven at scale:
📊 ~40% monthly market share
🚗 250,000+ vehicles delivered
🎯 Targeting 1M+ by 2026
From Urban Autonomous Driving to Robotaxi — the ultimate purpose of technology: peace of mind on every journey.
#GTC2026#PhysicalAI#AutonomousDriving
The 40B Foundation Model — a unified "brain" for autonomous driving.
Perception. Reasoning. Action. Seamlessly integrated.
And by cutting the data cycle from 5 days to just 12 hours, we've unlocked a new paradigm for scalable AI. ⚡
#FoundationModel#AI#DeepRouteAI
Insights from #NVIDIAGTC 2026! 🚀 https://t.co/1Cdnzaqlgs is scaling the future:
🔹In AI We Trust, In Scaling We Thrive. Redefining AD boundaries.
🔹10x efficiency: Data cycle compressed to 12 hours.
Explore the next frontier of autonomous driving. 🚗 #DeepRouteAI
🚗 Our CTO Tongyi Cao speaks at #NVIDIAGTC 2026: Redefining Autonomous Driving with a 40B VLA Foundation Model.
200K+ vehicles. One flywheel: Model × Data × Simulation → L5.
https://t.co/1Cdnzaqlgs = Future Mobility in Action
📅 Mar 17, 4 PM Beijing / 1 AM PDT
📍 Booth 1744
When AI begins to understand the world, driving becomes about anticipation, not reaction.
Construction signs
Text-based road guidance
Human gestures
Blind spots & irregular obstacles
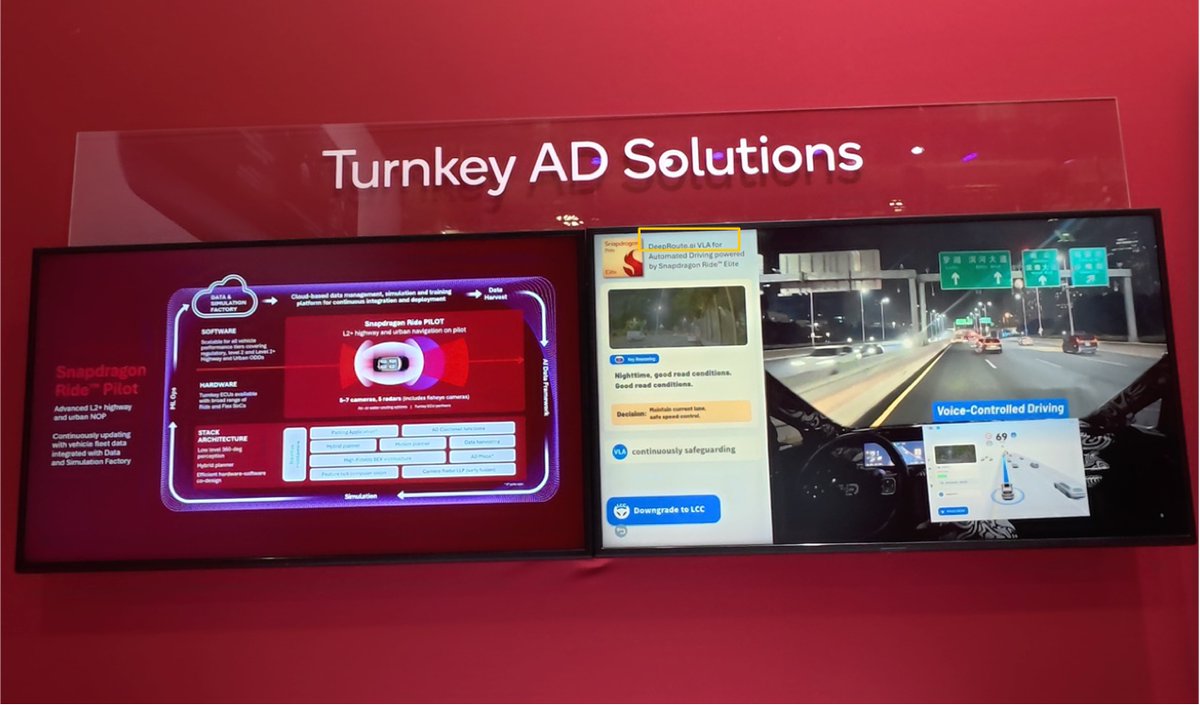
VLA (Vision-Language-Action) models turn perception into reasoning, and reasoning into safety.
Automotive KOL E-CoreChannel test-drove a production vehicle with https://t.co/1CdnzapNqU’s VLA model in a Guangzhou urban village—one of the toughest urban environments.
One take. No edits. VLA is already in mass production.#autonomousfuture#AI#LLMs
The autonomous driving industry is going through tough times. What’s next? Reasoning.
Our CEO Maxwell Zhou at BAIC’s forum: Real breakthrough isn’t about more sensors, but AI that understands why. We’re building the AI driver that thinks like a human.
#AI#AutonomousDriving
https://t.co/1Cdnzaqlgs's VLA Model has now entered mass production deployment. 🚘
With enhanced defensive capabilities, the system is designed to deliver safer journeys across everyday road conditions, a critical step toward scalable autonomous driving solutions.#AI#Automotive
Our Technology Partner Liu Xuan spoke at Melbourne AI Governance Forum: “Autonomous driving has the strictest safety requirement in AI.” https://t.co/EV2gwRYoeR is proving that safety and scale can coexist with VLA and 200K+ cars delivered.🚗
#AutonomousDriving#AIGovernance
https://t.co/EV2gwRXQpj hits a new stride: 200K urban autonomous driving systems delivered in just 14 months, with 40% share in October. CEO Zhou Guang said, “For automakers building the future of urban autonomy, https://t.co/EV2gwRXQpj is a key player.”
https://t.co/FGcOP5uUV3