The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: https://t.co/bwn0sximKZ
30 anos.
Por 30 anos o PC foi a mesma coisa: Intel ou AMD dentro, GPU do lado, e torce pra não travar.
A NVIDIA acabou com isso numa keynote.
RTX Spark. Primeiro chip deles para computador pessoal. CPU, GPU e memória num único silício. ARM, 3nm, 1 petaflop de IA local.
Num laptop de 14mm.
Rodou Forza Horizon 6 e 007 First Light no palco a 100 FPS em 1440p. Fora da tomada. Sem throttling. No Windows.
O número que muda tudo: roda modelos de IA de 120 bilhões de parâmetros sem cloud. Sem API. Sem assinatura. Seu agente de IA mora na sua máquina. Ligado 24 horas. Só seu.
O PC não é mais uma tela com teclado. É uma estação de IA pessoal.
> ser empresa big tech
> demitir funcionários pra economizar usando IA
> dar Claude Code pros engenheiros
> engenheiros começarem a usar IA
> pra literalmente tudo
> geração de código
> debug
> automação
> documentação
> workflows inteiros
> conta mensal começar a parecer orçamento militar
> descobrir que milhares de funcionários usando IA
> ao mesmo tempo custa absurdamente caro
> entrar em pânico
> mandar todo mundo voltar pro GitHub Copilot
a parte mais engraçada da era da IA é que as empresas talvez tenham criado uma tecnologia tão útil…
que agora nem elas conseguem pagar direito pra usar em escala
Microsoft just banned its own engineers from using AI.
The tool was literally costing MORE than the humans it was supposed to replace.
They lied to you about AI adoption and now the whole narrative is blowing up:
Microsoft gave thousands of engineers access to Claude Code six months ago and encouraged them to use it.
Engineers loved it and adoption exploded. But then the invoices arrived.
Token-based pricing means every query, every code review, every debugging session costs money. At scale across 100,000 engineers, the numbers became so large that Microsoft issued an internal order to cancel nearly all Claude Code licenses by end of June and force everyone onto their own cheaper tool instead.
The company that invested $5 billion in Anthropic just told its own people to stop using Anthropic's product because it costs too much.
Uber's story is even worse...
Their CTO Praveen Neppalli Naga told The Information that the budget he planned for the full year was "blown away already" by April.
Uber had rolled out Claude Code in December 2025. By March, 84% of their 5,000 engineers were using it with 70% of all committed code coming from AI systems.
Heavy users were burning $500 to $2,000 per month each. Naga himself spent $1,200 in a single two-hour demo session.
The company had even built internal leaderboards ranking engineers by how much AI they used. They literally gamified the spending and then ran out of money.
Now look at what Nvidia's own VP of applied deep learning Bryan Catanzaro said to Axios last month. Direct quote:
"For my team, the cost of compute is far beyond the costs of the employees."
This is a VP at the company that SELLS the chips saying that using AI is more expensive than paying humans.
Think about what this means for the entire AI narrative.
Every CEO on every earnings call for the past two years has said the same thing:
AI will make us more efficient, reduce headcount, and cut costs.
The stock market rewarded every company that said it.
Fired workers, stock goes up. Announced AI adoption, stock goes up.
But the actual companies deploying AI at scale are discovering the math doesn't work. The MORE employees use AI, the HIGHER the bill.
Goldman Sachs forecasts a 24x increase in token consumption by 2030 as companies adopt AI agents. Gartner just published a report showing that even though individual token prices will drop 90% by 2030, total enterprise AI costs will go UP because agents consume exponentially more tokens per task than basic tools.
Meta built an internal dashboard called "Claudeonomics" to track which employees use the most AI. Amazon started pushing engineers to "tokenmaxx," their internal term for consuming as many AI tokens as possible.
Both companies are spending hundreds of billions on AI infrastructure this year alone.
And Microsoft, the company that bet its entire future on AI, just told 100,000 engineers to stop using the tool they liked best because the per-token bills got out of control.
The companies building AI are telling investors it saves money. The companies using AI are finding out it costs more than the humans it was supposed to replace. And even the company that makes the chips just admitted it through its own VP.
This is the gap nobody on Wall Street is pricing in.
$725 billion in AI infrastructure spending this year across Big Tech. And the first companies to actually deploy these tools at scale are already pulling back because the economics don't work.
What do you think?
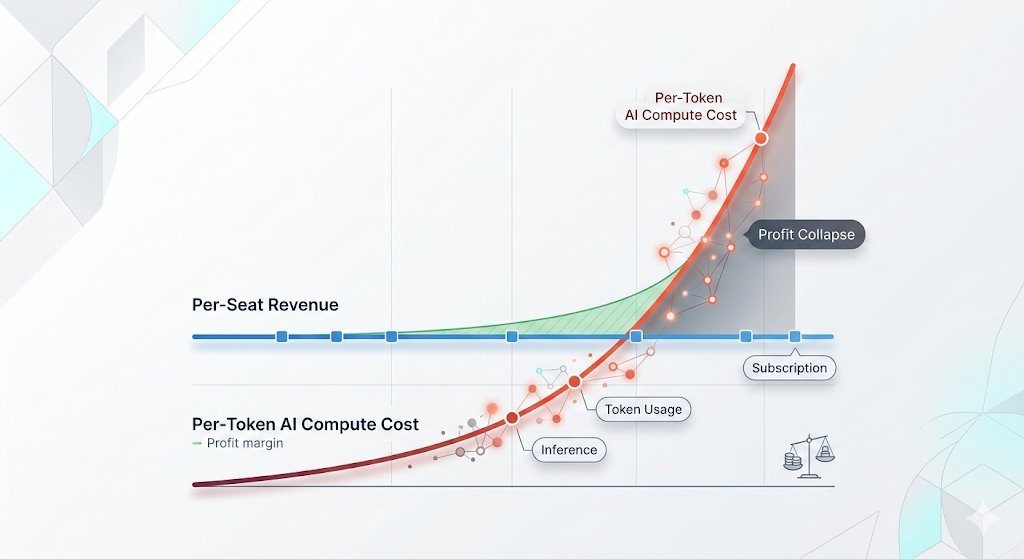
🦔Microsoft canceled its internal Claude Code licenses this week after token-based billing made the cost untenable, even for a company with effectively infinite cloud resources. Uber's CTO sent an internal memo warning the company burned through its entire 2026 AI budget in just four months. American AI software prices have jumped 20% to 37%, and GitHub (owned by Microsoft) is dropping flat-rate plans for usage-based billing across its products.
My Take
The AI subsidy era is ending in real time. The same company that put $13 billion into OpenAI and built the Azure infrastructure powering most of Anthropic's compute just looked at the bill from a competitor's coding tool and decided it was not worth paying. That is not a productivity failure on Anthropic's end. Token-based pricing is forcing every enterprise customer to confront the actual cost of running these models at scale, and the number turns out to be far higher than the flat-rate experiments suggested.
This ties directly to my Gemini Flash post yesterday. Anthropic, OpenAI, and Google all raised effective prices in the last six months. Enterprises that built workflows assuming AI costs would keep falling are now watching annual budgets evaporate in months. Two outcomes look likely from here. Either enterprises scale back AI usage to fit budgets, which slows the revenue ramp the labs need to justify their valuations ahead of IPOs, or the labs cut prices and absorb the losses, which makes the unit economics worse at exactly the wrong moment. Both paths land in the same place, the numbers stop working, and somebody has to take the writedown.
Hedgie🤗
Claude Code suddenly makes WAY more sense after installing this official Anthropic plugin 🤯
It reads your entire project and instantly tells you what you should actually enable, use, and configure.
The crazy part?
Most people using Claude Code don’t even know this exists.
→ Detects your stack automatically
→ Understands your codebase structure
→ Suggests the right workflows
→ Removes the confusing setup phase
→ Makes Claude Code feel 10x smarter
This is probably the real onboarding Claude Code needed 🔥
AI companies really need to come up with a better pitch to the public than “You’re all gonna lose your jobs and end up paying way more for electricity”.
A preview for Pro users: a new personal finance experience in ChatGPT.
Pro users in the U.S. can securely connect financial accounts, see where their money is going, and ask questions based on the information they choose to connect.
Your full financial picture, now in ChatGPT.
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
@vmzucher Esses full-stack da allura estão complicados. Agora esses caras com IA acham que fazem algo que preste aí já ficam se achando pop-star. Quero distância disso.
@heliotsx Com certeza né minha máquina pessoal é um Mac Pro m4 max. Quando eu uso depois do expediente dá até vontade de chorar de tanta emoção. Build em segundos fluidez acesso liberado a tudo 🥲