My plead for using #privacy friendly communication is now already available in 3 languages: Nederlands 🇳🇱, Español 🇪🇸 & English 🇬🇧 https://t.co/HrVPxPzdKa
No. Training LLMs on purely factual data STILL WON'T cure them of "Hallucinations" #SundayHarangue
There is a persistent myth that LLM hallucinations are just a result of them being trained on un-curated and "non-factual" data, and will go away with high quality/factual data. This misses the basic n-gram structure of LLMs.
Yes, the presence of "non-factual" training data does increase the chance of producing "non-factual" completions.
But, even if you train LLMs only on factual data (and I will suspend my disbelief for a minute about the impossibility of doing that in a multi-polar world), LLMs can and will still continue to produce completions that are not factual!
A simplistic way to visualize it is this: Imagine you have access to a 1000 curated wikipedia documents. Don't you think that by selectively cutting pasting from those documents, you can generate an inaccurate/not-fully-factual new one?
This happens because LLMs are completing the prompt probabilistically conditioned on the training corpus ("approximate retrieval") rather than indexing and retrieving like (the boring and much maligned) databases! (See https://t.co/qMJxiOCMGI; quoted below).
The fact that factuality of the training data is not sufficient to avoid hallucinations is demonstrated in multiple ways in the current LLM usage patterns:
(1) When you ask an LLM to generate a bio for you, it often combines factual statements with some made-up ones.
(2) When you ask an LLM to summarize a given document (in the RAG style) it still can generate an incorrect summary (e.g. the work showing that 50% of book summaries contain factual errors https://t.co/jLGqgOl1ve)
(3) When you fine-tune an LLM all LLaMAI-style (e.g. https://t.co/V9np4DWaiZ), it can improve the generation but doesn't completely avoid hallucinated completions.
tldr; higher quality training data can improve the quality of completions, but doesn't guarantee factuality as it can't fuly eliminate the possibility of hallucination.
In general, the n-gram nature of LLMs makes them inherently "creative" helping them mix and match content/patterns they drew from different parts of the corpora. This is their boon--and also bane. 👉https://t.co/rY8KDbWAdV
If factuality/correctness/truth is critical, you have to go LLM-Modulo external verifiers.. https://t.co/mREKgH8mxk (https://t.co/RlbpwkYuns)
📢 BREAKING 📢
Historic agreement on #chatcontrol proposal: EU Parliament wants to remove chat control and safeguard secure encryption. 🔒
💪Let's keep pushing for strong privacy rights!👇
https://t.co/N9Qd43c5WQ
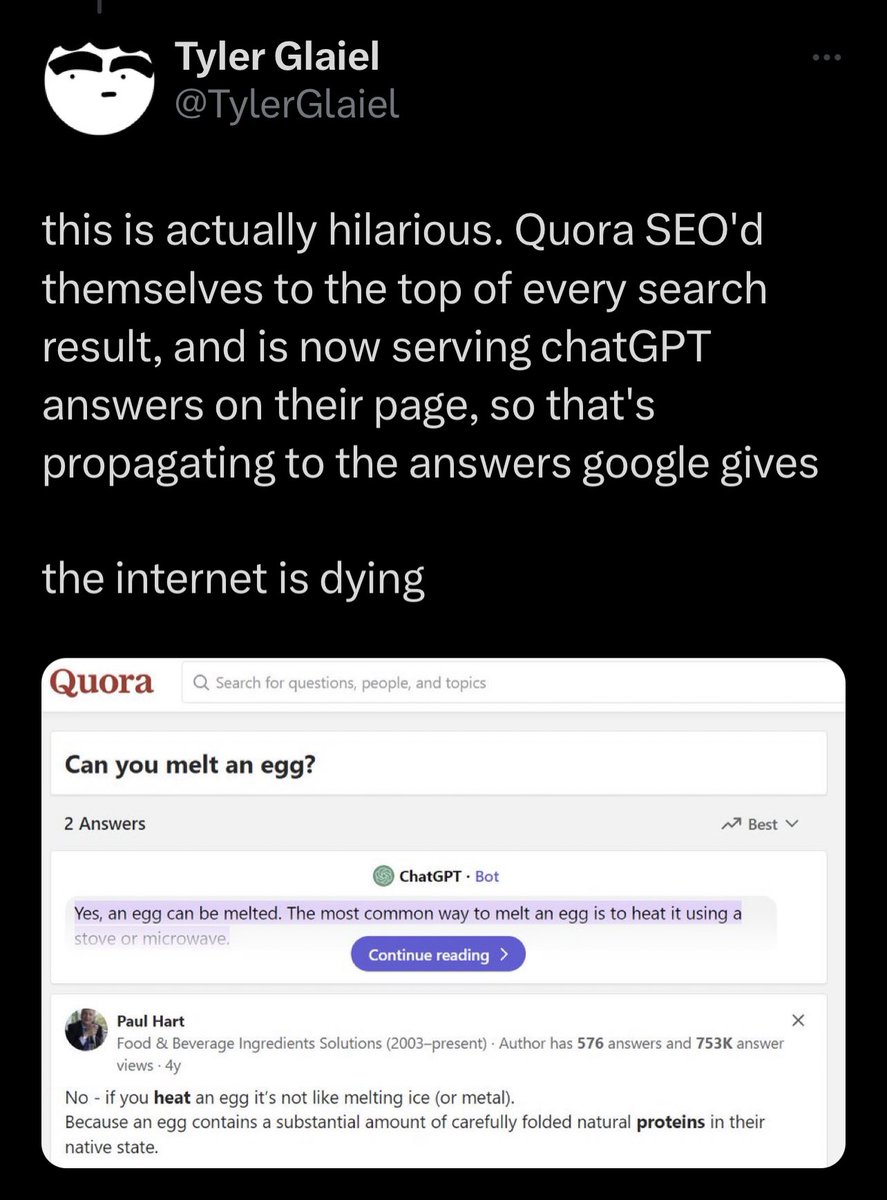
Vicious Self-Degradation
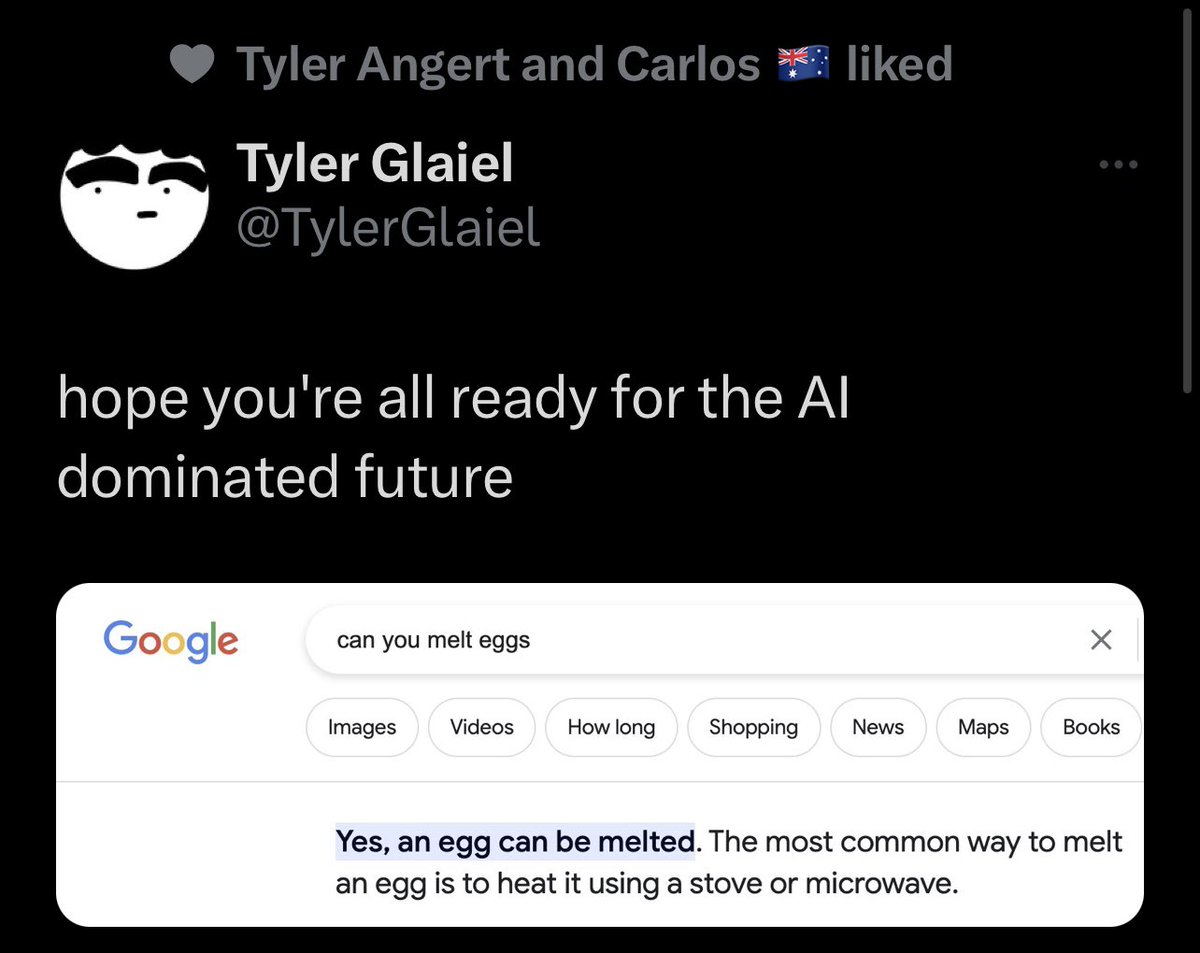
> you Google
> Quora spots query and id’s as frequent
> Quora uses ChatGPT to generate answer
> ChatGPT hallucinates
> Google picks up Quora answer as highest probability correct answer
> ChatGPT hallucination is now canonical Google answer
Mathematics.
"What’s the area of the toppled square?" (All blocks are squares. The diagram is not to scale. The numbers represent areas of squares.)
By Catriona Agg, @Cshearer41, Used with permission.
* People ask LLMs to write code
* LLMs recommend imports that don't actually exist
* Attackers work out what these imports' names are, and create & upload them with malicious payloads
* People using LLM-written code then auto-add malware themselves
https://t.co/Va9w18RpWu
Twee vraagjes voor https://t.co/PUKnVZXj2V @fostplusnl
1) Verstorven elastiekjes bij PMD?
2) Eenzijdige zilverpapiertjes zoals bij chocolaatjes zit restafval of PMD? (sommige zilverpapier mag bij rest anderre moet bij PMD :S)
I keep wondering, @katiesteckles, is the eurosong theme a boon or a hurdle for the MJ target audience?
I'm def. ambivalent myself, but maybe you can recall from previous years. :-)
@xsteenbrugge The EU is not the one making it impossible. The Big Tech monopoly is... that's imho much more relevant in the field atm than this legislation. @jbaert@thomas_wint ?
@xsteenbrugge Honest question: Where's the "small company competion" in ML right now? Even LARGE academic institutions can't compete with big tech atm. There's much more needed for healthy competition imho.
@cyrilzakka@jeremyphoward I think the same goes for many high risk fields. Current gen AI-models are often dangerously brittle. Take a look at my TL for some failures i posted of ChatGPT in december 2022.
@jeremyphoward In a way, I welcome this initiative for medical generative AI. The amount of poorly tested models for clinical AI I’ve seen out there is going to cause a lot of harm.