I design and build AI products, mobile apps, and design systems.
Built TapeKit. Designed Peech and Haiper. Previously worked with teams like Continental, Bentley, and Blanco.
I’ll share notes on product taste, AI UX, interface craft, and the messy parts of making useful apps.
Codex gets slow when one session has to be researcher, builder, reviewer, and janitor.
The operator move is boring: split the work. Explore first. Build against a tight target. Run cleanup as a separate pass.
Most token waste starts as context laziness.
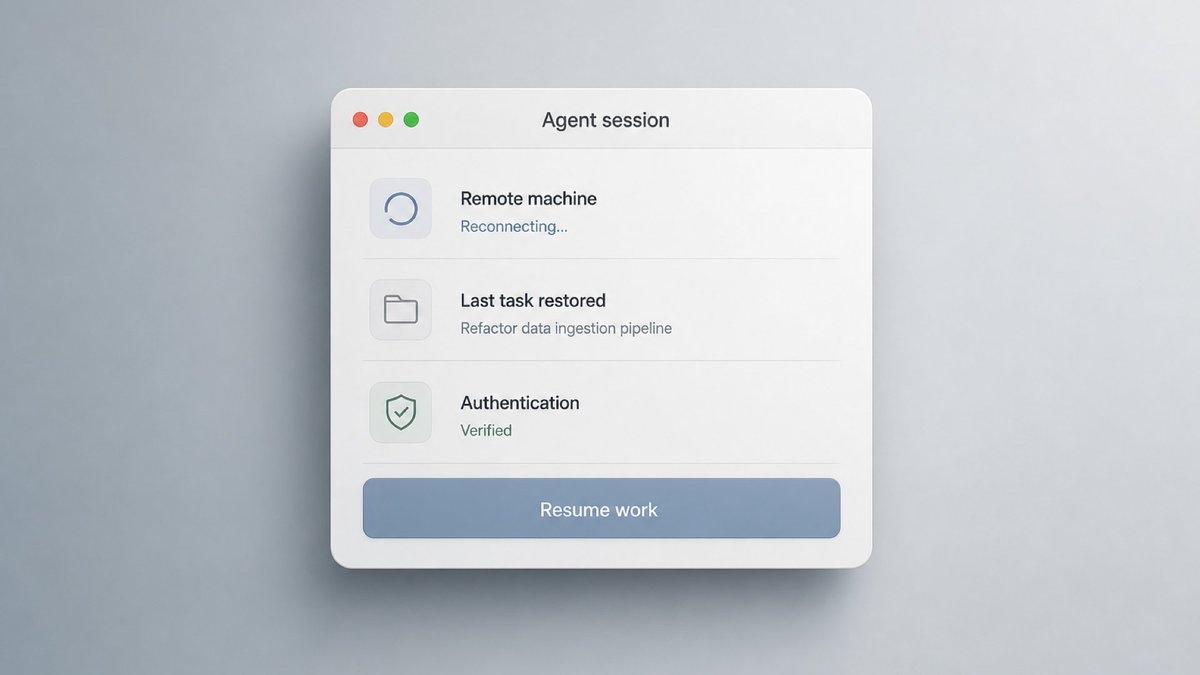
Agent persistence is not saved chat history.
A persistent agent should survive the boring parts: reconnecting the app, restoring the last task, keeping auth state legible, and letting the user resume without rebuilding context.
Otherwise it is just memory cosplay.
5. Fabric.js
https://t.co/d37MpOAfou
Lower-level than the others, but that is the point. Use it when you need control over objects, selection, SVG import/export, and canvas behavior instead of adopting a full whiteboard product.
Chat is a weak surface for visual work.
5 open-source canvases worth saving if you are designing agent workspaces, review flows, or tools that need more than a transcript.
4. Drawnix
https://t.co/Ilvkq5HXHA
This one is interesting for product builders because it mixes mind maps, flowcharts, freehand sketching, and board work. Not every workspace needs Figma energy. Sometimes the useful surface is messier.
AI review screens need more than approve/reject.
The useful state is usually in-between:
- what is safe to apply
- what needs a source
- what is blocked by auth
- how to undo
If the interface cannot show that, the human becomes the review system.
AI products should not hide uncertainty in one vague “something went wrong” state.
When confidence is low, the UI needs clear options:
ask a follow-up,
verify sources,
undo or pause.
Uncertainty is not a failure mode.
It is a product state that needs design.
AI design tools demo the easy part: making a screen.
The hard part is keeping constraints alive:
- variants
- edge states
- copy decisions
- token rules
- review history
- why the old flow worked
For mature products, the canvas is not output.
It is the shared judgment surface.
I still don’t trust coding agents with production state.
Code can be reviewed later.
Database writes, migrations, auth scopes, billing logic: those need a slower handoff.
The question is not “can the agent do it?”
It is “where should the agent stop?”
@compileandpush I’d keep it boring: SQLAlchemy async behind a small repository/service boundary, with no ORM cleverness leaking into handlers.
The part I care about most is the same as agent UX: every write path should leave a readable trail — what changed, why, and how to roll it back.
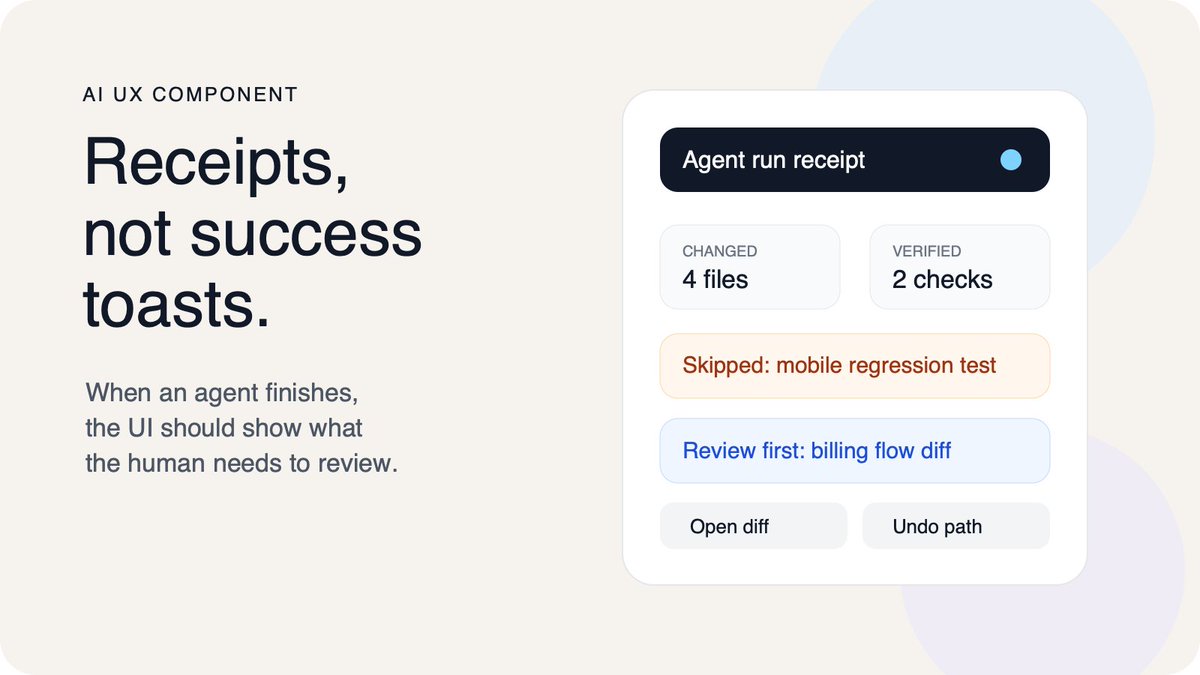
Design systems for AI products need a component normal SaaS systems never had: the receipt.
Not a success toast. A review surface.
It should show:
- action taken
- evidence/source
- confidence
- skipped checks
- undo path
Without it, every agent workflow ends in audit work.
@timharris707 Exactly. The receipt should remove the need to reconstruct intent. My minimum bar is: what changed, why it changed, what was verified, and where the human should look first.
5 agents in Claude Code is not the hard part.
The hard part is reading 5 receipts.
Each run should leave:
- files touched
- tests run
- commands skipped
- open risks
- handoff point
If you only get a giant diff, you did not build a workflow.
You built a cleanup queue.
Most agent UX still treats "done" as the product.
For real work, the receipt is the product:
- files changed
- commands run
- tests skipped
- open risks
- stop reason
- undo path
Without that, autonomy just moves the work from execution to audit.
Claude Managed Agents makes one product gap obvious.
If an agent runs for 20 minutes and comes back with only Done, the product is unfinished.
Show:
- files changed
- commands run
- commands skipped
- auth that blocked progress
- stop reason
Hosted infra is not the result.
Codex on Windows changes the test for computer use.
Do not judge it on one clean task.
Judge it on recovery:
- permission prompt
- wrong folder in file picker
- stale app from the last run
- half-filled form
If it gets those right, it can handle a real desktop.
Claude Code dynamic workflow moves the bottleneck from prompts to repo rules.
Do not ask if it can run 20 agents.
Ask if 20 outputs can land in one clean PR.
Check:
- scratchpad per agent
- files changed
- tests run
- no-touch files
If those are fuzzy, you scaled cleanup.