NEO-ov: Native one-vision model that learns pixel-word correspondence end-to-end—no external encoders, no adapters. Multi-image & video understanding without the modular Frankenstein seams.
arXiv:2605.28820
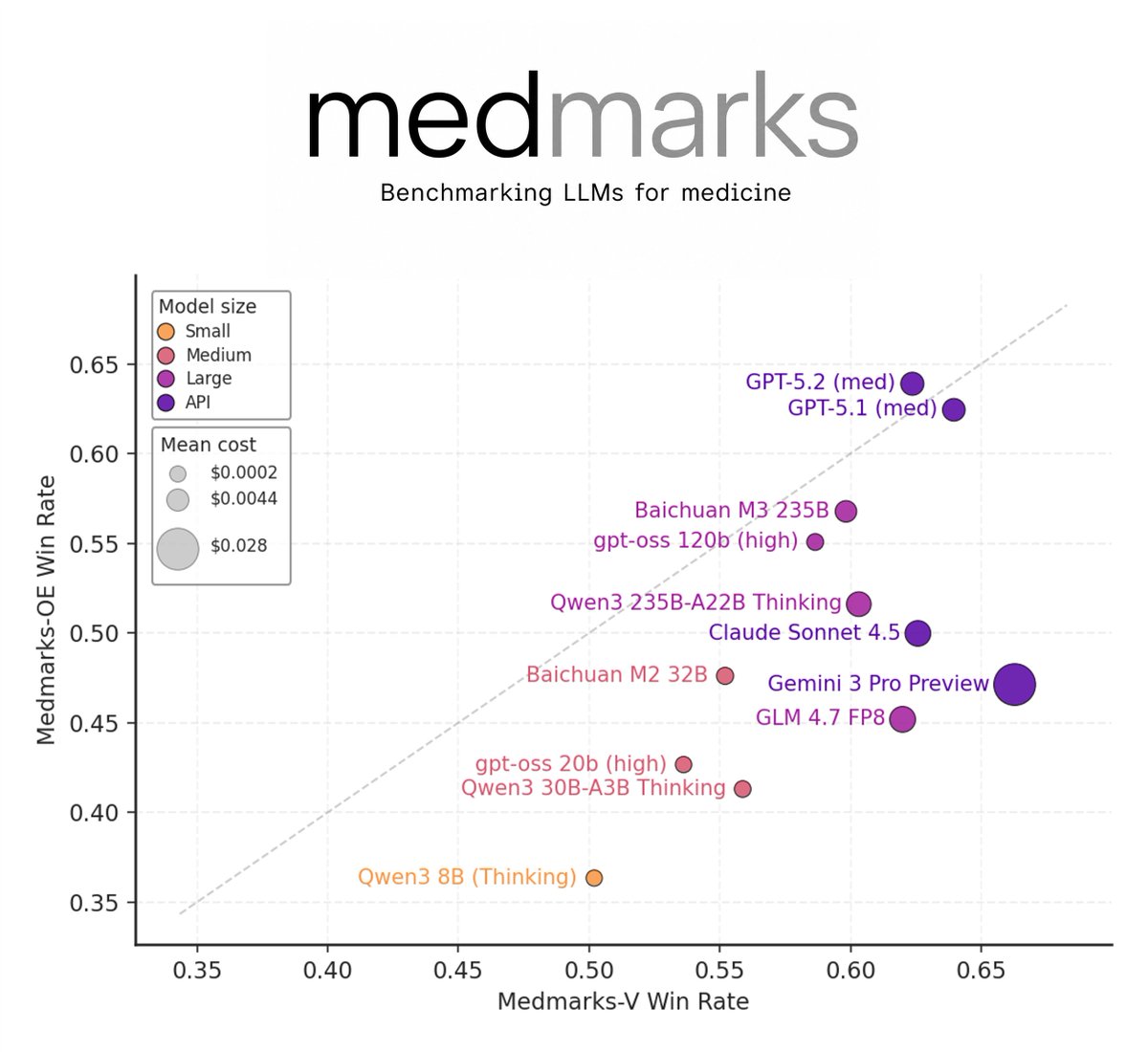
We're excited to release Medmarks v1.0 + a technical report!
This is an update to our Medmarks benchmark suite, the largest open-source automated suite for evaluating the medical capabilities of LLMs.
We added 10 benchmarks (20→30) and 15 models (46→61) to the leaderboard!
A team of cracked @GoogleDeepMind colleagues just released Vision Banana
A brief thread about Vision Banana, what it means for the future of AI, and the future of image understanding 🧵
TIPS and TIPSv2🚨
Last week, @GoogleDeepMind released TIPSv2, their latest suite of image-text encoders with spatial awareness.
You already know the deal here: fancy feature maps, SOTA along many tasks and benchmarks, and open source for all of us to use.
But what makes this line of work special?
📢📢 We released checkpoints and Pytorch/Jax code for TIPS: https://t.co/0JUIRML8gr
Paper updated with distilled models, and more:
https://t.co/zebYMD0VFz
#ICLR2025
Losses are usually part of combat, and it is fine to lose a few jets in pursuit of goals on the battlefield. But what makes it super embarrassing for United States is the loudmouth president who claimed that “we have absolute control over the battlefield and that the Iranians are nowhere, with a complete loss of their air defence radar network, air force, and navy.”
🚨 New paper alert !!
🎥 Video VLMs are strong at high-level semantics and long-range temporal understanding.
🧠 JEPA is almost the opposite: better at dense, high-frequency dynamics, local physical consistency, and fast corrective control, but are less suited for rich semantic reasoning and long-horizon reasoning.
We try to get the best of both:
🧩 A VLM as a cortex-like reasoner for semantics and long-horizon planning
⚡ A JEPA branch as a cerebellum-like controller for fine-grained dynamics, physical consistency, and rapid corrections
Proudly, we present ThinkJEPA: a VLM-guided latent world model that FiLM-fuse the pyramid repr of VLMs encoding long-horizon semantic reasoning into the JEPA repr for fine-grained, physically consistent dynamics prediction.
🔗 Project: https://t.co/quro6Pf8un
📄 Paper: https://t.co/yO5rv3ZJT7
@Williamiumli I went through this paper yesterday it was great. Altho it'd be amazing to see whether replacing the vlm with a jepa pre trained on sparse frames for long distance reasoning would work too or not
🚀 LeWorldModel datasets & checkpoints are now available on Hugging Face!
https://t.co/aiBkDTsNyX
You can plug them directly into stable-worldmodel (https://t.co/2eQB7Q0l9i), the engine behind LeWorldModel, to instantly load, run, and start building on top of our models.
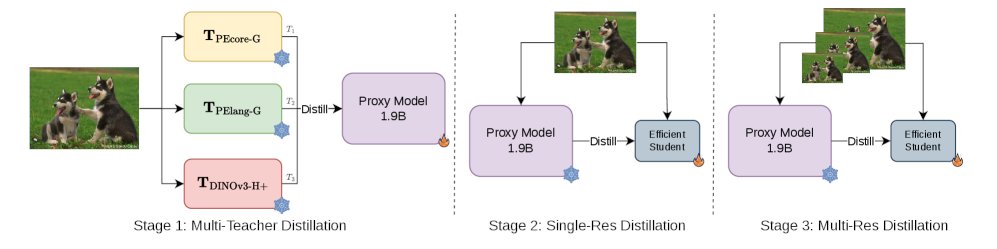
Meta just released the Efficient Universal Perception Encoder on Hugging Face
A vision backbone for edge devices that unifies image understanding, vision-language modeling, and dense prediction via multi-teacher distillation.
@massiviola01 I have been thinking a lot between clip and dino features obviously clip features are much more linguistically aligned and thus they don't capture patch features due to global supervision of image caption. https://t.co/MCXpHMlYQd this was something i read recently a little old.
JEPA are finally easy to train end-to-end without any tricks!
Excited to introduce LeWorldModel: a stable, end-to-end JEPA that learns world models directly from pixels, no heuristics.
15M params, 1 GPU, and full planning <1 second.
📑: https://t.co/cpTzgvbTS0
I've been working on a new LLM inference algorithm.
It's called Speculative Speculative Decoding (SSD) and it's up to 2x faster than the strongest inference engines in the world.
Collab w/ @tri_dao@avnermay. Details in thread.
@initlayers If you're interested in local attention do read these papers one is "Hiera: Hierarchical transformers without the bells & whistle" then another paper I belive it was window attention is bugged