Meme Coin and fee assist aside, this project is next level and AI game changing. I don’t know how many times I’ve been frustrated with AI amnesia. I’ve lost a lot on this coins 1200 plus but I’m staying in to show my support for the Project at the least.
From Resident Evil zombie-slayer and The Fifth Element’s Leeloo to AI pioneer, huge respect to @MillaJovovich for co-creating $MemPalace. Milla spent months meticulously organizing files for her own AI projects (she was even building a game) only to realize every existing memory system still sucked at retrieval - flat vector dumps, lost nuance, forgotten context
Frustrated, she researched ancient Greek “memory palace” techniques (the method of loci used by orators to memorize epic speeches). She sketched the entire hierarchical architecture herself — wings for people/projects, halls for memory types, rooms, tunnels, drawers - then teamed with engineer @bensig to turn her vision into reality. The result? Over 13,000 Github stars under 24 hours. The first-ever 100% on LongMemEval, beats every paid competitor, 100% local/open-source, your whole personal history loads in ~120 tokens with perfect chronology and zero cloud dependency
https://t.co/iWuTIBPcng
Milla went from Hollywood icon to dropping one of the most groundbreaking AI tools of the year. This is legendary. Thank you for building the future we actually need. ❤️ We’ve raised nearly $10,000 for you to claim anytime, with the fees going to you and Ben in a 50/50 split. You can claim anytime simply by signing in with the Pumpfun app and following these instructions!
https://t.co/HT5bTVMITI
(Shoutout @bensig - y’all just changed the game. Feel free to claim your fees!)
https://t.co/einwF4thaI
FRHfkyLic2y9shVp8TyxijEtx5KGzci1JeDAiZWbpump
Hi Ben
Congrats on the insane launch! We made a community for the $MemPalace fan token and would love to have you in there. Since this is an open-source project, the community would love to fund it’s development as we see and believe in the vision
https://t.co/z60DQ7zhIR
All fees have been permanently locked to your/Milla’s Github with a 50/50 split. So far we’ve raised nearly $7,000 total for both of you to claim. Check out this thread from Pumpfun for claim instructions:
It’s been close to 24 hours and $mempalace has over 10k GitHub stars and over 7k raised for both Mila and Ben. They asked for funding and they got it.
That being said, the token is only at 60k, crazy right? What do you think the slightest engagement does? Brrr
There’s been a lot of noise around MemPalace by @bensig & @MillaJovovich today, so here’s the actual situation.
I’ve seen the thread breaking down the benchmarks and calling them misleading. Some of the points are valid, but also incomplete if you look at the full picture.
Let’s go through it properly.
1. About the 96.6% / 100% LongMemEval claim
The criticism says:
MemPalace reports Recall@5 (retrieval) while others report end-to-end QA accuracy.
That’s correct. These are fundamentally different metrics, and putting them side by side without context can be misleading.
But also:
MemPalace is clearly focused on retrieval quality, not full QA pipelines.
It’s solving:
“can the system reliably find the right memory?”
Not:
“can the system retrieve + reason + answer perfectly?”
And in any memory system, retrieval is the first bottleneck.
If retrieval fails, everything else fails.
2. “It’s just ChromaDB defaults”
Another point raised is that the 96.6% score comes from:
ChromaDB + a standard embedding model (MiniLM)
No MemPalace-specific logic.
This is true for that specific benchmark path. But that’s also a baseline measurement, not the full system.
MemPalace itself adds:
• structured memory (wings, rooms, halls)
• knowledge graph + timelines
• contradiction detection
• compression layer
So reducing it to “just ChromaDB” is an oversimplification.
3. The Memory Palace architecture
The thread points out that the “palace” structure isn’t used in the headline benchmark.
Also true. But that doesn’t invalidate the architecture.
It just means:
the benchmark isolates raw retrieval performance, not the structured system.
The palace concept is meant to improve real-world usage:
• better organization
• contextual linking
• long-term consistency
Which are much harder to capture in a single benchmark score.
4. AAAK compression
This is where the criticism is strongest.
The claim:
“30x lossless compression”
The test shows:
• ~4–5x compression
• noticeable information loss
If reproducible across more cases, then yeah, the “lossless” claim is likely overstated. This part definitely needs more validation.
So, is the criticism fair?
Partially, yes.
• The benchmark comparison is not apples-to-apples
• The headline number can be interpreted in an overly optimistic way
• The compression claims may be exaggerated
But also:
• The benchmarks are open-source and reproducible
• The system is still very new (basically day 1)
• The criticism focuses heavily on one path, not the full architecture
So it’s not a “debunk”, it’s more like:
a valid stress test of early claims
This isn’t a scam. But it’s also not magic.
The numbers need proper context. The architecture is still genuinely interesting.
The real question is simple:
Does this actually improve long-term memory in real usage? Bcs that's what matters.
And @bensig Ben has always said "Try it, critique it, fork it," and the repo is MIT-licensed with reproducible scripts, so the community can ( and is ) stress-testing it immediately.
Milla Jovovich and Ben Sigman just shipped MemPalace - an open source AI memory system that got the first perfect score on LongMemEval ever. Here's what it actually does and why the benchmarks matter.
The problem: AI has no long-term memory. Every conversation starts from zero. ChatGPT's built-in memory scores 52.9% on recall benchmarks. Most "memory" solutions are glorified note-taking.
MemPalace applies the ancient Greek "method of loci" to AI. Your conversations are organized into a literal memory palace:
Wings = people and projects
Rooms = specific topics
Halls = types of memory (facts, events, discoveries, preferences)
When AI wakes up, it loads your identity and critical context in ~170 tokens. It knows who you are before you type a word. Deeper memories are pulled on demand via semantic search.
They invented a compression dialect called AAAK - 30x compression with zero information loss. Not summarization. A shorthand that any LLM reads natively without a decoder. Six months of daily conversations fit in ~120 tokens of context.
Everything runs locally. ChromaDB for vectors, SQLite for the knowledge graph. No cloud. No API keys. No subscription. One dependency.
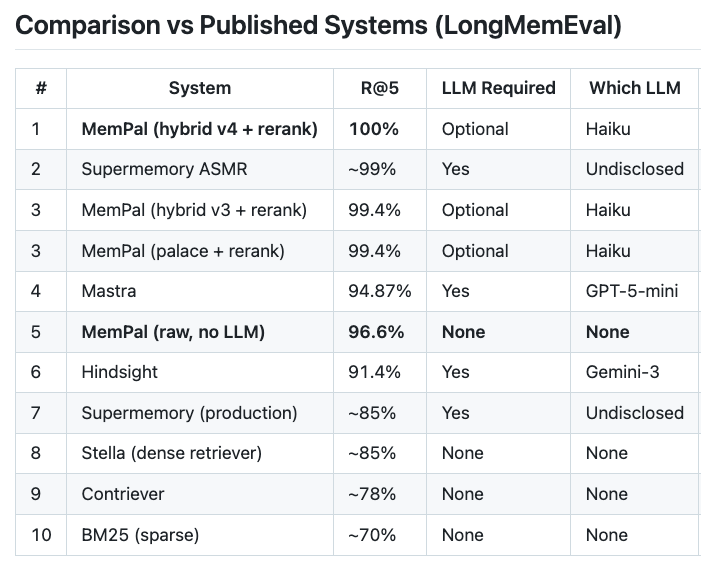
The scores (from their published benchmarks):
- LongMemEval: 100% (500/500, first perfect score)
- LoCoMo: 100% (including multi-hop reasoning)
- ConvoMem: 92.9%
Closest competitor: Supermemory ASMR at ~99% (research only, not in production). GPT-4o with full context: 60.2%. Baseline keyword search: ~70%.
Their raw mode without any LLM still scores 96.6% - meaning the architecture itself does most of the work.
Memory was the missing fifth element.
@bensig I tried MemPalace and It works amazingly well, seriously bravo. I thought my models had “persistence” before with redis, docker, etc. Nah, theres a clear difference. My telegram bot finally has continuity remembering my other projects and concepts.