When doing market making or cross exchange arb in crypto we discussed some of the issues of computing fair price from multiple geo-distributed data feeds.
Your quotes will arrive asynchronously from Binance, Bybit, Coinbase and so on, and each will be an indirect measure of fair price.
For example, how do you weigh the Binance and Bybit quotes that came in 35ms and 75ms ago against that Coinbase quote that came in 15ms ago? What about when the ordering is reversed?
Each exchange has a different level of liquidity, error, and basis, so even if the quotes were all equally fresh, there'd still be some decisions to be made. But latency adds an additional layer of complexity.
One mental model for this is ruler theory. Imagine trying to combine the measurements of a bunch of different rulers, each with their own bias (μ) and error (σ), into one optimal measurement.
Bias means a particular ruler is on average off from the truth by a consistent amount. Error means there is a random fluctuation by how much it is off from this average amount, sometimes a lot, sometimes a little, but usually within one stdev around the truth.
In physics, the way to weight each measurement is via precision weighting where each ruler is weighted by its inverse variance:
~ 1/σ²
A quote from a particular exchange is like a ruler measurement of fair price in that it too has its own bias and error.
The dominant part of bias is easy to measure, it is just basis, and a good start is to compute a rolling mean.
Error is a bit more complex. It will depend on liquidity, spread, volatility ... and time elapsed.
BTC-USDT on Binance is expected to be a less errorful measurement of BTC than the same instrument on say, Kucoin. But BTC-USDT on Binance 1 second ago is expected to be more errorful than BTC-USDT on Kucoin 10ms ago.
So there is an innate component to error and a time component. Total error squared will look something like this:
error² ≈ ε²_exchange + σ_price²·τ
where τ is the amount of time that has elapsed from when the quote was emitted to when you registered it, and ε²_exchange is the error unique to that instrument on that exchange (and at that particular point in time). For the time dependence, the assumption here is Gaussian diffusion, which is a defensible first order approximation when you are not near a significant liquidity event.
So errors have a component that grows at a speed proportional to variance, creating a kind of uncertainty cone as they propagate forward in time.
This tells you roughly how to weigh different quotes from different exchanges arriving at different times.
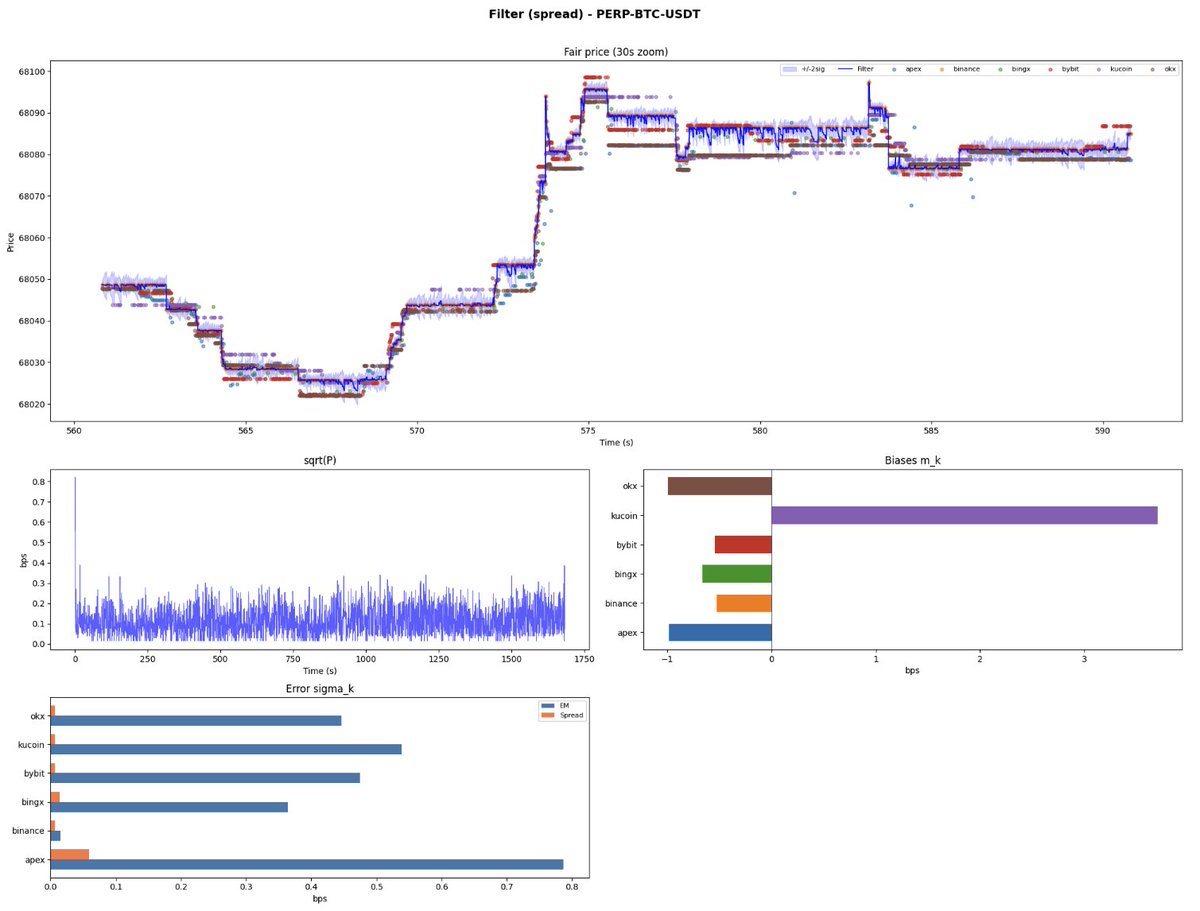
Below are plots from two models built on this intuition. Both are measurably better than just using the Binance mid-quote, and in production, more robust against feed glitches on any single exchange.
We'll discuss in more detail some concrete models that incorporate this intuition, and some that work surprisingly well while ignoring parts of it, in a subsequent post.
@Tom_Degen68@tradehotstuff@dango Nice writeup. Thoughts on the teams? I know a bit about the hotstuff guys, don't know much about the people behind django.
@annanay Oh I thought they were just giving it away to win enterprise users. In exchange for equity? no lol. I would value this as I would value free airline miles, near zero.
Given that most signing on hardware wallets is effectively blind (who has the discipline to examine a hex blob each and every time) hw is not enough.
I think manufactures are dropping the ball here not providing better tools, for example tx simulation pre-signing.
Shooting from the hip here, but combined with zk tls verification of the sim result on the device this could be quite effective.
When trying to fix negative markouts in your market making system, top of the list should be digging into fills that happened during inflight cancels.
These are trades your system knew were going to be toxic, but you got filled anyway.
This may happen because you're still too slow on the tails and quoting too tight for your latency, or it could be an inconsistency in your business logic.
Tracking these events involves accepting a small amount of overhead in the hot path but is generally worth it, especially in the testing phase with smaller amounts of capital.
When such events cross a certain threshold, I like to attach a cancel and fill context for detailed analysis of the system state before and after. This can include details about the BBO, alpha states, latency deltas, skew, etc.
Then, once such events have been reduced to an acceptable level, compile them out to shave the extra nanos off the hot path.
If you're a market maker or taker in crypto, venue selection is one of the most important decisions you'll make. You need a visceral understanding of why it matters, especially starting out, as I see too many people going straight to tier A. Venue selection can make or break your profitability as a boutique MM (and you are boutique unless you're doing a significant % of tier A volume).
Here's the mental model I keep in mind.
A group of people stand around a chute. Every so often a turkey drops out. Whoever catches it keeps it, so everyone muscles each other for position, hunger games style. Some turkeys have grenades strapped to them. And in the surrounding hills are snipers who are constantly picking MMs off.
Some arenas have nice fat turkeys, few grenades, and unskilled snipers. Your fellow MMs are farmers with pitchforks.
Other arenas, most turkeys have grenades, the snipers are Navy SEALs, and your fellow MMs are Delta Force operators, skilled at grabbing the good turkeys before you and letting you blow up on the grenades. Meanwhile, you can't remember the last time you did a pushup.
So given this spread, which arena do you pick? Does it make sense to spend some time watching as a spectator before jumping in?
I'll cover specific techniques for assessing venue quality and profitability in a follow-up post.