Free Maxar/Vantor Satellite Imagery for Disaster Response - QGIS and MapLibre Plugins Demo
Want to download free high-resolution satellite imagery in QGIS? In this tutorial, I’ll show you how to access and visualize imagery from the Vantor (formerly Maxar) Open Data Program using two powerful plugins, no programming required.
The Vantor Open Data Program provides free satellite imagery to support global disaster response and recovery efforts. These plugins make it easy to search, filter, preview, and download imagery directly inside QGIS or in web applications built with MapLibre GL.
MapLibre GL Plugin
GitHub: https://t.co/kpUPpY9IBt
Live Demo: https://t.co/FT4PwKKc8Q
QGIS Plugin:
GitHub: https://t.co/ECRrscDsS5
Plugin Page: https://t.co/QBHgBFoxyj
Vantor Open Data Program: https://t.co/KJhhiwkCcf
#QGIS #Maxar #SatelliteImagery #DisasterResponse #OpenSource
[1/n] Do distinct large models admit a simple map that aligns their embedding spaces? We show that across multimodal contrastive models—trained on different data and architectures—an orthogonal map aligns image embeddings. Strikingly, the same map also aligns text embeddings.
Well done to the SAM3D team. I haven't benchmarked it properly yet but this is definitely going to be the default backbone of choice for all 3d tasks by the back half of next year in the literature.
What a time to be alive 🌞
An AI-guided FPV drone from Ukraine’s 40th Brigade tracked and hit a Russian boat. A follow-up strike with an Orion loitering munition finished the job.
LLaVA-NeXT: Advancements in Multimodal Understanding and Video Comprehension
Researchers from Nanyang Technological University, University of Wisconsin-Madison, and Bytedance have developed LLaVA-NeXT, a pioneering open-source LMM trained solely on text-image data. The innovative AnyRes technique enhances reasoning, Optical Character Recognition (OCR), and world knowledge, showcasing exceptional performance across various image-based multimodal tasks. Surpassing Gemini-Pro on benchmarks like MMMU and MathVista, LLaVA-NeXT signifies a significant leap in multimodal understanding capabilities.
Venturing into video comprehension, LLaVA-NeXT unexpectedly exhibits robust performance, featuring key enhancements. Leveraging AnyRes, it achieves zero-shot video representation, displaying unprecedented modality transfer ability for LMMs. The model’s length generalization capability effectively handles longer videos, surpassing token length constraints through linear scaling techniques. Further, supervised fine-tuning (SFT) and direct preference optimization (DPO) enhance the video understanding prowess. At the same time, efficient deployment via SGLang enables 5x faster inference, facilitating scalable applications like million-level video re-captioning. LLaVA-NeXT’s feats underscore its state-of-the-art performance and versatility across multimodal tasks, rivaling proprietary models like Gemini-Pro on key benchmarks.
Quick read: https://t.co/0iglUay0K0
GitHub: https://t.co/0rGaYMMeWm
#artificiallyinteligence #ai #artificiallntelligence @liuziwei7
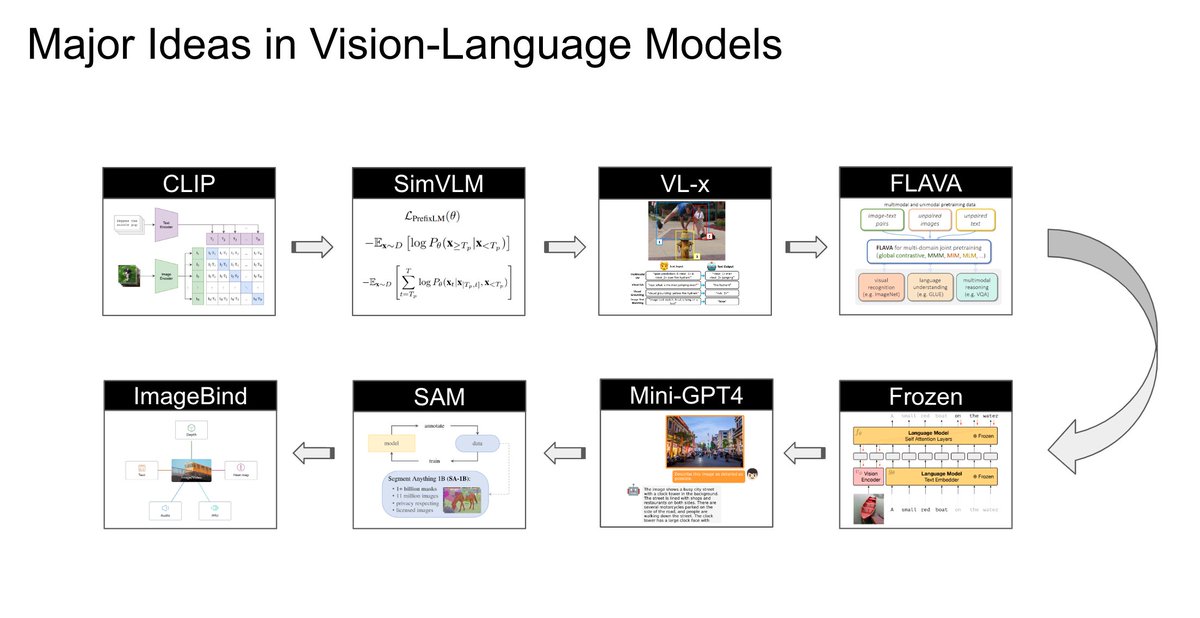
Last year, I delivered a lecture on large vision-language models at @mbzuai, where I explored some interesting ideas through eight models. The content is a bit old but still relevant.
Here are the slides: https://t.co/Arjxl9MTd6