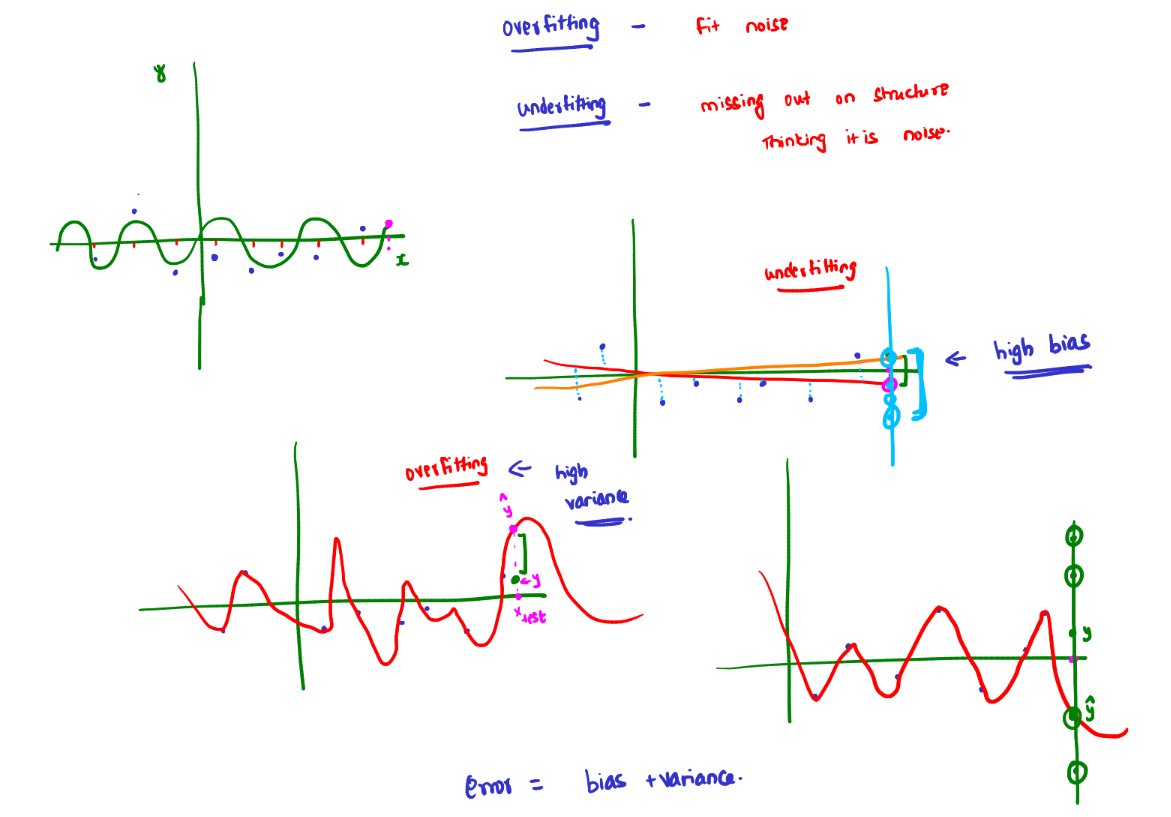
Day 57 of #100DaysOfML
Today was about generative classifiers—specifically Naive Bayes.
Key takeaways:
Modeling P(x∣y)P(x \mid y)P(x∣y) instead of P(y∣x)P(y \mid x)P(y∣x) changes how you think about learning
Class-conditional independence → simple likelihoods, strong baselines
MLE for Bernoulli & Gaussian NB is surprisingly intuitive
With equal covariance, Gaussian NB yields a linear decision boundary
Zero-frequency issues → Laplace smoothing is not optional
Simple assumptions. Strong theory. Still competitive in practice.
Day 62 of #100DaysOfML
Today cracking open the math behind Soft-Margin SVMs!
The real magic lies in the Dual Problem and Complementary Slackness.
🟢 The Safe Zone:
Correctly classified and safely past the margin.
🟡 The Support Vectors :
Sitting perfectly on the margin edge. These define the boundary!
🔴 The Margin Violators:
Points that are either inside the margin or completely misclassified.
It's how complex optimization math translates into such clear geometric intuition!
Day 62 of #100DaysOfML
Today cracking open the math behind Soft-Margin SVMs!
The real magic lies in the Dual Problem and Complementary Slackness.
🟢 The Safe Zone:
Correctly classified and safely past the margin.
🟡 The Support Vectors :
Sitting perfectly on the margin edge. These define the boundary!
🔴 The Margin Violators:
Points that are either inside the margin or completely misclassified.
It's how complex optimization math translates into such clear geometric intuition!
Day 61 of #100DaysOfML – Logistic Regression
Today was about the math behind Logistic Regression:
• Sigmoid maps scores → probabilities
• Likelihood → log-likelihood for numerical stability
• Objective = maximize log-likelihood (or minimize cross-entropy)
• Gradient: ∑ xᵢ (yᵢ − σ(wᵀxᵢ))
• Update rule: w ← w + η ∇logL
• Regularization adds λ/2 ‖w‖² to prevent overfitting
• Kernelization possible via w* = Σ αᵢ xᵢ
From probability model → optimization → gradients → regularization.
The next several years will see the greatest destruction of human ego in history!
In the age of AI, there will be three big losers:
1) Those who maintain high ego & arrogance about their intellectual abilities;
2) Those whose careers depends on gatekeeping;
3) AI deniers.
Hard take: If India builds its thorium reactor within the next 2-5 years, it can become one of the world's superpowers.
Otherwise, the train has already left. This is the only visible move - move 37 - left for India.
Day 61 of #100DaysOfML – Logistic Regression
Today was about the math behind Logistic Regression:
• Sigmoid maps scores → probabilities
• Likelihood → log-likelihood for numerical stability
• Objective = maximize log-likelihood (or minimize cross-entropy)
• Gradient: ∑ xᵢ (yᵢ − σ(wᵀxᵢ))
• Update rule: w ← w + η ∇logL
• Regularization adds λ/2 ‖w‖² to prevent overfitting
• Kernelization possible via w* = Σ αᵢ xᵢ
From probability model → optimization → gradients → regularization.
Day 60/100 #100DaysOfML
Diving into Support Vector Machines intuition!
From perceptrons to max margins for better classifiers. Here's a structured breakdown:
Perceptron Foundation: Mistake bound is # mistakes ≤ R²/γ², where γ is the margin. Larger margins = fewer errors & better generalization.
Goal: Formulate optimization to directly maximize the margin, avoiding small-margin pitfalls.
Key Derivations:Normalize weights: Set ||w||=1, then maximize γ s.t. y_i (w·x_i) ≥ γ for all i (avoids scaling issues).
Equivalent form: Fix functional margin to 1, minimize (1/2)||w||² s.t. y_i (w·x_i) ≥ 1.
Geometric margin: Simplifies to 2/||w||.
Day 60/100 #100DaysOfML
Diving into Support Vector Machines intuition!
From perceptrons to max margins for better classifiers. Here's a structured breakdown:
Perceptron Foundation: Mistake bound is # mistakes ≤ R²/γ², where γ is the margin. Larger margins = fewer errors & better generalization.
Goal: Formulate optimization to directly maximize the margin, avoiding small-margin pitfalls.
Key Derivations:Normalize weights: Set ||w||=1, then maximize γ s.t. y_i (w·x_i) ≥ γ for all i (avoids scaling issues).
Equivalent form: Fix functional margin to 1, minimize (1/2)||w||² s.t. y_i (w·x_i) ≥ 1.
Geometric margin: Simplifies to 2/||w||.