🚀 Just Released: A Survey on Token Compression for MLLMs
How do we efficiently "reduce" the number of tokens in MLLMs?
Our work introduces: 1️⃣ A taxonomy based on Where to Compress (Encoder/Projector/LLM). 2️⃣ A deployment roadmap on How to Select the right algorithm.
[1/n]
Super excited to introduce PaperBanana 🍌! (PKU x Google Cloud AI)
As AI researchers, we often spend way too much time crafting diagrams and plots instead of focusing on the ideas 🤯. To rescue us from this burden, we built an Agentic Framework to auto-generate NeurIPS-quality paper illustrations!
📄 Paper: https://t.co/2NbQeEhzMv
🌐 Page: https://t.co/05dKkjVs7f
Key Features:
🌟 Human-like Workflow: Retrieve 🔍 -> Plan 📝 -> Style 🎨 -> Render 🖼️ -> Critique 🔄. This ensures both academic fidelity and aesthetics.
🌟 Versatile: Supports both illustrative diagrams and statistical plots.
🌟 Polishing: Also effective for polishing existing human-drawn diagrams.
Here are some example diagrams and plots generated by our PaperBanana:
🚀 Just Released: A Survey on Token Compression for MLLMs
How do we efficiently "reduce" the number of tokens in MLLMs?
Our work introduces: 1️⃣ A taxonomy based on Where to Compress (Encoder/Projector/LLM). 2️⃣ A deployment roadmap on How to Select the right algorithm.
Video understanding isn't just recognizing —it demands reasoning across thousands of frames.
Meet Long-RL🚀 Highlights:
🧠 Dataset: LongVideo-Reason — 52K QAs with reasoning.
⚡ System: MR-SP - 2.1× faster RL for long videos.
📈 Scalability: Hour-long videos (3,600 frames) RL on a single node (8×A100s).
🖼️📝🎵 RL training for video, text, audio — works with VILA, Qwen series, and image/video generation models 🎨🎬
📄 Paper: https://t.co/vbU5n0w0go
🎥 Demo: https://t.co/3wCv5TJsTa
💻 Code: https://t.co/K9U4fl3HHc
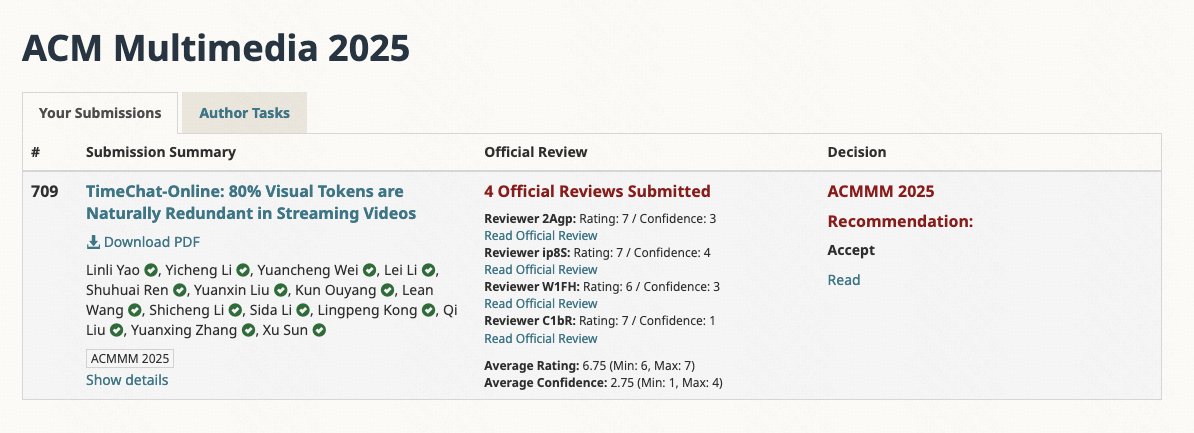
🎉 Happy to share that our TimeChat-Online work has been accepted to ACM Multimedia 2025!
🔗 Check out the project page: https://t.co/ts7IeGz6rc
⭐️ Star our repo if you like it: https://t.co/ue0jQDh42p
🤖 #VideoLLM 🎬 #StreamingAI 📊 #ACMMM2025
Excited to share our new survey on the reasoning paradigm shift from "Think with Text" to "Think with Image"! 🧠🖼️
Our work offers a roadmap for more powerful & aligned AI. 🚀
📜 Paper: https://t.co/ZfaT9CCYuW
⭐ GitHub (400+🌟): https://t.co/YLRaGvB70q
🎥 Check out our new demo video that shows how TimeChat-Online makes real-time video understanding efficient, fun, and intuitive!
🌐 Demo: https://t.co/6lajeVFbG5
🔗 Project: https://t.co/ts7IeGz6rc
👇 Try it out and let us know what you think!
#StreaimingVideo#MultimodalAI
⏰ We introduce Reinforcement Pre-Training (RPT🍒)
— reframing next-token prediction as a reasoning task using RLVR
✅ General-purpose reasoning
📑 Scalable RL on web corpus
📈 Stronger pre-training + RLVR results
🚀 Allow allocate more compute on specific tokens
MiMo-VL technical report, models, and evaluation suite are out!
🤗 Models: https://t.co/Qb2zYTVfzS (or RL)
Report: https://t.co/AqTpy0r2bI
Evaluation Suite: https://t.co/s0rU38DoyU
Looking back, it's incredible that we delivered such compact yet powerful vision-language models in under six months.
Here are my key takeaways from our journey:
Reasoning is now essential for VLMs. Adding long chain-of-thought data to our training produced clear performance gains across all benchmarks. What's fascinating is watching our model actually examine different parts of images, checking various details before working through its reasoning to reach an answer.
Mixed reward learning was our biggest challenge and most inspiring discovery. We saw comprehensive improvements on almost every task with objective rewards like document perception, visual grounding, and multimodal math. MiMo-VL-RL is now the best open-source VLM on the InfoVQA test set. But subjective rewards like human preference data proved much trickier—models learn to game these signals surprisingly quickly. Finding the right balance is truly an art.
We're committed to reproducible VLM research. Throughout development, we experienced firsthand how difficult it is to reproduce results from other papers. Different prompts, temperature settings, and evaluation processes make fair comparisons nearly impossible. That's why we're releasing our complete evaluation suite covering 50+ tasks, built on lmms-eval, with fully reproducible results. We might be the first to do this comprehensively, and we hope it helps advance the field by making research more transparent and comparable.
🚀 New Paper: Pixel Reasoner 🧠🖼️
How can Vision-Language Models (VLMs) perform chain-of-thought reasoning within the image itself?
We introduce Pixel Reasoner, the first open-source framework that enables VLMs to “think in pixel space” through curiosity-driven reinforcement learning.
Current VLMs reason only in text — even when grounded in rich images or videos, their logical steps are verbalized in natural language. This restricts their ability to interrogate visual evidence and demonstrate how conclusions are drawn.
🔍 So we ask:
What if we could make VLMs "show their work" by reasoning directly in the pixel space?
Inspired by GPT-o3’s "think-in-image" ability, we propose a framework where VLMs use interactive visual operations — zoom, select-frame, highlight — to reason through complex visual inputs.
To do this, we design a two-stage training process: Instruction tuning with synthesized visual reasoning traces. Reinforcement learning with curiosity-driven reward to balance exploration between pixel and text reasoning
✨ With this, Pixel Reasoner achieves near-SoTA performance on many information-rich multimodal benchmarks:
📊 84% on InfographicsVQA
🧠 84% on V* benchmark
🧩 74% on TallyQA-Complex
It also achieves strong accuracy of 68% on MVBench (a video benchmark).
Website: https://t.co/3YUxaIJmIv
Paper: https://t.co/CHYukmu5fB
Code: https://t.co/0mQOfXbKpM
Demo: https://t.co/AWDNoffEz8 (coming soon)
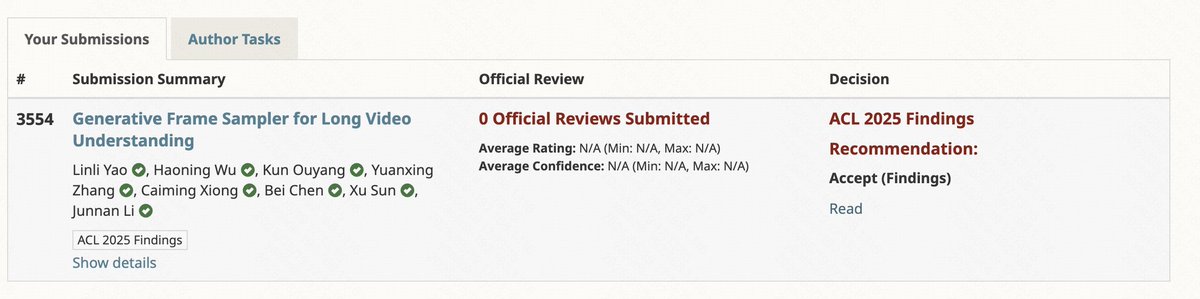
🎉 Delighted to share that our paper GenS has been accepted to ACL 2025 Findings
🤗 It’s been a real pleasure working with my wonderful collaborators! #ACL2025#Multimodal#VideoLLM
Code: https://t.co/lPmrF9Gdl6
Dataset: https://t.co/3TddlG3ccs
📢 Introducing GenS: Generative Frame Sampler for Long Video Understanding!
🎯 It can identify query-relevant frames in long videos (minutes to hours) for accurate VideoQA
👉Project page: https://t.co/rXMvB06fAz
(4/n)
🏆 Performance Highlights:
• StreamingBench: 56.6 accuracy with 82.6% token reduction (new SOTA)
• OVO-Bench: 45.6 accuracy with 84.8% tokens dropped (new SOTA)
• Long video benchmarks (MLVU, VideoMME, LongVideoBench.): up to 85% drop with no performance loss
(3/n)
🔥 DTD can be directly plugged into the Qwen2.5-VL series without training.
✅ On VideoMME (30–60 mins), Qwen2.5-VL-7B w/ DTD boosts accuracy by 5.7 points while dropping 84.6% of tokens
📈 Longer videos tolerate even higher drop rates: up to 97.5% while maintaining acc!
📢 Introducing GenS: Generative Frame Sampler for Long Video Understanding!
🎯 It can identify query-relevant frames in long videos (minutes to hours) for accurate VideoQA
👉Project page: https://t.co/rXMvB06fAz





















![dwzhu128's tweet photo. [1/n]
Super excited to introduce PaperBanana 🍌! (PKU x Google Cloud AI)
As AI researchers, we often spend way too much time crafting diagrams and plots instead of focusing on the ideas 🤯. To rescue us from this burden, we built an Agentic Framework to auto-generate NeurIPS-quality paper illustrations!
📄 Paper: https://t.co/2NbQeEhzMv
🌐 Page: https://t.co/05dKkjVs7f
Key Features:
🌟 Human-like Workflow: Retrieve 🔍 -> Plan 📝 -> Style 🎨 -> Render 🖼️ -> Critique 🔄. This ensures both academic fidelity and aesthetics.
🌟 Versatile: Supports both illustrative diagrams and statistical plots.
🌟 Polishing: Also effective for polishing existing human-drawn diagrams.
Here are some example diagrams and plots generated by our PaperBanana:](https://pbs.twimg.com/media/HALQ9F8aQAAAIqk.jpg)