Launch Week — Day 1: ClawMark
Most agent benchmarks give the model one shot, one prompt, one frozen environment.
Real coworker tasks span multiple days — and the world keeps changing while the agent works.
Introducing 🦞ClawMark: a multi-day, dynamic-environment benchmark for coworker agents. Built by Evolvent together with 40+ researchers from NUS, HKU, MIT, UW, and UC Berkeley. Open-sourced at: https://t.co/QN7XgIoaN1
100 tasks. 13 professional domains. Fully rule-based scoring.
Results from 6 frontier models below. 🧵👇
None of this guarantees recursive self-improvement is on the horizon. It’s not yet clear that Claude is capable of research judgment—of choosing the right problems to work on.
But if these trends continue, AI systems designing and building their own successors is plausible. This could revolutionize society—medicine, technology, the economy—for the better. But it may also compound alignment issues and ultimately lead to loss of control.
The Anthropic Institute (in collaboration with external stakeholders) will conduct research to think through the implications of increasingly powerful, potentially self-improving systems—and how to create the ability for the world to make deliberate choices about the future development of the technology.
Read the full post: https://t.co/XkYALsONft
Ran deepseek-v4-pro through ClawMark (our living-world openclaw benchmark) — 100/100 tasks, 0.685 avg score, 40.7h total time.
Slots in at #4, just edging out kimi-k2.6 (0.684) and gemini-3.1-pro (0.682) — all three within a 0.003 window. claude-4-6 / gpt-5.4 still hold the top at 0.72–0.76.
Updated leaderboard 👇
Can confirm — K2.6 isn't just a demo-reel model.
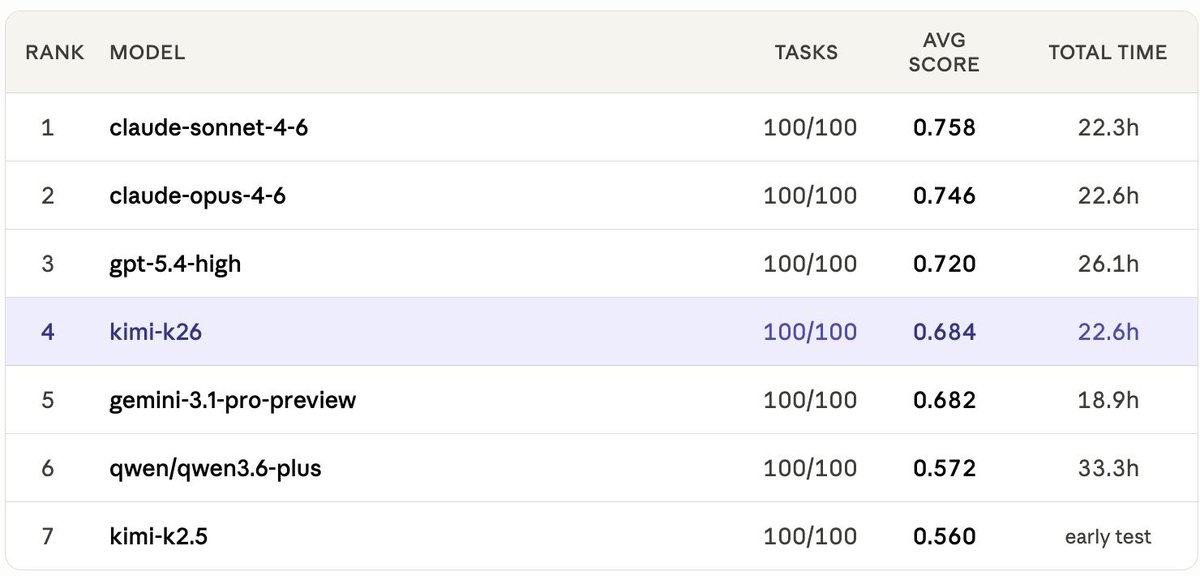
Few days ago, we received a bug report from kimi team, and we got early API access, re-ran ClawMark (our living-world openclaw benchmark). After fixing a compatibility bug in openclaw's repo (https://t.co/owWPiOuWgs), K2.6 lands at 0.684 avg score — edging out gemini-3.1-pro (0.682) and jumping +0.124 over K2.5.
Shipping shaders and agentic benchmark gains in the same release is a pretty rare combo. 👀
Can confirm — K2.6 isn't just a demo-reel model.
Few days ago, we received a bug report from kimi team, and we got early API access, re-ran ClawMark (our living-world openclaw benchmark). After fixing a compatibility bug in openclaw's repo (https://t.co/owWPiOuWgs), K2.6 lands at 0.684 avg score — edging out gemini-3.1-pro (0.682) and jumping +0.124 over K2.5.
Shipping shaders and agentic benchmark gains in the same release is a pretty rare combo. 👀
@shao__meng Can confirm: K2.6 is not a demo. It’s a production-grade beast. Our benchmark says it all: https://t.co/RDdk22LIpa Open source is eating the world.
Can confirm — K2.6 isn't just a demo-reel model.
Few days ago, we received a bug report from kimi team, and we got early API access, re-ran ClawMark (our living-world openclaw benchmark). After fixing a compatibility bug in openclaw's repo (https://t.co/owWPiOuWgs), K2.6 lands at 0.684 avg score — edging out gemini-3.1-pro (0.682) and jumping +0.124 over K2.5.
Shipping shaders and agentic benchmark gains in the same release is a pretty rare combo. 👀
Launch Week — Day 1: ClawMark
Most agent benchmarks give the model one shot, one prompt, one frozen environment.
Real coworker tasks span multiple days — and the world keeps changing while the agent works.
Introducing 🦞ClawMark: a multi-day, dynamic-environment benchmark for coworker agents. Built by Evolvent together with 40+ researchers from NUS, HKU, MIT, UW, and UC Berkeley. Open-sourced at: https://t.co/QN7XgIoaN1
100 tasks. 13 professional domains. Fully rule-based scoring.
Results from 6 frontier models below. 🧵👇
@_akhaliq Verified: K2.6 is the real deal 🚀 Outperformed Gemini 3.1 Pro on our ClawMark living-world benchmark. Read our full analysis: https://t.co/RDdk22LIpa
Can confirm — K2.6 isn't just a demo-reel model.
Few days ago, we received a bug report from kimi team, and we got early API access, re-ran ClawMark (our living-world openclaw benchmark). After fixing a compatibility bug in openclaw's repo (https://t.co/owWPiOuWgs), K2.6 lands at 0.684 avg score — edging out gemini-3.1-pro (0.682) and jumping +0.124 over K2.5.
Shipping shaders and agentic benchmark gains in the same release is a pretty rare combo. 👀
Can confirm — K2.6 isn't just a demo-reel model.
Few days ago, we received a bug report from kimi team, and we got early API access, re-ran ClawMark (our living-world openclaw benchmark). After fixing a compatibility bug in openclaw's repo (https://t.co/owWPiOuWgs), K2.6 lands at 0.684 avg score — edging out gemini-3.1-pro (0.682) and jumping +0.124 over K2.5.
Shipping shaders and agentic benchmark gains in the same release is a pretty rare combo. 👀
@cgtwts Can confirm: K2.6 is not a demo. It’s a production-grade beast. Our benchmark says it all: https://t.co/RDdk22LIpa Open source is eating the world.
Can confirm — K2.6 isn't just a demo-reel model.
Few days ago, we received a bug report from kimi team, and we got early API access, re-ran ClawMark (our living-world openclaw benchmark). After fixing a compatibility bug in openclaw's repo (https://t.co/owWPiOuWgs), K2.6 lands at 0.684 avg score — edging out gemini-3.1-pro (0.682) and jumping +0.124 over K2.5.
Shipping shaders and agentic benchmark gains in the same release is a pretty rare combo. 👀
Can confirm — K2.6 isn't just a demo-reel model.
Few days ago, we received a bug report from kimi team, and we got early API access, re-ran ClawMark (our living-world openclaw benchmark). After fixing a compatibility bug in openclaw's repo (https://t.co/owWPiOuWgs), K2.6 lands at 0.684 avg score — edging out gemini-3.1-pro (0.682) and jumping +0.124 over K2.5.
Shipping shaders and agentic benchmark gains in the same release is a pretty rare combo. 👀
@chetaslua Price, performance, open weights—name a better combo. We put it to the test on the ClawMark, our live agent benchmark: https://t.co/RDdk22LIpa
Can confirm — K2.6 isn't just a demo-reel model.
Few days ago, we received a bug report from kimi team, and we got early API access, re-ran ClawMark (our living-world openclaw benchmark). After fixing a compatibility bug in openclaw's repo (https://t.co/owWPiOuWgs), K2.6 lands at 0.684 avg score — edging out gemini-3.1-pro (0.682) and jumping +0.124 over K2.5.
Shipping shaders and agentic benchmark gains in the same release is a pretty rare combo. 👀
Can confirm — K2.6 isn't just a demo-reel model.
Few days ago, we received a bug report from kimi team, and we got early API access, re-ran ClawMark (our living-world openclaw benchmark). After fixing a compatibility bug in openclaw's repo (https://t.co/owWPiOuWgs), K2.6 lands at 0.684 avg score — edging out gemini-3.1-pro (0.682) and jumping +0.124 over K2.5.
Shipping shaders and agentic benchmark gains in the same release is a pretty rare combo. 👀
Can confirm — K2.6 isn't just a demo-reel model.
Few days ago, we received a bug report from kimi team, and we got early API access, re-ran ClawMark (our living-world openclaw benchmark). After fixing a compatibility bug in openclaw's repo (https://t.co/owWPiOuWgs), K2.6 lands at 0.684 avg score — edging out gemini-3.1-pro (0.682) and jumping +0.124 over K2.5.
Shipping shaders and agentic benchmark gains in the same release is a pretty rare combo. 👀
Can confirm — K2.6 isn't just a demo-reel model.
Few days ago, we received a bug report from kimi team, and we got early API access, re-ran ClawMark (our living-world openclaw benchmark). After fixing a compatibility bug in openclaw's repo (https://t.co/owWPiOuWgs), K2.6 lands at 0.684 avg score — edging out gemini-3.1-pro (0.682) and jumping +0.124 over K2.5.
Shipping shaders and agentic benchmark gains in the same release is a pretty rare combo. 👀
@kanavtwt Verified: K2.6 is the real deal 🚀 Outperformed Gemini 3.1 Pro on our ClawMark living-world benchmark. Read our full analysis: https://t.co/RDdk22LIpa
Can confirm — K2.6 isn't just a demo-reel model.
Few days ago, we received a bug report from kimi team, and we got early API access, re-ran ClawMark (our living-world openclaw benchmark). After fixing a compatibility bug in openclaw's repo (https://t.co/owWPiOuWgs), K2.6 lands at 0.684 avg score — edging out gemini-3.1-pro (0.682) and jumping +0.124 over K2.5.
Shipping shaders and agentic benchmark gains in the same release is a pretty rare combo. 👀
@mervenoyann Can confirm — K2.6 isn’t just a demo-reel model. It outperformed Gemini 3.1 Pro on ClawMark. Our independent test: https://t.co/RDdk22LIpa
Can confirm — K2.6 isn't just a demo-reel model.
Few days ago, we received a bug report from kimi team, and we got early API access, re-ran ClawMark (our living-world openclaw benchmark). After fixing a compatibility bug in openclaw's repo (https://t.co/owWPiOuWgs), K2.6 lands at 0.684 avg score — edging out gemini-3.1-pro (0.682) and jumping +0.124 over K2.5.
Shipping shaders and agentic benchmark gains in the same release is a pretty rare combo. 👀
@JulianGoldieSEO Kimi 2.6 just proved it’s NOT a demo-reel model! We tested it on ClawMark and it beat Gemini 3.1 Pro. Full results: https://t.co/RDdk22LIpa
Can confirm — K2.6 isn't just a demo-reel model.
Few days ago, we received a bug report from kimi team, and we got early API access, re-ran ClawMark (our living-world openclaw benchmark). After fixing a compatibility bug in openclaw's repo (https://t.co/owWPiOuWgs), K2.6 lands at 0.684 avg score — edging out gemini-3.1-pro (0.682) and jumping +0.124 over K2.5.
Shipping shaders and agentic benchmark gains in the same release is a pretty rare combo. 👀