FastRouter⚡️ is a lightning-fast gateway to top LLMs. Connect to GPT-4, Grok 4, Claude & more with just one API. Signup and get free tokens to build your AI App
We fine-tuned a 4B model on synthetic browser trajectories and benchmarked it against frontier APIs.
The local model costs $0 per call and matches the cheap API tier statistically.
The real lesson is not which model wins. It is that routing beats picking.
Full article: https://t.co/X6plXYxe25
@_itsjustshubh Completely agree. The model is rarely the culprit. FastRouter captures full traces on every request including tool calls and intermediate steps so when the orchestration layer breaks you can actually see where it happened rather than guessing.
Completely agree and this is fixable at the infrastructure level. FastRouter's Auto Router automatically selects the most cost efficient capable model for each request so you stop paying frontier prices for tasks that do not need them. Same output quality, fraction of the cost. Worth a look at https://t.co/swtvB5hgeb"
This is the second post in our Architect-Editor series. The first one showed how we cut AI agent costs by 55% using a hybrid cloud and local model pipeline.
This one goes under the hood and shows exactly how we configured it.
Inside, you will find the full step-by-step FastRouter BYOK setup, how we exposed a local Ollama instance as a provider, and the code we used to route specific tasks to specific models through a single API endpoint.
https://t.co/sHJwROlYUK
Most teams route everything to the frontier because building the routing logic is the work they haven't done yet. https://t.co/L13Gr2cgju's Auto Router handles this automatically — classifies each request and routes to the cheapest capable model. The cost difference across a real workload is usually 40-60%.
@VibeCoderOfek https://t.co/hEkabCzezt's gateway overhead is under 10ms at any scale — tracing, cost attribution, and alert hooks all happen without adding meaningful latency to the request path. If you're seeing overhead compound in agent loops, worth checking where it's actually coming from.
Provider diversity as a reliability decision is the right framing — and the hard part is operationalising it without maintaining separate integrations per provider. https://t.co/L13Gr2cgju gives you the portfolio through one API with automatic failover, so the diversity is real rather than theoretical.
Step 95 failures in long-running agents are usually provider reliability issues underneath the checkpointing problem. Cross-provider failover means the agent can keep going when one provider has issues mid-run — the checkpointing and idempotency layer still matters, but it fails a lot less often when the underlying routing is resilient.
Cost explosion in agent loops is almost always a routing problem — expensive frontier models handling steps that didn't need them, retries compounding, no visibility into which step caused the spike. https://t.co/L13Gr2cgju gives you per-step cost attribution and lets you route routine steps to cheaper models without changing your agent logic.
Reserved capacity at one provider still doesn't cover outages or other providers going slow. Most user-facing apps we see routing across multiple backends stay online through the kinds of incidents that take down single-provider setups — without paying reserved rates. Worth comparing the two approaches before committing.
Four 20X subscriptions and still hitting walls is the clearest signal that the problem is routing, not subscription tier. In case you want to use Claude Code with other good coding models - e.g. DeepSeek v4 Pro, you can check out FastRouter. Here is a doc to help you get started: https://t.co/XpPu8bfslL
This is exactly what https://t.co/L13Gr2cgju's category routing does — frontier for complex reasoning, cheaper models for classification and boilerplate, and BYOK for private/local endpoints, all through one API. The routing logic is configurable per task type without changing your application code. Worth a look at https://t.co/IFOGbG8Acx if you're building this out.
This is the argument most teams only internalise after the first production latency incident. If routing is a priorirty, check the model catalog for fast models. You can route specific categories of requests to a faster cheaper model, and reserving others for frontier models. https://t.co/L13Gr2cgju offers a lowest latency routing strategy apart from category routing to help you route to faster models or based on the category of requests.
1 in 5 calls going to retries is brutal when each one burns full context and 2-3s. Routing to a model that handles structured output reliably upfront — rather than retrying — is usually the cleaner fix. https://t.co/L13Gr2cgju makes switching models a one-line change so you can test which actually behaves on your prompts.
One billing issue taking out your whole stack is a pattern we see constantly. https://t.co/L13Gr2cgju routes across providers automatically — when one has issues the request moves on without you noticing. Happy to share how other teams have set this up if you're iterating on resilience.
Your batch jobs are running on real-time pricing.
One suffix change that.
openai/gpt-5.4-nano → openai/gpt-5.4-nano:flex
Same model. Same quality. ~50% cheaper.
https://t.co/Sy4mWXdnAD
You're paying for the same tokens on every request.
The same system prompt. The same knowledge base. Every call, full price.
Prompt Caching on FastRouter fixes this automatically. For most providers — OpenAI, DeepSeek, Gemini — zero code changes. Cache hits come back at 0.10x input price.
For Anthropic Claude: one field. One line of JSON.
Microsoft canceled Claude Code licenses because token costs were untenable. Uber burned its entire 2026 AI budget in four months.
This week, we shipped something relevant: Claude Code now works with any model on FastRouter. Route it through DeepSeek, Gemini, Grok, OpenAI, Minimax and more — whatever fits your cost structure. Automatic fallback when a provider spikes.
The flat-rate era is ending. Intelligent routing is how you survive what comes next.
https://t.co/W9piZQGQZc
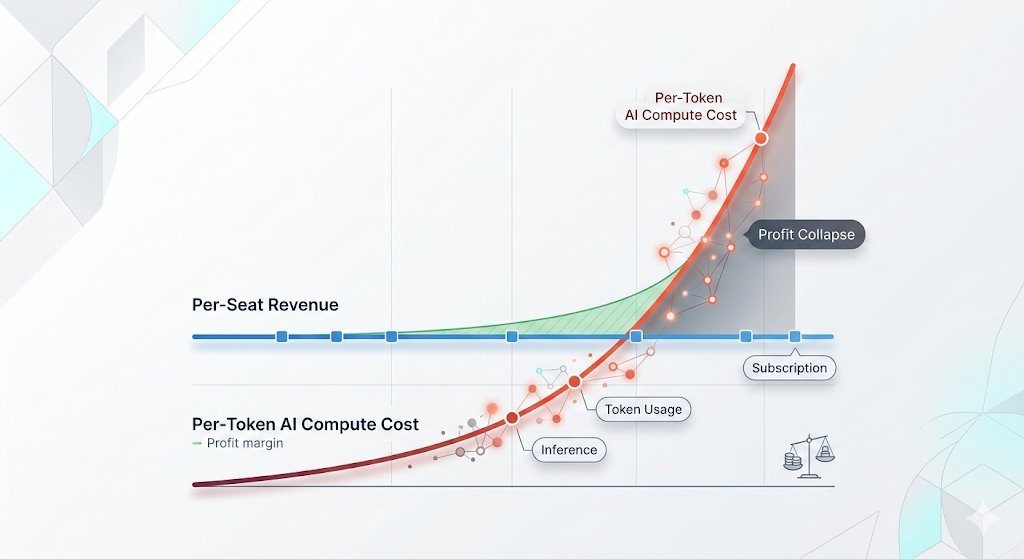
🦔Microsoft canceled its internal Claude Code licenses this week after token-based billing made the cost untenable, even for a company with effectively infinite cloud resources. Uber's CTO sent an internal memo warning the company burned through its entire 2026 AI budget in just four months. American AI software prices have jumped 20% to 37%, and GitHub (owned by Microsoft) is dropping flat-rate plans for usage-based billing across its products.
My Take
The AI subsidy era is ending in real time. The same company that put $13 billion into OpenAI and built the Azure infrastructure powering most of Anthropic's compute just looked at the bill from a competitor's coding tool and decided it was not worth paying. That is not a productivity failure on Anthropic's end. Token-based pricing is forcing every enterprise customer to confront the actual cost of running these models at scale, and the number turns out to be far higher than the flat-rate experiments suggested.
This ties directly to my Gemini Flash post yesterday. Anthropic, OpenAI, and Google all raised effective prices in the last six months. Enterprises that built workflows assuming AI costs would keep falling are now watching annual budgets evaporate in months. Two outcomes look likely from here. Either enterprises scale back AI usage to fit budgets, which slows the revenue ramp the labs need to justify their valuations ahead of IPOs, or the labs cut prices and absorb the losses, which makes the unit economics worse at exactly the wrong moment. Both paths land in the same place, the numbers stop working, and somebody has to take the writedown.
Hedgie🤗
The AI subsidy era is ending in real time — this is a really important framing.
We shipped something this week that's directly relevant: Claude Code now works with any FastRouter model, not just Anthropic. So if token costs on one provider become untenable, you can route to DeepSeek, Gemini, Grok, OpenAI, Minimax and more — whatever makes sense for your budget — without touching your workflow.
Might be useful context for teams watching their 2026 AI budgets disappear faster than expected.