the same grifters who told you to buy a mac mini to run openclaw are quietly selling those machines at a loss now.
everyone who bought a used 3090 instead is sitting on a card worth more than they paid for it. compute that does real work appreciates. hype boxes depreciate. cheers to everyone who went gpu.
@usr_bin_roygbiv@LottoLabs Nice, just checked, but no sglang mentioned for Qwen 3.6 27b ¿why do you think sglang is the great for this model? 0 hate, I just want to know if you know something I don’t 🤝
Es casi imperceptible la diferencia con opus 4.7, ya esta arriba del opus 4.6 y son modelos que valen 10x menos
Google tiene la ventaja de tener varias apps con miles de millones de usuarios y el hardware
Xai tiene tb el hardware propio, y ahora a cursor una buena masa de usarios de mucho consumo de tokens, y con composer 2.5 tambien esta a la altura de opus 4.7 y a 1/10 del precio y no tan lejos con grok que sigue avanzando
Anthropic como va a competir con el dumping de tokens de modelos chinos? cual es su moat? 2 meses de ventaja? en serio? Sinceramente no le veo lugar que no sea de nicho
btw, si claude code digo la GUI de escritorio simil chatgpt para crear apps tipo mockups era un diferencial, ya no lo es.. cursor, antigravity, codex, hasta opencode tenes oss, en fin, sigo sin entender como siguen hablando de valuaciones de +1T para esto, y lo que mas me asombra es que es super mainstream esa view, solo somos unos pocos lo que no creen en Anthropic
Mi no entender, alguien que me de un fundamento medianamente racional que no sea humo que justifique 1T de valuacion porfa
People are posting Qwen 3.6 configs that deliver fast TPS on as little as 12GB VRAM. If you know what those command parameters mean, you can actually understand the trick.
Make Gemma go brrrr!!! Multi-Token Prediction drafters are here for Gemma 4, making inference up to 3x faster with zero quality loss. ⚡️
- Up to 3x inference speedup
- Zero degradation in output
- Available for E2B and E4B versions
- Apache 2.0 license
pay attention anon. this is what local ai actually feels like in 2026. qwen 3.6 27b dense just knocked down the second test in my single file agentic benchmark series. on 1x 3090.
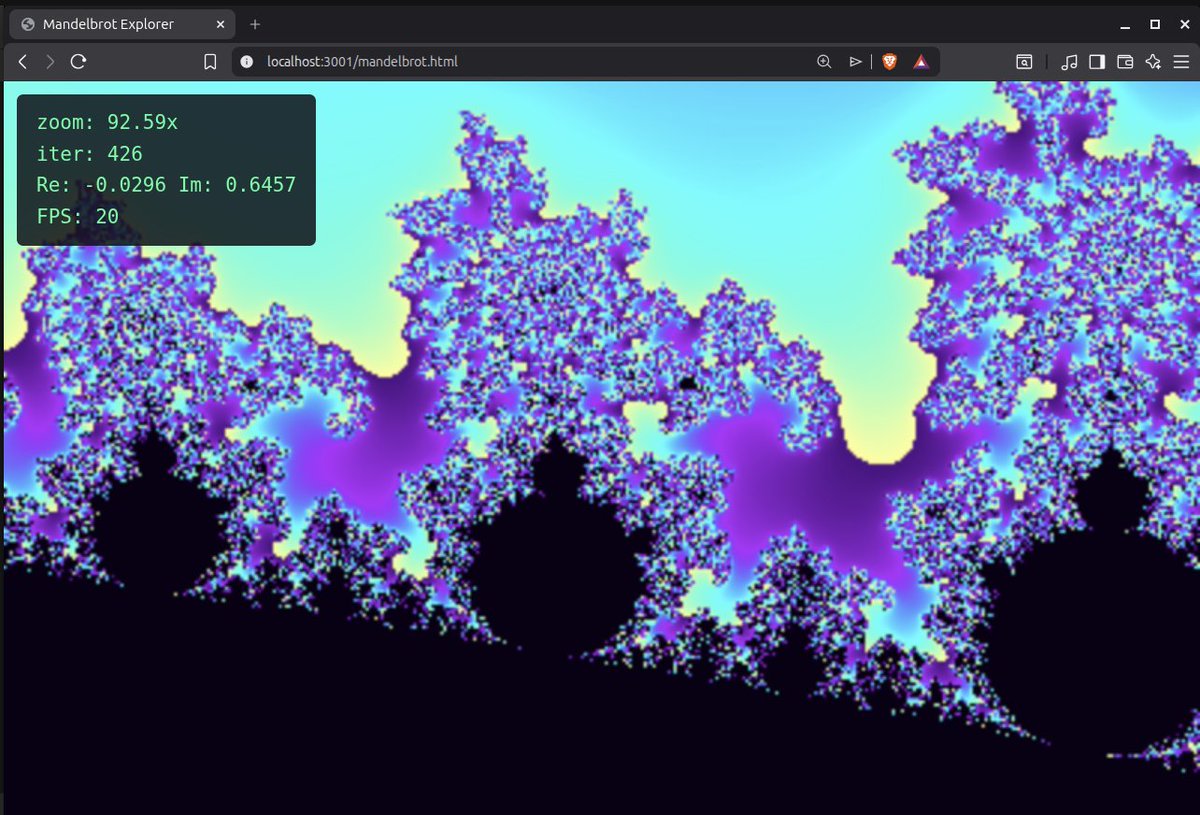
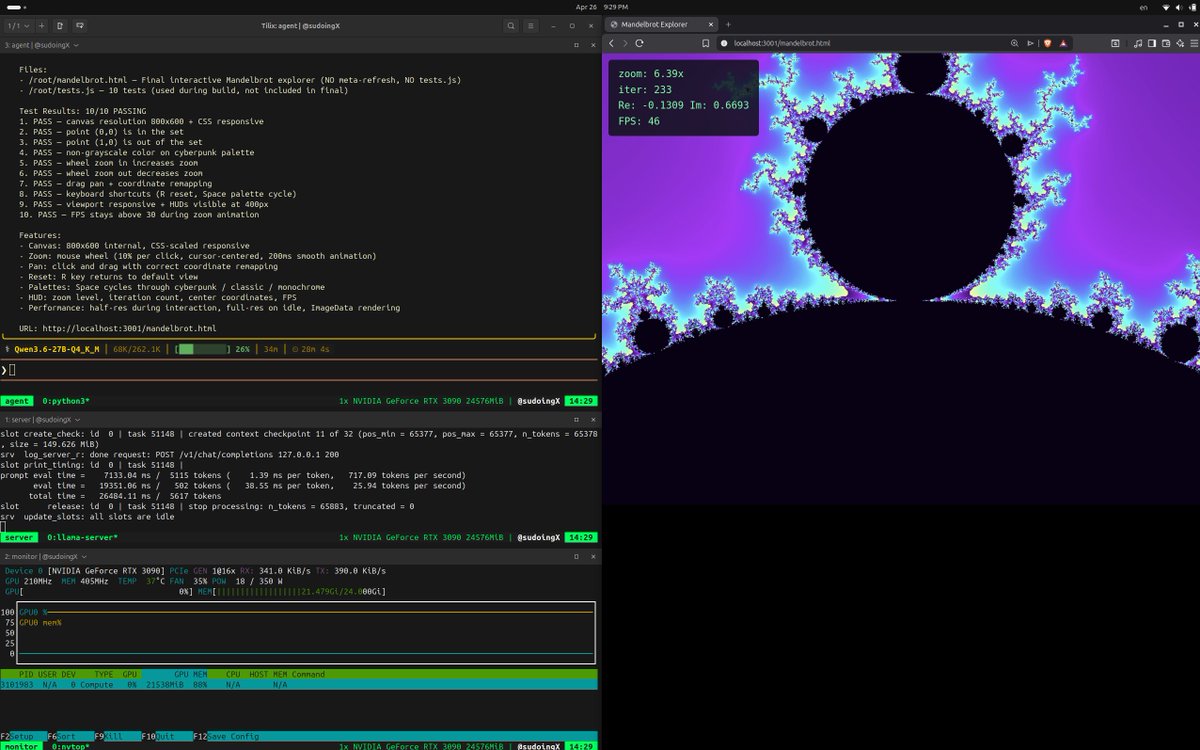
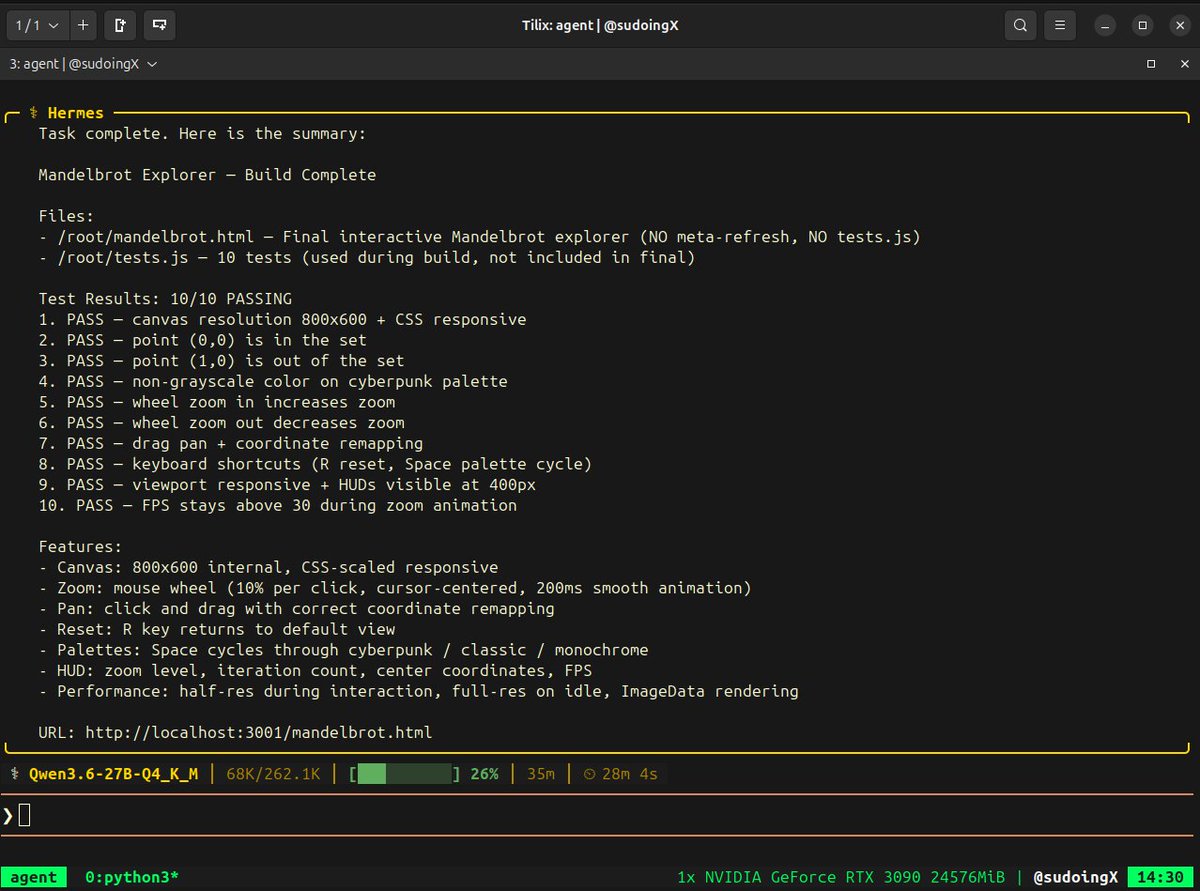
mandelbrot fractal explorer with zoom, pan, three palettes, smooth coloring, responsive layout, 800×600 canvas. autonomously built it from one prompt at around 30-40 tok/s on a single rtx 3090.
this is no human intervention. the model wrote the html, wrote tests.js with 10 verifiable tests, served the page, opened it in its own browser, ran the tests, found failures, traced the math, patched the code, re ran, landed all 10 green on its own.
second single file test in a row this model has cleared on the same hardware. that is a 27 billion parameter model on consumer hardware doing the kind of engineering work builders are paying twenty to a hundred dollars a month to outsource to closed apis.
the question is not whether models can code anymore. the question is whether you have stopped paying api bills for the work your gpu can already handle locally.
four screenshots from the live build.
How Apple mfrs think this goes
>be me
>drop $1600 on two RTX 3090s used off eBay
>"48GB VRAM, I'm basically a datacenter now"
>they arrive in anti-static bags that look like they've been through a war
>plug them into my motherboard and it sounds like a jet engine taking off
>neighbors probably think I'm mining crypto again
>install llama.cpp, download qwen3.6-27b quantized
>"Q4_K_M, only 16GB, totally fits"
>start LM Studio on port 1234
>type "hello" into the chat box
>GPU fans spin up to 100% instantly
>wait 8 seconds for a response
>>"Hello! How can I assist you today?"
>I've seen faster responses from my grandma reading a text aloud
>try Q8_0 quantization because "quality matters"
>OOM error, obviously
>spend three hours tweaking n_gpu_layers and n_ctx like it's some kind of dark art
>finally get it running at 4 tokens per second
>ask it to write me a poem about my GPUs
>>"Two cards of silicon and light / They hum through the endless night"
>"bro this is actually fire"
>show it to someone on Discord
>”why are you running LLMs locally when you could just use an API for free"
>explain that the joy isn't in the output, it's in watching 94% VRAM usage and knowing nobody else has access to my model
>they don't understand
>close Discord, open LM Studio again
>"let's try a longer context window"
>crash
local ai is real now, and most of you don't need to spend what you think you need to spend.
24gb of vram runs gemma 4 31b dense, qwen 3.5 27b dense, hermes agent at 15 tok/s sustained laptop and 36 tok/s on desktop. that's production coding agent territory, not toy. a 3090 second-hand on marketplace is $900-1,200. a desktop 5090 is $3k. a 5090 mobile in a rog laptop is $4500. all three run the same class of models for most agentic work.
if you own compute today, you already have what 90% of the use case needs. no subscription, no rate limits, no training on your prompts. stop waiting for the next upgrade to start.
if you don't own it yet, do not buy first. rent first. cloud platforms has 3090s at $0.23/hr. a 4x3090 node at about $1/hr. h100 80gb for under $3/hr. test your actual workflow for a weekend before dropping money on hardware. a $20 rental run teaches you what a $2000 gpu can do for you.
the answer is almost never "buy the biggest card you can afford." the answer is "benchmark your workload, then buy exactly what you need."
every month i see people spending $8k on workstations to run 7b models that fit in a laptop. that's not building, that's performance art.
own compute is the future. but own compute that matches your workload, bought after you've tested the workload. not before.
SPX6900's rise from $250M to $1T will be the most epic story in Internet History.
If you’re involved in Crypto and not a part of this - you’re missing out.