The hidden math of @solana RPC pricing
Most providers charge per credit or per call.
We charge per byte.
Here's what that actually means...
━━━━━━━━━━━━━━━
Per 1,000 getAccountInfo calls
(Solana's most-called method):
@FluxRPC → $0.0000234
Credit provider → $0.05
PAYG provider → $0.01
FluxRPC vs Credit provider: 2,133× cheaper
FluxRPC vs PAYG provider: 428× cheaper
━━━━━━━━━━━━━━━
"But surely on heavy calls you lose?"
getProgramAccounts (5 MB payload):
FluxRPC → $0.293 per 1k calls
Credit provider → $0.500 per 1k calls
PAYG provider → $0.401 per 1k calls
Why?
One charges 10 credits per gPA call.
The other charges $10 per million calls flat.
FluxRPC just charges for the bytes.
━━━━━━━━━━━━━━━
Plan-for-plan capacity:
$38/mo FluxRPC = 655M getAccountInfo calls
$49/mo credit provider = 10M calls
$849/mo FluxRPC = 40.3B getAccountInfo calls
$999/mo credit provider = 200M calls
201x more calls.
$150 cheaper.
━━━━━━━━━━━━━━━
gRPC streaming (1 TB/mo):
FluxRPC → $61.44
Credit provider → $157.29
PAYG provider → $81.92
Same gRPC. Different bill.
━━━━━━━━━━━━━━━
And here's the part nobody talks about.
Just to ACCESS mainnet gRPC:
FluxRPC → $38/mo (Develop plan)
PAYG provider → $125 prepaid minimum
Credit provider → $499/mo (Business plan)
13x price gap before you stream a single byte.
Same data. Just paywalled differently.
━━━━━━━━━━━━━━━
No credit games.
No method weighting.
No per-call fee addon.
No overage premiums.
No absurd gRPC paywall.
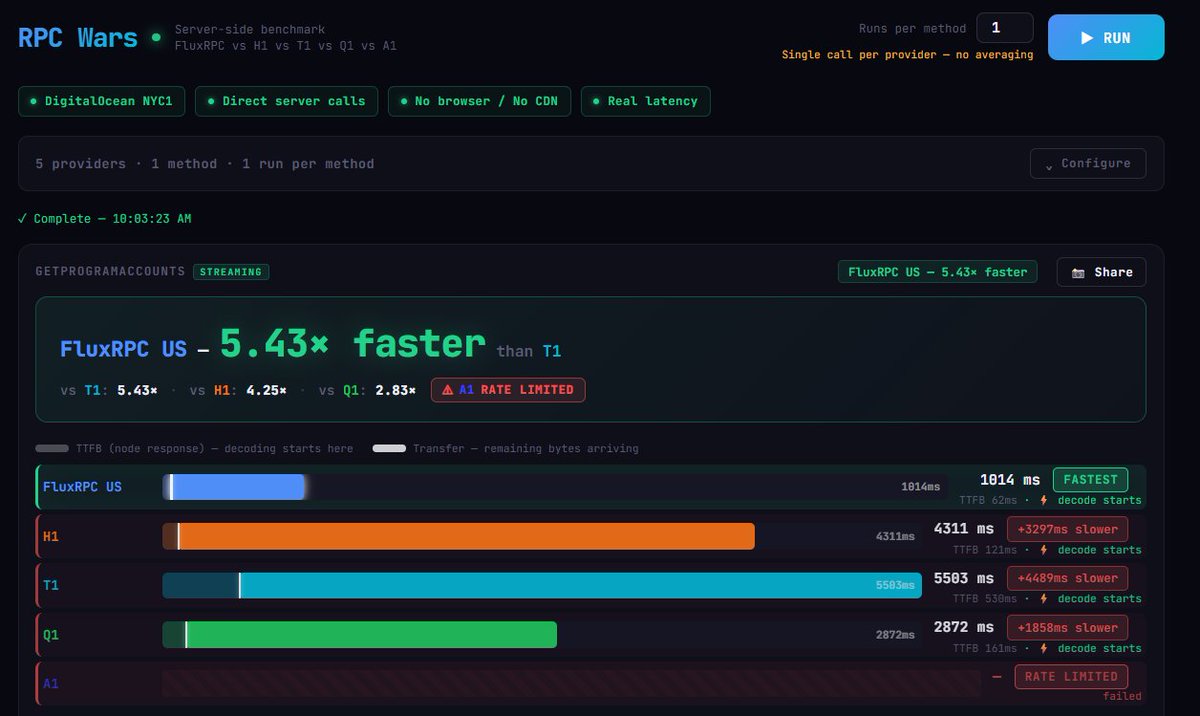
gPA on OreV2
TTFB - @FluxRPC is
- 2x faster vs next best.
- 3x faster vs 3rd place.
- 8x faster vs 4th best.
Total Time - FluxRPC is
- 2x faster vs next best.
- 4x faster vs 3rd best.
- 5x faster vs 4th best.
Higher RPS, No credits, Faster.
If you haven't already - try it out!
@dlo202 Latency depends on your location and setup, but we have tests in the previous posts showing 10-30x faster vs legacy rpc's. We will be faster, I just can't say by how much. Give it a try!
HTTP/3 + QUIC is now live on every @FluxRPC endpoint.
The upgrades you'll feel:
→ Faster connections - fewer round trips before your first request lands
→ Independent parallel streams - one slow request no longer blocks the others
→ Better performance on mobile, bad wifi, packet loss, and cross-region traffic
→ Connection migration - survives wifi-to-cellular switches without dropping
→ Lower tail latency at scale
Whether you're shipping a dApp, running a trading desk, indexing onchain data, or powering a backend service... your stack just got faster.
Two things would move the needle for us.
1. @FluxRPC isn't listed on https://t.co/3aKrr4ge0G despite being a production RPC provider serving the ecosystem. Proper channels are not responsive, requests were made months ago with lots of private follow up. Getting added would help builders discover an alternative.
2. We've been shipping lots of IBRL benchmarks/content. A retweet from the main account when the work earns it (we believe it has) would amplify it to the builders who care.
Your users don't see the 17 slot blackout on some legacy RPCs.
They eat the slippage. They feel it. The missed fills. The worse exit. The later entry.
And they blame your dapp. Not the RPC quietly costing them every trade. They move to someone serving true real time data.
Users pay your RPC bill, they don't care who the provider is. They care about price + speed + reliable execution.
If you choose to serve them stale data, they will eventually choose to spend elsewhere.
Up to 7 seconds. 17+ slots.
That's how long your "fast" RPC can make you wait before the first byte of a gPA response lands.
Your RPC provider is selling you latency and calling it data.
While you (your users) wait: prices move, liquidations clear, pools shift, opportunities die. Your bot reacts to a data that simply no longer exists.
So you (users) compensate:
- Prompt or preset fatter slippage. Users pay it.
- Prompt or preset higher pri fees. Users pay it.
Two taxes. One root cause.
A buffering RPC pretending it's a real-time.
Most legacy RPCs buffer-then-flush.
@FluxRPC streams decoded accounts as they're filtered. First byte in milliseconds. No 17 slot blackout.
Real-time isn't a tagline. Its how it was built.
It's whether your code is looking at the chain, or a screenshot.
Stop paying the latency tax and stop making your users pay it.
Run real-time, or get run over.
@carachae_@defipro For now - you can use the free plan and purchase bandwidth in crypto. We will take the feedback and see what else we can do for this as well. Thank you!
Kind of crazy what you can build with @Rugcheckxyz API's, its a game changer. Combine that with agents, and it really opens the options and speed to market for new builders.
Wouldn't be surprised to see a ton of @colosseum entrants using these and the new dexstream/data API's to get a big head start.
IBRL
@FluxRPC is the future.
Whats crazy is in some cases we return all the gPA data before other providers even respond (TTFB)
Think about that for second, their TTFB lands after our TTLastByte.
You're frontrunning yourself at this point.
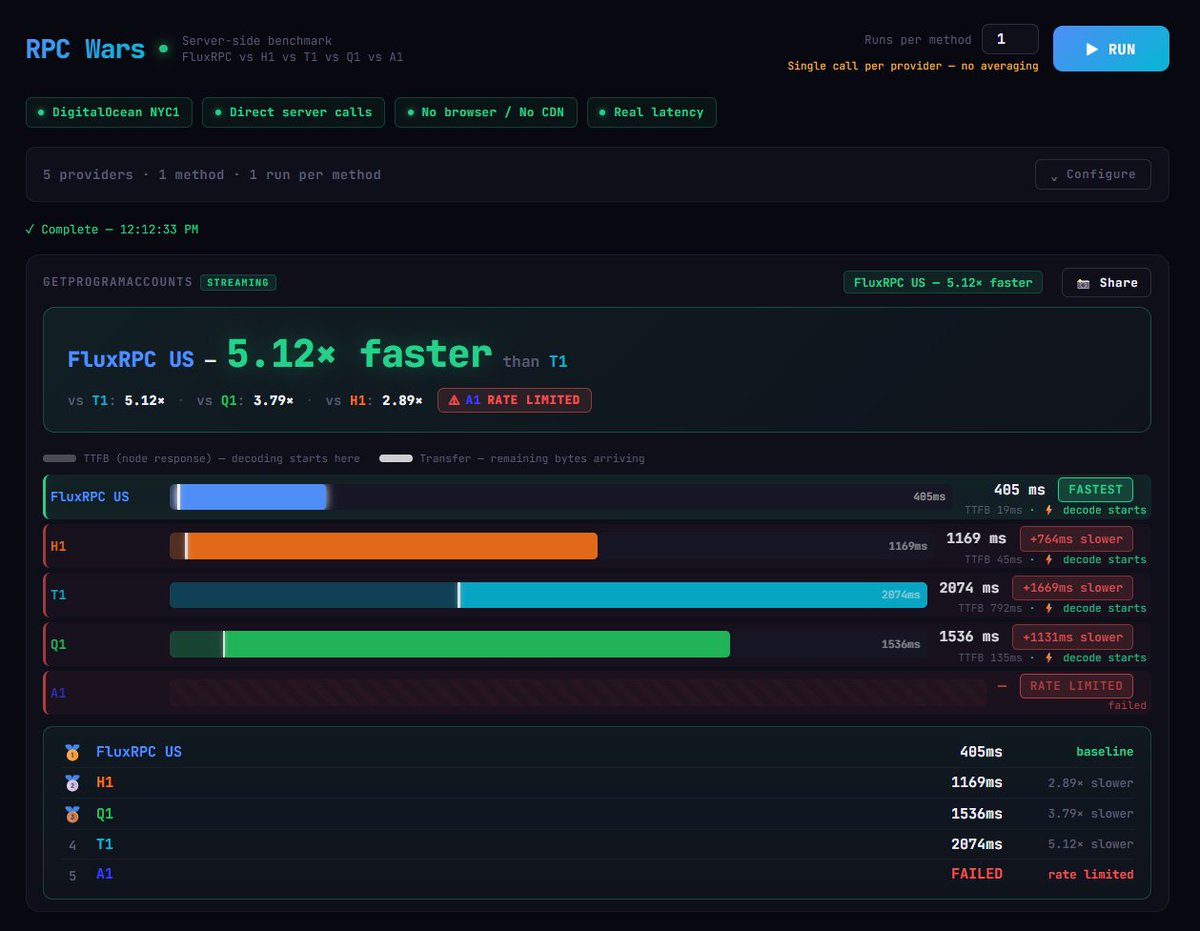
Forget the headline number for a (milli)sec.
Yes, we beat the slowest, easy win, ignore it. Look at the rest: 6x, 6x, 9x faster. Not close.
Fair comparison to legacy RPC? No. This is Lantern, local edge caching with @FluxRPC.
Free add-on. Any plan. No upsell.
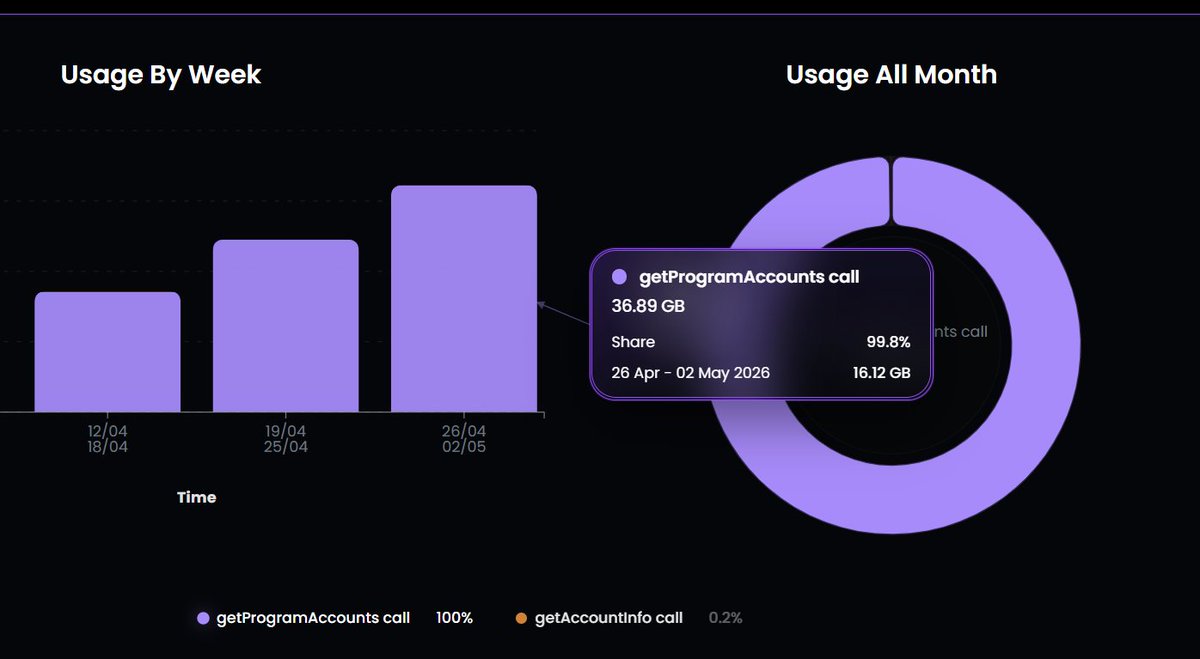
Added in some QOL improvements into the usage dashboard for @FluxRPC
Also noticed when setting up benchmarking, some RPC's limit the endpoints you can create on a free plan, we don't.
Is this IBRL on @solana
4x+ faster on gPA, we didn't stop there.
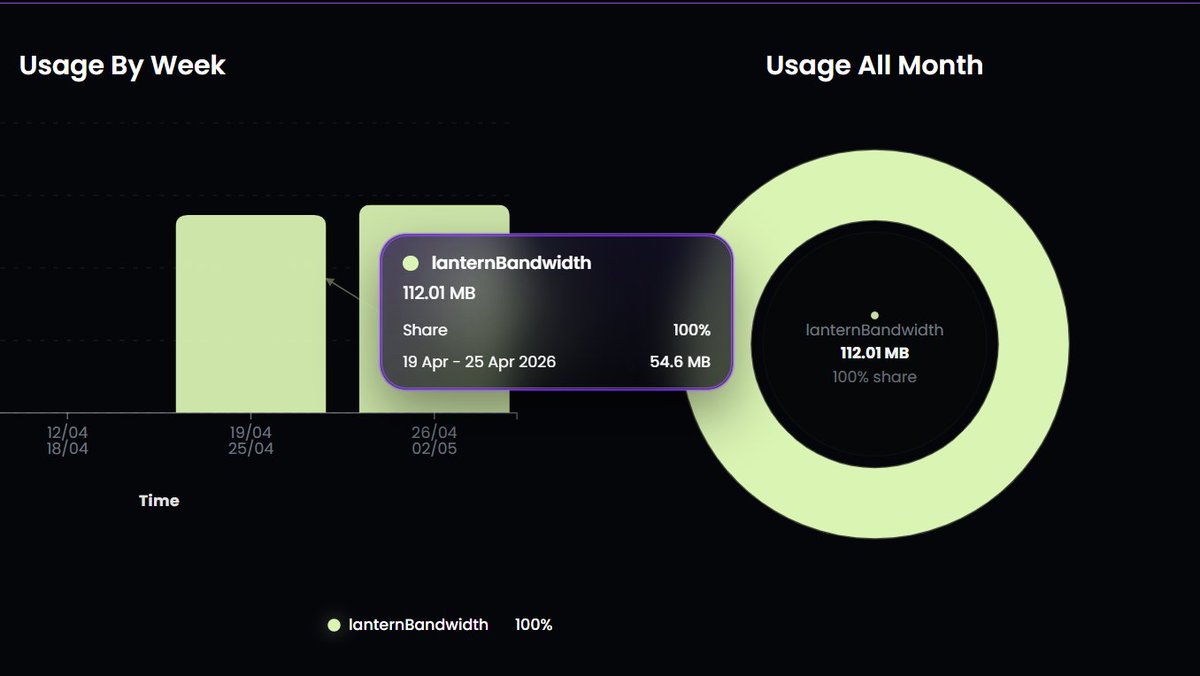
FluxRPC Lantern, caching at your edge, not theirs:
getMultipleAccounts: 10-20x faster
getAccountInfo: 10-20x faster
getBalance: 10-20x faster
And cheaper. Cached reads don't cost bandwidth.
Faster. Cheaper. Yours.
Proof 👇