We offer fully managed data extraction and automation services that excel in sourcing, crawling, extracting, parsing, structuring, and delivering datasets.
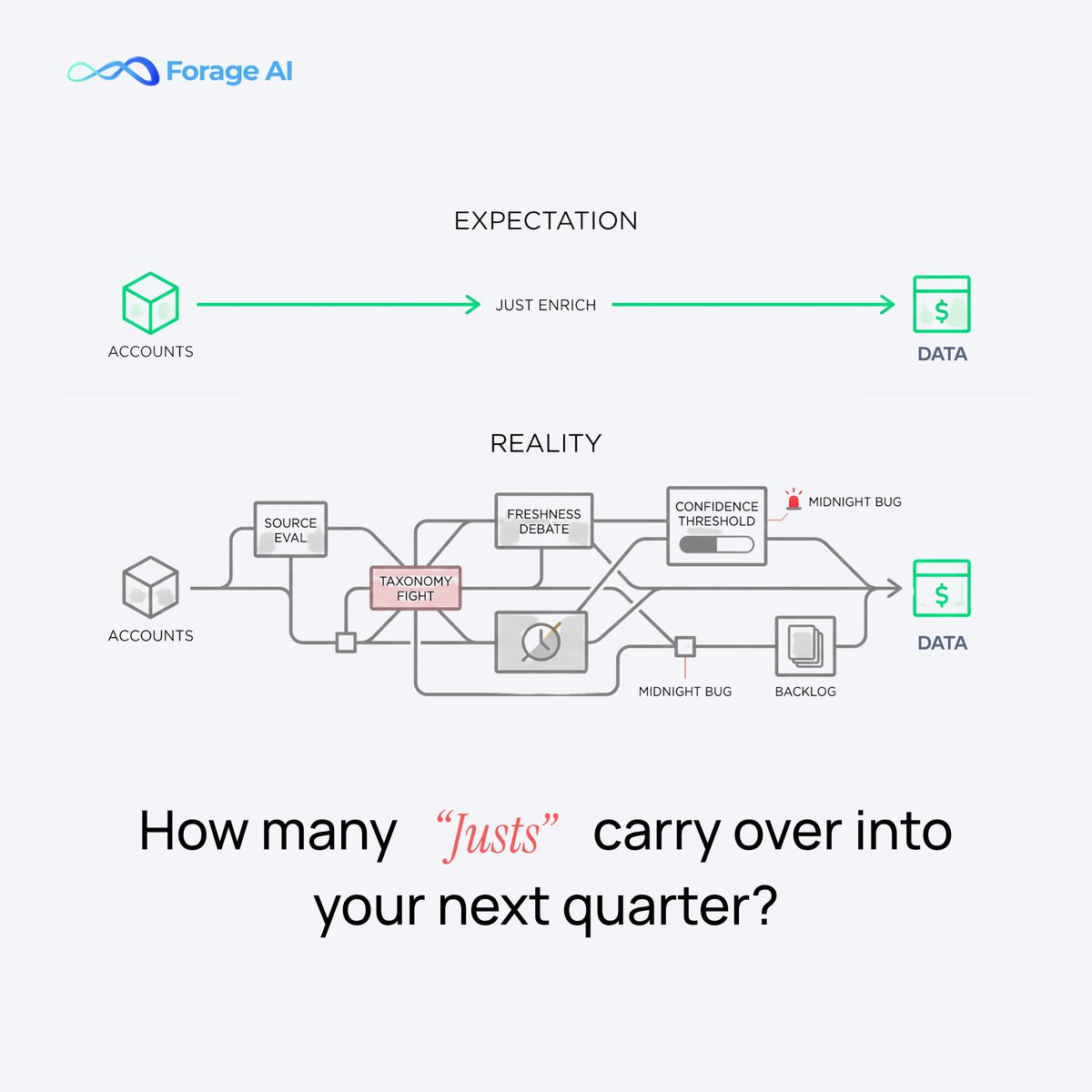
The two most expensive words in a data project: "just enrich." 💰
Behind that "just" is a team doing the math nobody else will. The bug found at midnight. The footnote everyone skips. Another ticket on a pipeline that's still being built.
#DataOps#DataQuality#DataPipelines
To all the Mama Bears at Forage AI, the moms, and everyone else who show up like one, we want to say thank you.
Happy Mother's Day.
https://t.co/1Kvs34qA9l
"Do. Or do not. There is no try." — Yoda, who clearly never had to debug a scraper at 2am
Most teams try web data extraction just to discover 1/3 of their URLs are dead, half the fields are empty, & the schema changed at midnight.
Stop trying. Start Foraging
#MayTheFourthDay
Read this article to study why product teams often regret building web scraping tools in-house, the common mistakes they encounter, and how to avoid them.
https://t.co/Y7Idceh5z9
Healthcare data extraction requires adaptive intelligence to streamline operations, ensuring accuracy and efficiency across diverse sources and changing formats.
Full guide: https://t.co/tWejzMpNxw
What data should we use to train our models?
Public data gives access to a broad set of insights and trends. Private data, on the other hand, offers detailed and reliable information that can make results more accurate and relevant.
https://t.co/WywDFh5pKL
Getting a massive spreadsheet of raw data is not helpful if your team has to spend days cleaning it up.
Don’t let messy data hold you back. Pick a solution that gives you information you can trust.
Here’s a guide to help you find the right solution: https://t.co/1BP6b0krEG
When you use off-the-shelf web crawlers, it’s like asking a stranger to find information for you; they return generic results, and you may be at risk.
Choose a custom web crawling solution that truly understands your business.
https://t.co/KXqrRNc5cO
When you try to collect more data, you often end up spending more money, hiring more people, or working longer hours. This cycle can be tiring and eventually slows down your growth.
Here's a smarter solution: https://t.co/KXqrRNc5cO
Generic web scraping casts a wide, sloppy net. The result? You end up with unstructured chaos that creates more work than it saves.
Don’t accept average results. Choose data that truly fits your needs.
Here’s a guide to choose the right data partner: https://t.co/t0wuN1ttRR
With natural language understanding, AI agents recognize entities even when formats are inconsistent. The result: up to 80% less manual review, smarter matching across any naming format.
To learn more, visit: https://t.co/zaoq21p0wT
We no longer need to depend on fragile rules. Instead, we can create a hybrid engine that combines Large Language Models (LLMs) to interpret messy context with Knowledge Graphs to enforce solid facts.
#llm
Just like a human, the Agent doesn't panic if the underlying HTML changes. It looks at the page. It recognizes "Product Price." It recognizes "Add to Cart."
If the layout moves to the left? The Agent adjusts instantly.
Just like that.