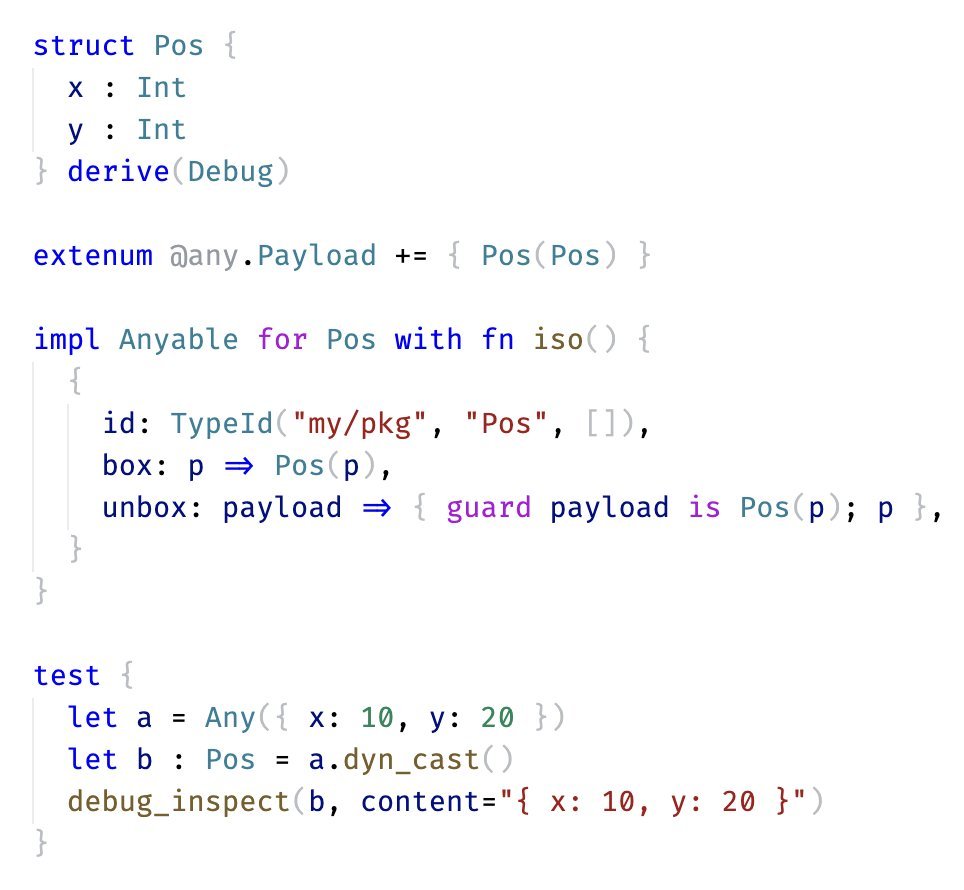
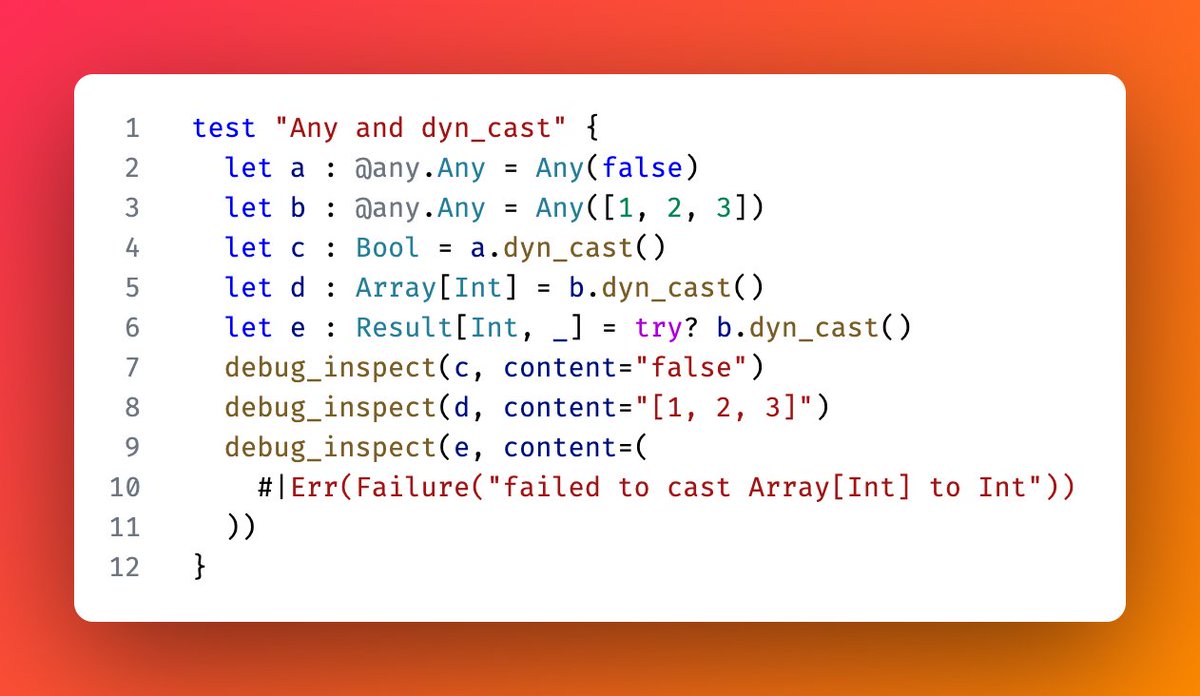
Any downcast isn’t supported in MoonBit yet due to wasm-gc limitations.
Current workarounds use unsafe intrinsics or JSON conversion, but that either gives up Wasm-gc or hurts performance.
Any better workaround? Check this:
https://t.co/MLCou0mrLa
In the stable release of @moonbitlang
We've switched the ABI of `println` to wasip1 when building an executable (`fn main`), hoping that it will increase compatibility so that people no longer need to fear of it.
The escape hatch is `MOON_WASI_LINK=0`.
Please check https://t.co/fX9Dm8SacN
I once spent a long time building the language I wanted for myself, and it happened to hit exactly the properties you mentioned, along with a type system expressive enough. when I knew MoonBit, I realized it was what I wanted
Replacing MoonBit QuickCheck FEAT with a new implementation significantly improves its performance.
The key is using IFSeq to represent finite parts, preserving random access, providing direct foreach paths for traverse/materialize, and a prefix cache to the global index.
Use Milky2018/metis in your MoonBit projects for graph partitioning, finite-element mesh partitioning, and fill-reducing ordering.
It is especially useful for scientific computing, sparse matrix preprocessing, and scheduling parallel workloads.
#moonbitlang
"Because we don't necessarily know at this point"
- commit from 2004 that still exists in Postgres today.
The below screenshot is from the `analyze.c` file in the Postgres source code. The number 300 is a hardcoded value inside of Postgres's ANALYZE code. The rationale is based on a paper entitled "Random sampling for histogram construction: how much is enough?" written in 1998 when data sizes were much smaller and hardware was much slower. The question the paper answers is: to build statistics enabling optimization of queries of unindexed data, how many rows does ANALYZE need to sample to build accurate enough statistics?
The answer is 300-ish samples for each bin you want in your equi-height histogram. Why? The paper shows that required sample size grows linearly with the number of bins but only logarithmically with table size for most cases, so you see diminishing returns beyond a few hundred samples per bin.
For instance, the default `statistics_target` is 100. That means Postgres aims to sample 300 x 100 values to build an equi-height histogram with 100 bins and while also storing the 100 most common values.
(Check out the previous post for deets on how Postgres uses equi-height histogram and most common values)
Why all this work for unindexed data?
Because in 1998, indexes were extraordinarily costly to build and maintain. Indexes took up valuable disk space, used the limited IOPs during writes and builds. Additionally table scans were slow and blocking. In 1998, hard drive performance was measured in RPMs, so talking IOPs was variable because random page seeks required waiting for the disk to rotate, and location on disk was unknown. The tests for this paper ran on Pentium 200MHz with 64MB of RAM, and a 7.2k RPM SCSI drive.
Postgres users continue to benefit from this work during the era of constrained resources. Indexes aren't free today, and you can have too many indexes, but they aren't as costly as they were. Also, unindexed data isn't as costly as it was.
The paper also acknowledges the problem is "provably difficult by establishing a limit on the achievable accuracy of estimation in the worst-case." Thus, "we devise a simple estimator which we believe is optimal." This number is a tradeoff between accuracy and performance. A smaller multiplier would lead to less accurate statistics, which could cause the planner to make bad decisions. A larger multiplier would lead to more accurate statistics, but it would also make ANALYZE slower. And remember, ANALYZE was much, much slower back then.
What does statistics_target control?
The statistics target controls the number of values stored for Most Common Values and the Equi-height Histogram. The following is true:
```
statistics_target = 100 → 30,000 samples, 100 MCVs, 100 buckets
statistics_target = 500 → 150,000 samples, 500 MCVs, 500 buckets
statistics_target = 1000 → 300,000 samples, 1000 MCVs, 1000 buckets
```
This value is set by default at the database level, and can be overridden at the column level.
```
-- Per-column override:
ALTER TABLE requests ALTER COLUMN status_code SET STATISTICS 500;
ANALYZE requests;
```
For larger databases, there is usually at least one column where a per column setting may be the right approach. Don't raise the global default just because one column needs more granularity. Given the performance gains of the underlying hardware, the performance gains from changing column statistics aren't as significant as they once were.
Has been a while since I wrote about agentic engineering, so this time around some learnings of maintaining Pi as a junior maintainer to @badlogicgames :) https://t.co/TbD9Jvqk3t
Resonate entered academia: Nazar Parnosov wrote his bachelor thesis on Distributed Asynchronous Await
Imagine my surprise when he dropped his thesis in the @resonatehqio Discord ❤️
Experimenting with a scoped UI wrapper for MoonBit Dear ImGui bindings. It’s like a trailing-lambda UI API, but more featherweight
https://t.co/mqeYMZY2oK
#moonbit#imgui
Ever wonder how debuggers actually stop a running program? I've written a deep dive into the "dance" between code, the Linux kernel, and your CPU to see the hidden mechanics of the software breakpoint. Enjoy 😉
https://t.co/w2lancM8OK
#medium#linuxkernel#linux#programming
Plugin systems usually make you pick:
- closed enums that plugins can't extend
- stringly events nobody can refactor
- global registries full of glue
MoonBit's `extenum` keeps the enum open and the patterns typed.
Extend with `+=`. Match by package name.
@moonbitlang
BREAKING CHANGE In the next release of @moonbitlang
ABI of Wasm backend will change. Pointer will now be the start of payload instead of that of the object, so no more mysterious 8 bytes when writing FFI and the object header may be changed in the future
Using AI agents to write MoonBit?
Use the official MoonBit Agent Skill
It is actively maintained by the MoonBit team and kept up to date with the language and toolchain, so agents can generate and modify MoonBit code with better context.
https://t.co/9JTHAMeYcY
@moonbitlang
Last year I wrote a tutorial on the type checking algorithm for System F<, and I've recently translated it into English, including a MoonBit code implementation.
Have fun with local type inference and bidirectional typing :)
https://t.co/fyKKXEPjJR
Vor genau einem Jahr habe ich einen Raspberry Zero2 W in Paraffinöl versenkt.
Das Öl sorgt dafür, dass der Prozessor auch unter Höchstlast kaum wärmer wird als Zimmertemperatur.
Seitdem berechnet er mit einem BOINC-Client für die Mathematisch-Physikalische Fakultät in Prag 24/7 Asteroidendaten.
So ermitteln wir die Umlaufbahnen aller Asteroiden und wissen, wo die ihre Bahnen ziehen und auch, ob wir uns Sorgen machen müssen, dass uns einer in Zukunft trifft.
Ein genau baugleicher Zero2 W mit genau der gleichen Software führt genau die gleiche Aufgabe ungekühlt aus.
Und jetzt stellt sich die Frage: Macht perfekte Kühlung einen Leistungsunterschied aus?
Und die Antwort ist: Ja!
Und zwar signifikant! – 5,97 %
So das wäre auch geklärt. 😀
v0.19.1 of `moonbitlang/async` now ships an optional fd leak check for async @moonbitlang programs. You can enable it with the `MOONBIT_ASYNC_CHECK_FD_LEAK=1` environment variable. Once enabled, unclosed file descriptors will be reported on program exit.