Gemma4 E2B, compressed by @TheStageAI , from 9.3GB to 1.4GB, is running on iPhone 16e with tool calls!
The smallest and the best quality checkpoints open-sourced! @GoogleDeepMind
The smallest checkpoints for Gemma 4 E2B and E4B for local inference. Results for E2B:
size: 9.3 GB → 1.4 GB
speed: 113 tok/s on Apple M3
quality: -3% on ifEval
runs with: MLX, llama.cpp (coming)
Pareto-optimal, open source! Links to the blog post and GitHub repo ⬇️
@GoogleDeepMind@lmstudio@ollama@huggingface@ggerganov
Say hello to V4.1
This model is built for images that captivate you. Photorealism is more human, gradients are dreamier, and new illustration styles are now possible.
Test it out in Recraft Studio today and see what you can create.
@HarryStebbings@antonosika AGI, $100B investment, Safe AGI, $500B investment, Very Aligned Safe AGI, $1T investment.
If AGI becomes smarter than humans, how soon will it create something even smarter than itself?
Beyoncé heard cursing. TheWhisper heard Arsenal.
The fastest Whisper in the world.
Open-source real-time ASR.
Top 5 on OpenASR benchmarks.
1800 RTFx.
Built for live captions, transcription, and voice apps.
See the repo
Self-hosted AGI starts with inference infra teams can actually run.
Well. Elastic Models v0.2.0 is much more self-serve: world’s fastest whisper-large-v3-turbo, Wan2.2 generating 5s of video in 34s on H100, and instant FLUX LoRA switching.
Explore v0.2.0
Actually, comparing 1-bit with 16-bit has no sense. Everyone is using 4-bit weights with MLX. And the speed will be around 150-180 tok/s on M4 Pro. Moreover, 4-bit quantization in MLX can be done as block quantization what preserve quality for the most cases.
1-bit Bonsai 8B running locally on an M4 Pro (MLX) alongside a standard 16-bit 8B model.
Same class of model, very different deployment profile: far lower memory use and substantially higher throughput.
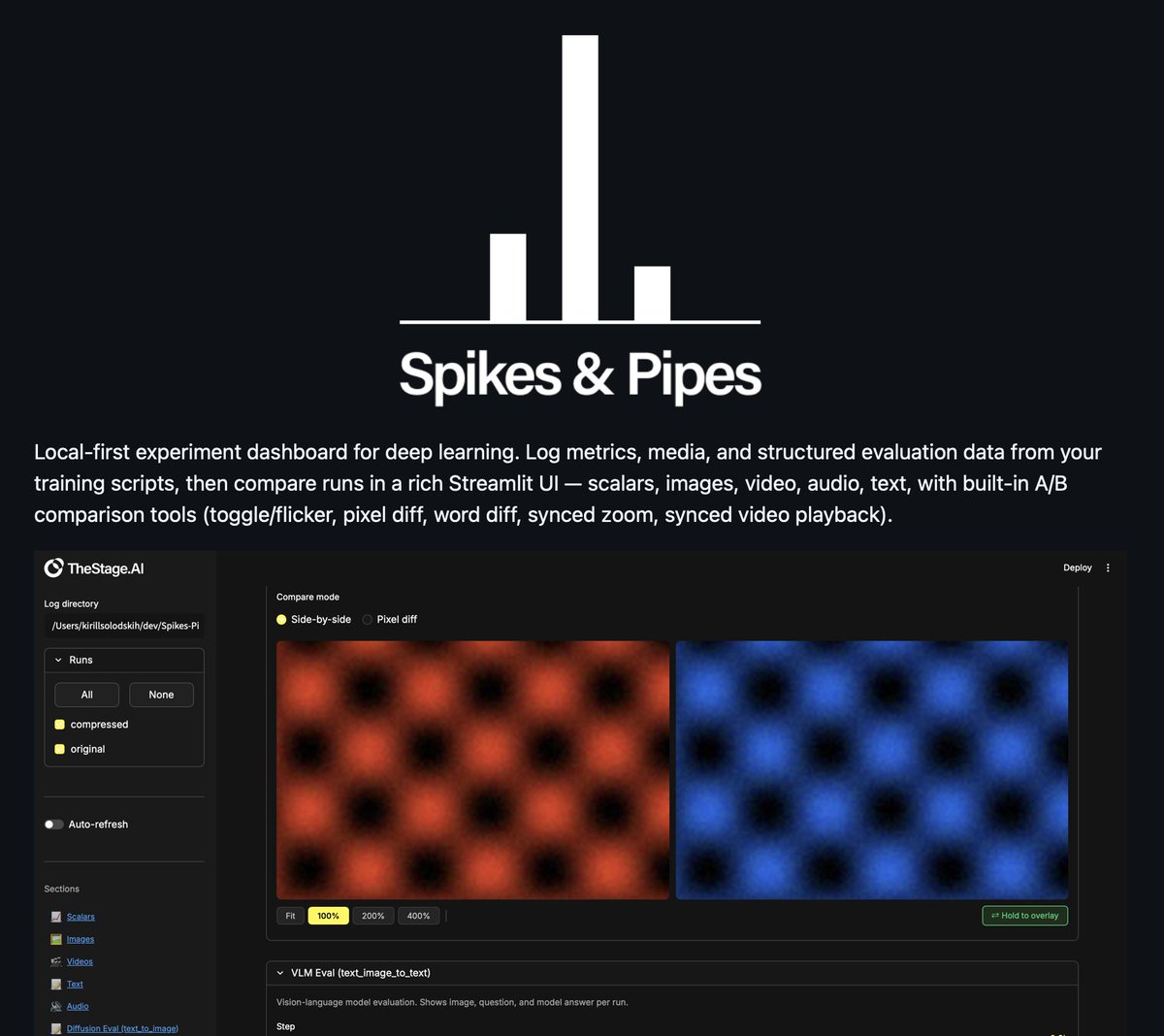
Open-source experiments dashboard for AI researchers. Cool comparison overlays across modalities. What add next? S3 integration, authentication, model registry?
https://t.co/FMJTsq21Pf