T2I systems look complex only because we keep adding components. How about removing them?
Introducing our latest work MiniT2I 🪄: purely flow matching objective on pixels, no auxiliary losses, all open-source data and academia-affordable compute. Everything is just designed so simple and minimal. ✨
me: hey can I get a 5 ultra high definition photos of 70ft tall Anne Hathaway stomping around Manhattan and crushing people under red heels?
midjourney: sure here you go
me: btw do you know where I can go to get cancer screenings?
midjourney: you’re not gonna believe this
I’m excited to share that I’ll be joining OpenAI and look forward to working with the exceptional team there.
It was a difficult decision to move on. I’m incredibly proud of the amazing team at Google and everything we’ve built together. It has been an honor and a pleasure to work with all of you.
MLX port for apple silicon is up + quantized weights as well.
Is pretty solid TTS model, probably one of the top 2-3 open-source models I’ve used.
https://t.co/B1pNp24Rc5
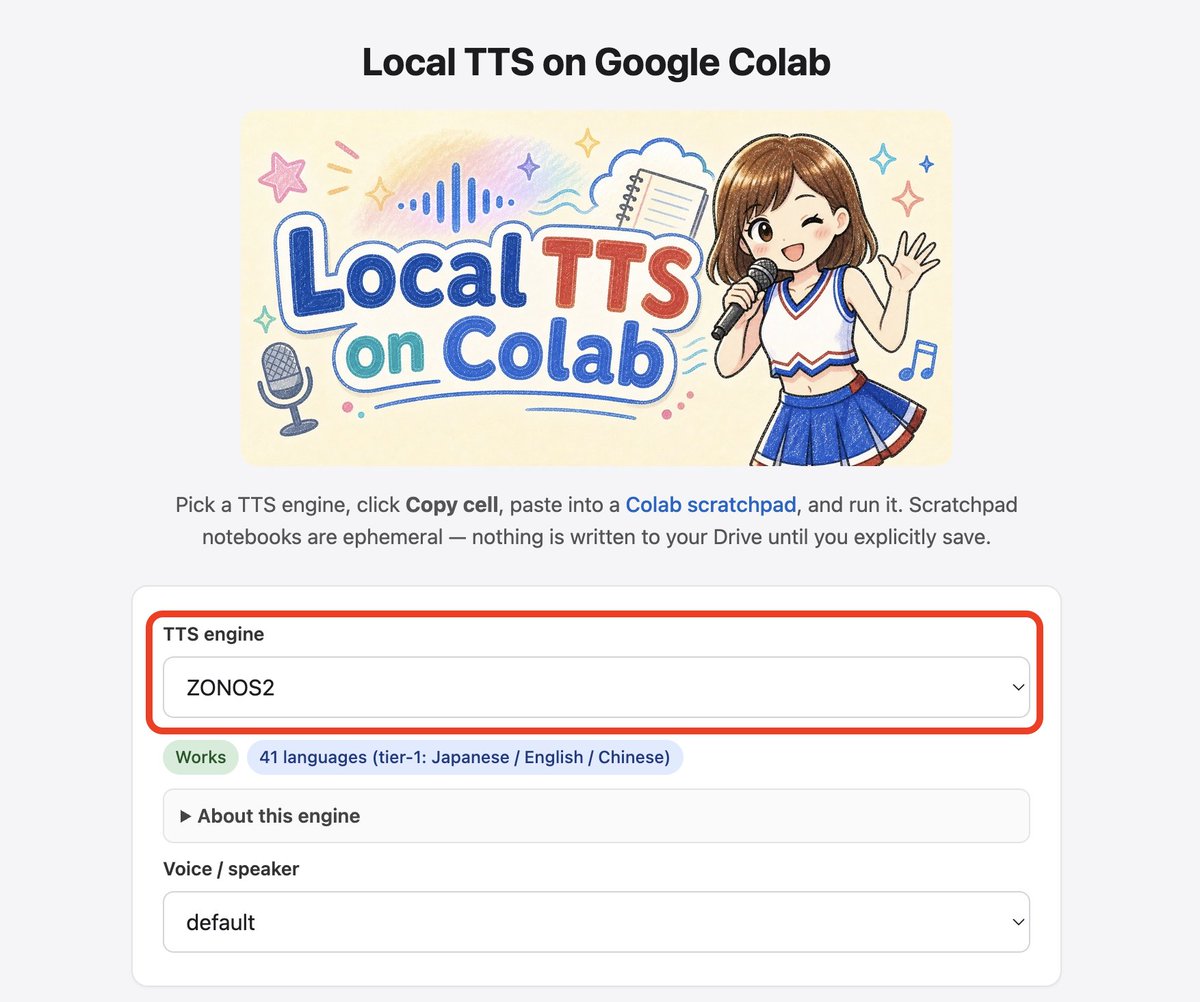
出たばかりのZONOS2、Colabで簡単に試せるようにしました!
日本語対応・Apache-2.0(商用OK)・声のクローンもいける、MoEで低遅延の新しいオープンウェイトTTS
Local TTS on Colabに追加したので、ZONOS2をセレクトボックスから選択後、生成されたコマンドを貼るだけでOpenAI互換APIとして起動して動作確認できます
新しいモデルをすぐ触れるの、やっぱり楽しい😊
https://t.co/Zgf8d0vs1q
@yugshende@ZyphraAI@AMD Going to have to agree here. The benchmarks we post are pretty narrow and talk only about naturalness in a few verticals. I have so much respect for the Gemini multimodal team they are cooking 🔥.
@IgorIlyinsky If you self host you can clone from any length of audio but on our api, which is at the bottom of the tweet thread, clone length is capped at 120 seconds.
Today we're releasing ZONOS2, our next-generation real-time TTS model with high-fidelity voice cloning.
ZONOS2 is the most expressive open-source TTS model, released under Apache 2.0 and available on Zyphra Cloud on @AMD. 🧵