#NeurIPS2025 Mixing different datasets to train your LLM?
✨ We can help you find the perfect blend!
📈 Few small-model experiments → scaling law fit → your optimal mixture.
🎯 Easy + efficient.
Chat with us 💬 Poster #3414. Thu, Dec 4, 11am
We propose new scaling laws that predict the optimal data mixture, for pretraining LLMs, native multimodal models and large vision encoders !
Only running small-scale experiments is needed, and we can then extrapolate to large-scale ones. These laws allow 1/n 🧵
#ICLR#TrainLLMBetter Tomorrow, #soup of experts, an #hypernetwork conditioned on a simple description of the test distribution: adaptation without retraining (Modularity workshop Sunday). https://t.co/Cc72NyyJpI
Still on today... CRISP Importance Sampling for LLM pretraining.
#ICLR#TrainBetterLM I am at ICLR, come to our posters for improved language model training!
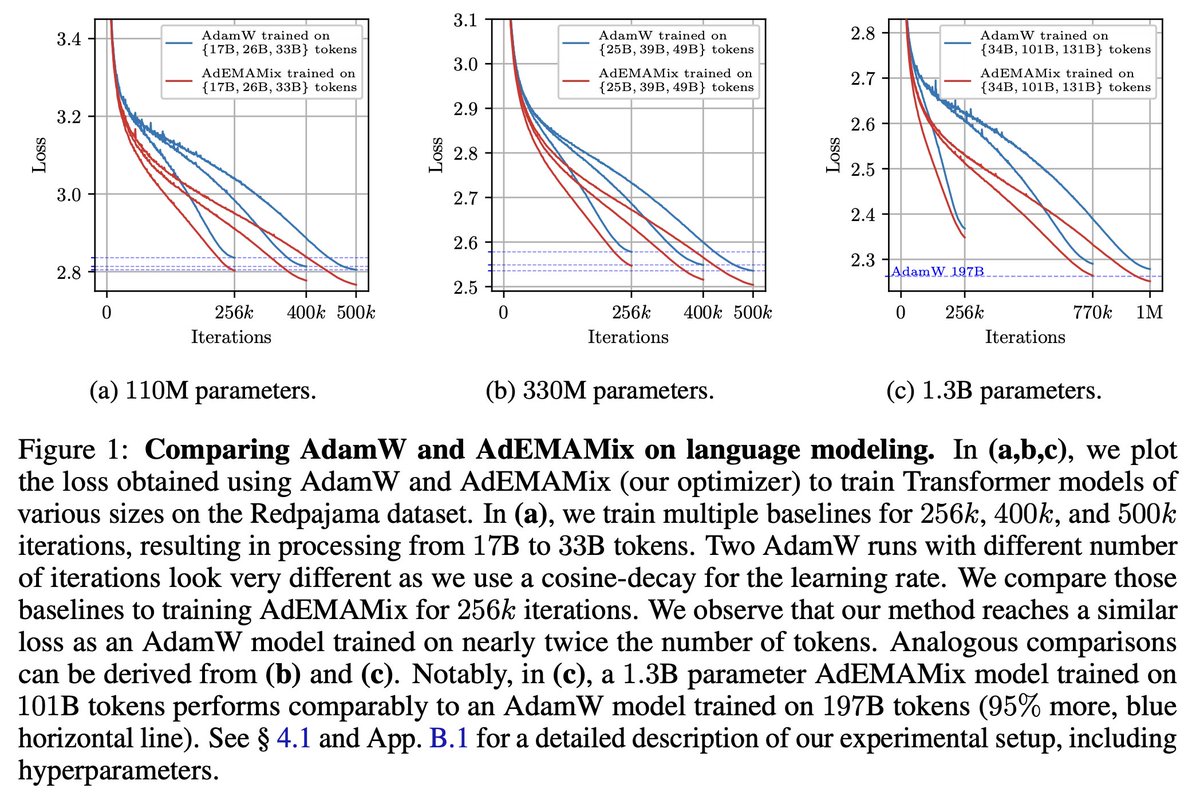
Recycle gradients for faster neural net training with AdEMAmix https://t.co/eR3r0TSRJH (Fri Apr 25, 10 am).
1/3
⦿ Efficient, scalable approach on LM and Q&A domains.
⦿ Single & multitask.
⦿ Pretraining & continued pretraining.
⦿ Ablations on data size, model size...
https://t.co/k0EMaZiQfN
4/4
New paper! https://t.co/k0EMaZiQfN
Clustered importance sampling to build specialist Language Models (LMs)
🤔 Build a specialist LM with very little specialist data
💡How? Generalist data + efficient, scalable importance sampling
w/ @Olivia61368522+SkylerSeto+@PierreAblin
1/4
🚀Easy with clustered importance sampling:
1️⃣ cluster the generalist dataset,
2️⃣ resample the clusters w/ their prior from tiny specialist data,
3️⃣ Done! 🏁
3/4
Stop discarding your old gradients! Introducing AdEMAMix, a novel (first-order) optimizer capable of outperforming Adam. Let’s have a thread on momentum and the surprising relevance of very old gradients. A joint work with @GrangierDavid and @PierreAblin#ml#optimization
1/🧵
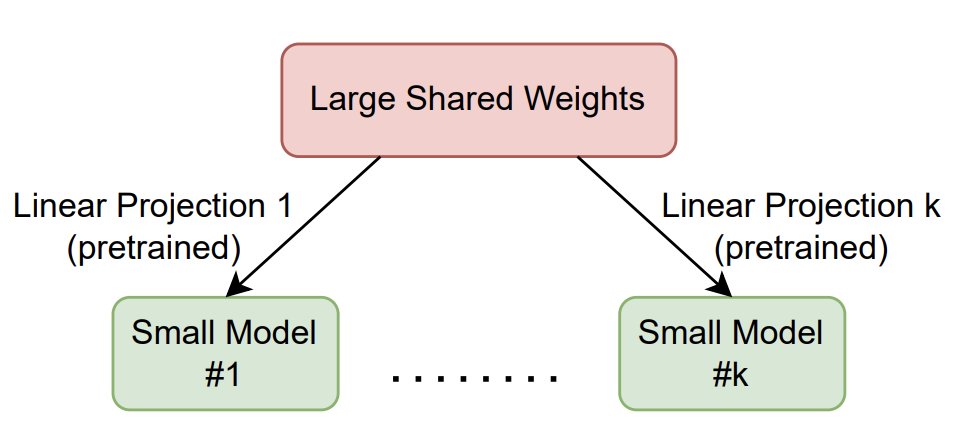
2/2 PN is a high capacity network whose parameters can be linearly projected into a small network. This strategy enables both high capacity and efficient inference. See details at our poster on Friday morning and afternoon. https://t.co/wdtXz9n3yb
https://t.co/q4v86N4Wjq
At ICML? Learn about our efficient projected language models!
Adding capacity to a traditional language model improves
accuracy but increases inference cost. How to avoid this? We propose a novel architecture, projected networks (PN).
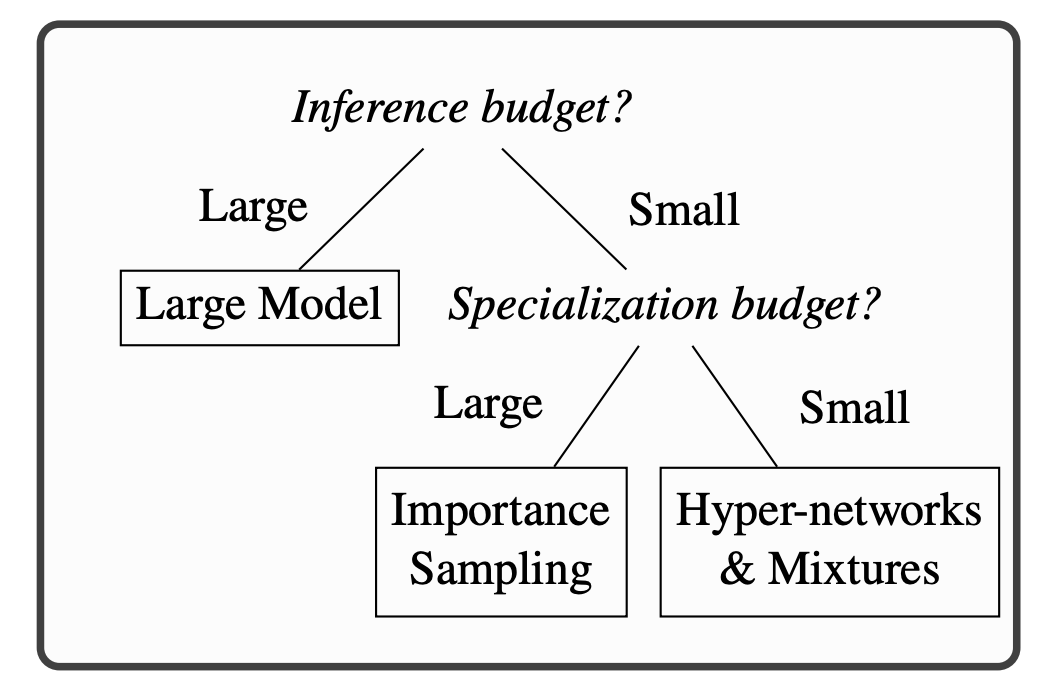
New language model work! In practice, LMs often face a double constraint (i) small inference budget + (ii) little application-specific data: (i) means small specialized models for inference; (ii) means using auxiliary generic data e.g. for pretraining 1/2 https://t.co/E7MrinEcLq
2/2 Findings: when the application-specific training budget is large, importance sampling is great. Otherwise, asymmetric models (big at train, small at inference e.g. mixture of experts or hyper-networks) are attractive, better than the popular distillation strategy.
Our analysis proposes a simple test to check if our method applies to your problem. Chat with us at our poster at #neurips2023 DistShift workshop next week. Joint work with Pierre Ablin, Awni Hannun. (3/3)
Large models are often trained on massive web datasets and a bit of target-task data. In this setup, it is 👍 to spend more train effort on specific parts of the large set. Our online algorithm maintains an auxiliary cheap filter model when training the large model. (2/3)