Our team’s opinion after the recent AI discourse is pretty simple: frontier AI is moving fast, but no one should use a scaling curve to dictate the research pace for everyone else.
Given the state of machine learning as a whole, no one has a license to act like the core problems behind AGI, RSI, or ASI are close to solved.
The more sober view, in our opinion, is that we are moving out of a pure scaling era and back into a research era as Sutskever or Le Cun say. Scaling gave the field a lot. No serious person should dismiss that, and no one serious should be saying “stop scaling” or “stop frontier research.” But current systems still fall short in ways that matter: they can be brittle, they struggle under distribution shift, they do not learn continuously the way humans do, and they still lack the kind of grounded, reusable understanding that transfers reliably across very different contexts.
This is why no one should be dictating the pace of research as if the hard part is already behind us. There is still a massive amount of research left to do.
Sutskever’s “finite data” point is important because it cuts deeper than just “we need more data.” It points to the limits of relying on internet-scale pre-training as the main engine of progress. At some point, the question becomes how systems generalize, how they learn efficiently from limited signals, and whether the learning mechanisms themselves are enough.
The original “world model” crowd (May the meaning of this terminology rest in peace alongside “memory”) says that it’s not just that LLMs have flaws but that intelligence requires machinery for world models, grounding, memory, planning, and prediction in latent space. A system can be very good at modeling language while still missing the structures needed to understand and act in the world.
If clean data, feedback, and training signals were effectively unlimited, distillation and model-extraction attacks would not be such a major strategic concern. The fact that frontier capability itself becomes something others try to copy is a reminder that learned competence is scarce. It also suggests that the main mechanisms LLMs currently rely on to improve may be far from sufficient to reach super-intelligence or efficient learning.
These opinions are more AI-friendly than anything. Looking forward to progress across many areas, while giving the big labs real credit for what they have achieved in language, code is far more positive for the field than pretending we are already close to AGI or ASI when we clearly are not there yet.
And while we are not there yet, the large influx of serious STEM talent into AI is unbelievably good for the industry. Researchers from across math, physics, biology, engineering, and the rest of science are increasingly taking AI seriously, building with it, testing it, and bringing their own standards into the field. That should be celebrated as it means AI is attracting the kind of people needed to solve the rest of the problems.
Domains that are not compatible with prose strengthen the main point. A model can be excellent at language, code, and digital workflows while still being far from robust general intelligence. Physical prediction, causality, affordances, action-conditioned planning, and reasoning across long time horizons are still hard problems.
So yes, today’s models may reshape coding, security, science workflows, and other areas. That is very real indeed but it does not mean we already have the a perfect recipe for autonomy, alignment, continual learning, causal understanding, grounded world models, or reliable long-horizon reasoning.
The public conversation would be much healthier if it could hold both ideas at once: frontier models are good while there is still a lot left to do on all angles.
It’s hard to disagree with the direction of this. But it’s worth being honest that the neuro-symbolic lineage lost to scale for most of the last decade.
At the surface, everything collapses into prose. Fluent text is a poor record of what produced it. Two systems doing completely different work underneath can return the same paragraph. Whether anything symbolic is happening has to be answered below the language layer and not in the prose.
LLMs are excellent at prose, and they’ll remain relevant in that era. But prose is not the thing to lean on once a task needs real adaptation, verification, planning, or abstraction.
The lineage has been kept alive in places with DeepMind’s theorem-proving work among them and it’s finally starting to look right again.
Core 0.5a - Patch Notes
0.5a, opening update of the 0.5 series, is now live on Rei Chat as well as our agentic API. Creating new units is advised as it is the only way for 0.5a to take full effect.
PATCH NOTES
0.5a's main focus area is how units learn. faster intake, better retention, and more from every interaction. every change in this update touches some part of how a unit processes what it's given, how it holds onto what matters, and how it builds on what it already knows.
Expect brief interruptions over the next 72h as we complete migration and roll out minor updates.
Unit-Level Evolution
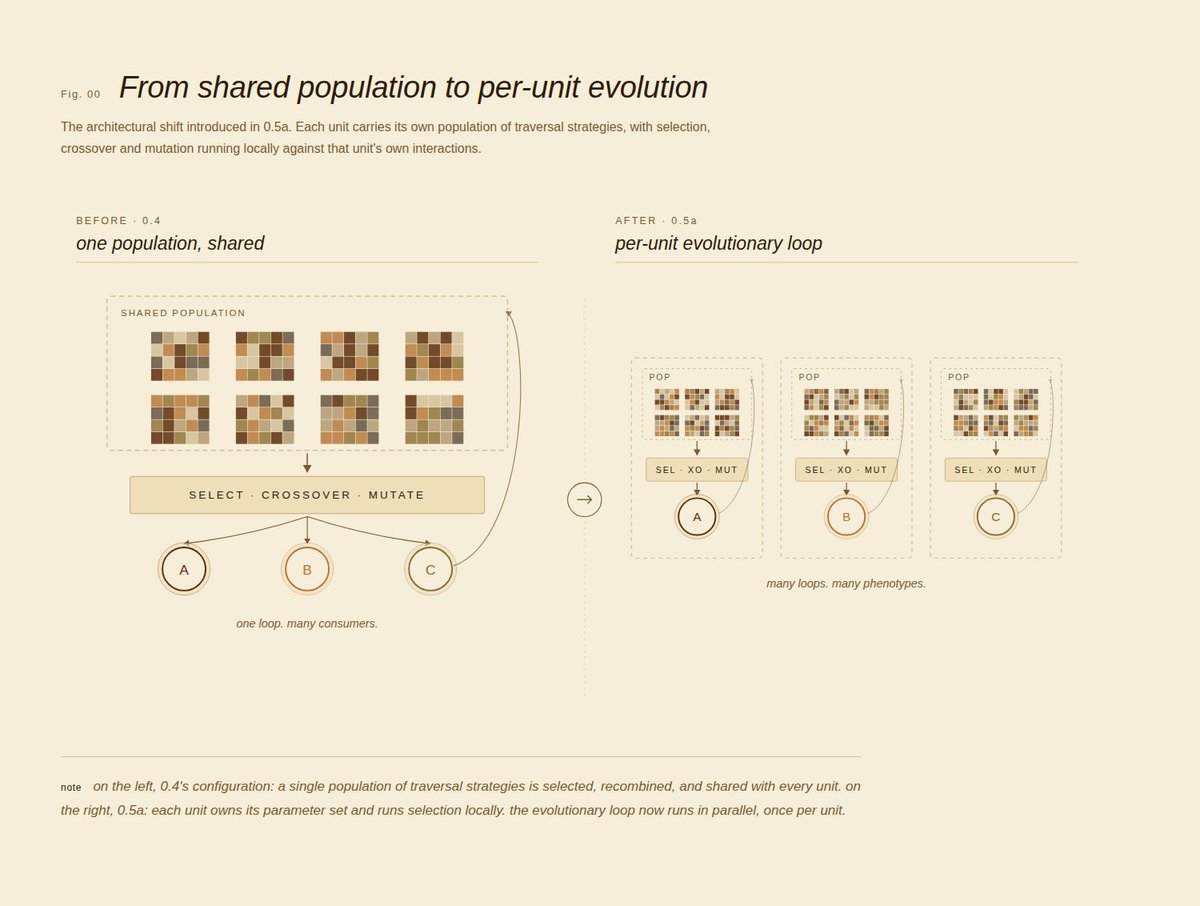
• Evolution moved from system level to unit level
Genetic algorithm evolution has moved from system level to unit level. Previously, evolutionary pressure operated globally, with competing inference strategies evolving as a shared population. In 0.5a, the specimens at the basis of evolution are defined by each unit's own relationship and concept exploration parameters. Selection, mutation, and crossover now run against how individual units traverse their hypergraphs, form patterns, and abstract concepts.
Two units starting from the same configuration will develop increasingly distinct reasoning behaviors over time, not just because their knowledge differs, but because the parameters governing how they discover and reinforce that knowledge are themselves evolving independently.
Resilient Hybrid Recall
• Semantic recall combined with hypergraph-aware retrieval
• Faster access to relevant knowledge with better structural context + hypertags
• Better recovery of entities, relationships, and concepts
Core 0.5a introduces a unified recall layer that combines semantic similarity with hypergraph structure. Knowledge that has faded from direct semantic reach can still be surfaced through relationship paths, entity linkage, and hypertags. This gives the system structural redundancy in recall without fighting the decay mechanism. Knowledge is still allowed to fade as designed, but the paths to reach it are no longer dependent on a single retrieval method. Recall has improved significantly as a result.
Asynchronous Hypergraph Enrichment
• Immediate knowledge availability on write
• Background extraction of entities and relationships
• Richer knowledge structure without adding interaction latency
New knowledge is available immediately, while deeper entity and relationship extraction happens in the background. This keeps writes fast while still allowing knowledge structure to become more detailed over time.
Modular Core Services
• Clearer separation between knowledge, recall, traversal, exploration and routing
• More defined internal service boundaries
• Modular framework for future updates
0.5a moves Core toward a more modular structure, with dedicated layers handling different parts of the system. This improves maintainability, reduces fragility, and makes the platform easier to extend.
Adaptive Context Processing
• Condensation of long-form content before deeper extraction
• Better retention of important details during heavier workloads
• More efficient handling of large or dense inputs
Longer inputs are no longer processed as-is. Core condenses dense content before deeper extraction, preserving key facts and relationships while reducing noise. This keeps recall efficient under heavier workloads and prevents important details from being diluted by volume.
Knowledge Persistence
• Better handling of entities, relations, and knowledge linkage
• More stable hypergraph interpretation in live operation
• Cleaner storage and integration of new facts into existing structure
Where Resilient Hybrid Recall addresses how knowledge is found, this addresses how it's stored and linked. Core now handles entity formation, relation mapping, and structural integration with more consistency, which gives the recall layer stronger material to work with in the first place.
Stronger Runtime Reliability
• Cleaner local-first service behavior
• More predictable execution paths
• Better stability during live end-to-end use
A major part of 0.5a is reliability. Service behavior is more predictable, local execution is cleaner, and the system is more stable under real usage.
System Maturity
• End-to-end validation of store, list, query, and clear flows
• Verified delayed enrichment behavior under live conditions
•Greater confidence in recall quality outside isolated tests
0.5a's notes is the last set of release notes in this format. as closed beta wraps up, so does this style of patch notes, making way for a different format that better fits what comes next. to everyone who's been part of closed beta, thank you.
Disclaimer: 0.5a is exclusively accessible via Rei Chat and our agentic API. Rei Chat/Rei Chat API are user-friendly, OpenAI compliant interfaces for interacting with parts of our architecture. units start as blank slates and are designed to become domain experts through training. they are learning systems, mistakes are possible and normal, the user's role is to train their unit at inference.
Bias engineering and bias avoidance are both direct results of how a Unit is trained and evidence of structured learning working as intended in the current build (0.4). Whether to correct for bias or lean into it deliberately is a training decision.
Individual training is uncharted territory, especially for markets. Every user who trains a Unit brings a different framework for when to intervene, what to reinforce, what to let drift. Two users starting from the same template will end up with different outcomes.
This breakdown is a useful starting reference for training trading Units, but we don't expect optimal methods to exist yet. The more people who train on Core, the more likely someone finds approaches no one has considered. The design space is too large for any single team to explore.
0.4 is already behind its successors and we haven't used it in a while, but it means a lot to us to see people training Units on it and trusting them with real capital.
Thank you to all of our iOS TestFlight users over the past few months. Your feedback across 10k sessions and 21 builds has been incredibly valuable.
TestFlight access will end soon and may be removed without further notice.
We’re making a set of incremental updates to Rei API and Rei Chat over the next few days. Some of this work touches core request handling, so there may be brief periods of intermittent availability as changes roll out.
Once complete, these updates should reduce latency on general queries, cut down on edge-case failures, and improve API stability under load.
As we roll out our release schedule, Phase 1 of transitioning out of closed beta is now underway. Thank you to our beta users for your feedback and support.
Expect almost daily maintenance in production including Sandbox during this phase.
A brief overview below ↓
There's growing momentum around "data poisoning", deliberately corrupting the datasets that models learn from. The logic is straightforward: intelligence lives in the weights, so corrupt the weights, corrupt the intelligence. The model absorbs everything indiscriminately, unable to distinguish signal from sabotage, and reproduces the corruption indefinitely. The attack surface is the entire internet.
This vulnerability exists because current AI is fundamentally regurgitation at scale. Trillions of tokens compressed into statistical pattern matching. The model never "understands”, it memorizes and interpolates. There's no deeper cognitive process to catch this type of corruption.
Core is architecturally resistant on two fronts.
Units are blank slates. They carry no pre-baked knowledge scraped indiscriminately from the web. Intelligence emerges through reasoning over data inferred directly from you, your context, your inputs, your domain. The poisoned well everyone drinks from simply isn't part of the architecture. You bring your own water.
Core's center is an inference engine, not a knowledge repository. What evolves are strategies, reasoning methods, approaches to connecting ideas. Successful patterns survive and propagate. Failed patterns are eliminated. Selection pressure operates continuously. A dataset can be poisoned because it's static, it sits there, inert, trusted by default. A strategy can't be poisoned the same way because it's subject to ongoing evolutionary pressure. Bad reasoning paths lose. They don't reproduce.
More on NeuroEvo Below
Weekend Update:
Unit Usage Guide Volume 1 released
Updated for Core 0.4 and its mental model
Volumes 2 & 3 scheduled for Q1
https://t.co/5Np8z9d6HY