I am a big fan of Jianlin Su's blog because it always starts from first principles in mathematics, rather than "ML tricks", to approach a typical ML problem (eg. training-free MoE load balancing).
Here is me trying to "reinvent" one such blog which provides an elegant alternative to compute Muon, by filling in all the derivations that the blog skips for a less math-savvy audience (besides being entirely in Mandarin).
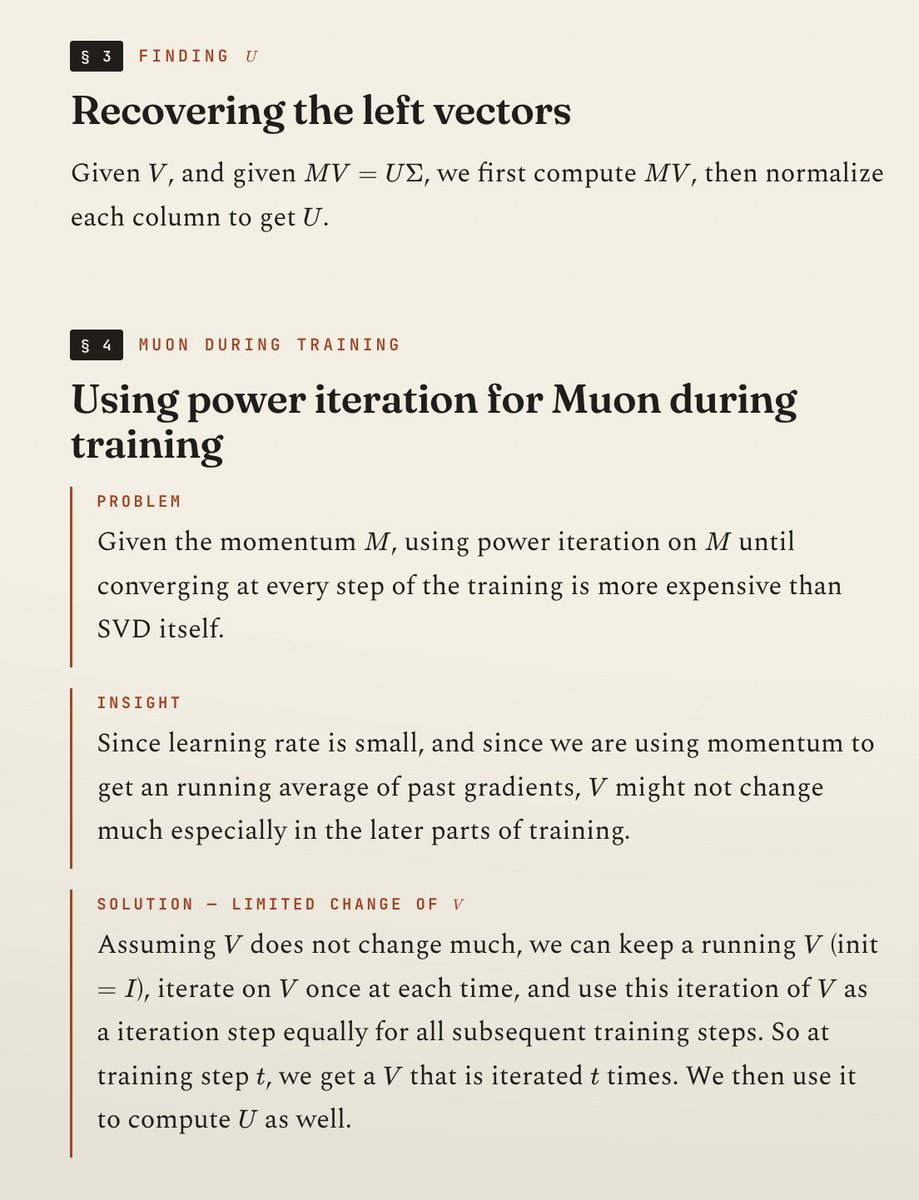
The goal of the blog is to find a way to compute a essential component of Muon, ie. the left and right singular value matrices U and V for the gradient G, **individually**. In the standard form, Muon really just needs their product UV^T, hence the standard way to compute it via computing a low-rank polynomial of G many times ("Newton-Schulz"). But there are more variants of Muon to control the properties of model updates if we can get both individually, hence the blog's proposal to revisit some fundamental linear algebra techniques for the computation.
The methodological takeaway from the blog's thought process is that there are three components to breaking down a ML problem: (1) how to be able to compute something (power iteration), (2) how to compute it fast (cholesky decomposition), and (3) how to compute it accurately given finite floating points (repeated orthogonalization). The goal of reading inspiring blogs like this is, in Feynman's term, to be able to "reinvent" them at any time to grasp the fundamental approach of doing similar work.
Original blog: https://t.co/5ksKPICpMW
لأول مرة🤩!!
يجتمع شغف طب الأسرة مع الخبرة العملية في لقاء تفاعلي مميز يسر مجتمع طب الأسرة ونادي المهتمين بطب الأسرة وVistaMed في تقديم ورشة مميزة مع د. سارة البكري:
🌟The Remarkable Family Physician
خطوة أقرب لتفكير سريري أعمق، تواصل أفضل، وعيادة أكثر كفاءة.
المقاعد محدودة‼️
المملكة تنشئ أكبر مركز بيانات حكومي في العالم مصنف Tier IV كأعلى تصنيف، تحقيقاً لتطلعات سمو ولي العهد – حفظه الله – في بناء اقتصاد وطني قائم على البيانات والذكاء الاصطناعي ضمن إطار تحقيق مستهدفات #رؤية_السعودية_2030#مركز_هيكساجون#سدايا
UC Berkeley offers two free courses on LLM agents, one at the foundational level and one at the advanced level, taught by leading researchers and practitioners from DeepMind, Meta, and top universities.
Together, they cover essentially everything you need to understand and build agents, drawing from some of the best resources available today.
I have created this illustration to help you visualize the Docker Workflow 👇
Let's understand the terms using analogy -
👉 Dockerfile
- Think of a Dockerfile as a recipe or a set of instructions.
You start by creating a Dockerfile that lists all the ingredients (software and configurations) needed for your application.
👉 Docker Image
- Using the Dockerfile as your recipe, you "cook" or "build" a Docker Image.
This image is like a frozen snapshot of your application, containing everything it needs to run.
👉 Docker Container
- Once you have your Docker Image, you can "serve" it by creating a Docker Container.
The container is like a real, running instance of your application, and it can be started, stopped, and even duplicated as needed.
You can run any number of containers from an Image.
Follow @techNmak for regular insights.
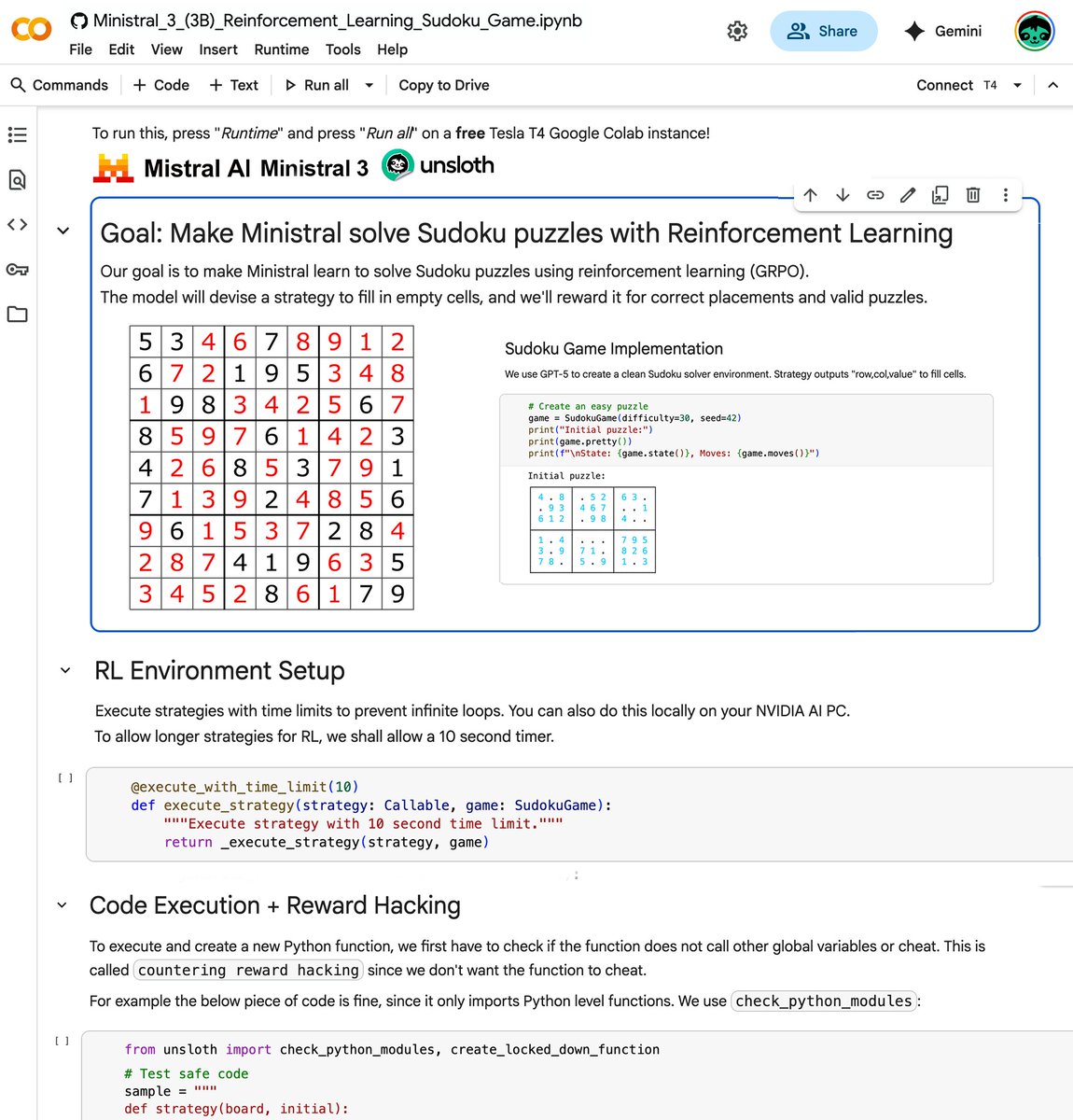
You can now train Mistral Ministral 3 with reinforcement learning in our free notebook!
You'll GRPO the model to solve sudoku autonomously.
Learn about our new reward functions, RL environment & reward hacking.
Blog: https://t.co/SLIamT6Dx7
Notebook: https://t.co/oj0lZ0fIhx
يسعدنا إطلاق سلسلة ورش AI Peers وهي سلسلة ورش تطبيقية تُقدَّم من الطالبات المتخصصات في الذكاء الاصطناعي، وتهدف إلى تعزيز تبادل المعرفة والخبرة في مجالات الذكاء الاصطناعي.
تستهل السلسلة أولى ورشها بعنوان "Advanced AI Concepts and Applications"
للتسجيل:
https://t.co/V7ocj3Wm03