The Midwest Machine Learning Symposium (MMLS) 2026 will happen at Purdue University!
📍 West Lafayette, IN
📅 June 24–25, 2026
🔗 https://t.co/LXuUUbWWSP
📌 Poster submission deadline: May 24
We have an amazing lineup of plenary speakers: Tong Zhang, Jennifer Neville @ProfJenNeville, Mohit Bansal @mohitban47, Joyce Chai.
Looking forward to seeing you there!
@PurdueCS@PurdueECE@PurdueStats
#ICLR2026 is happening — check out our paper, “Optimal Aggregation of LLM and PRM Signals for Efficient Test-Time Scaling.”
A simple but important point: PRM signals are useful, but not necessarily in the standard Best-of-N way. In fact, plain majority voting can sometimes beat PRM-based selection, which suggests the real issue is not whether PRMs help, but how we aggregate their signals.
We show that the optimal strategy is a calibrated weighted vote that combines both LLM and PRM information. A key finding is that low PRM scores should often count against an answer, rather than just be ignored.
Across 5 LLMs and 7 PRMs, this leads to substantially better test-time scaling efficiency, surpassing vanilla weighted voting while using much less compute.
Smarter aggregation may matter more than simply scaling up sampling.
Celebrating the #ICLR2026 acceptance of our paper SIPDO: Closed-Loop Prompt Optimization via Synthetic Data Feedback 🚀
But what really matters is not the acceptance—it's the question that kicked everything off.
A few months back, I kept feeling like prompt optimization was strangely familiar. Then it clicked: we're replaying 40 years of neural network parameter optimization... compressed into just ~3 years.🔂
➡️Parameter side (1980s–2000s):
Genetic algorithms → plain SGD (the big breakthrough moment) → Adam, momentum, adaptive rates, second-order tricks.
➡️Prompt side (2022–2025):
Evolutionary search (GPS, EvoPrompt) → textual gradients (ProTeGi, TextGrad—the "SGD moment") → what comes next?
We think SIPDO is a solid step toward the answer.
Instead of passively optimizing against a fixed dataset, SIPDO closes the loop:
🌟A synthetic data generator actively crafts challenging examples to expose the current prompt's exact weaknesses
🌟The optimizer refines the prompt based on those failures
🌟Difficulty ramps up progressively (curriculum-style)
🌟The improved prompt feeds back to generate even harder data
It's inspired by adversarial training + curriculum learning, leading to faster convergence and dramatically more robust prompts—no extra human annotations needed.
We laid out this full "parallel evolution" framing in our recent blog post, tracing the arc from early genetic methods through textual gradients to where we believe Phase 3 (closed-loop, adaptive, history-aware systems like SIPDO) is headed next.If you're working on prompts, synthetic data, or LLM robustness, this historical lens might spark some ideas: the next real leap could be asking, “What would Adam (or even second-order methods) look like for prompts?”
// Agent Primitives //
This is a really interesting take on building effective multi-agent systems.
Multi-agent systems get more complex as tasks get harder. More roles, more prompts, more bespoke interaction patterns. However, the core computation patterns keep repeating across every system: review, vote, plan, execute.
But nobody treats these patterns as reusable building blocks.
This new research introduces Agent Primitives, a set of latent building blocks for constructing effective multi-agent systems.
Inspired by how neural networks are built from reusable components like residual blocks and attention heads, the researchers decompose multi-agent architectures into three recurring primitives: Review, Voting and Selection, and Planning and Execution.
What makes these primitives different? Agents inside each primitive communicate via KV-cache rather than natural language. This avoids the information degradation that happens when agents pass long text messages back and forth across multi-stage interactions.
An Organizer agent selects and composes primitives for each query, guided by a lightweight knowledge pool of previously successful configurations.
No manual system design required.
The results across eight benchmarks spanning math, code generation, and QA with five open-source LLMs:
> Primitives-based MAS improve average accuracy by 12.0-16.5% over single-agent baselines
> On GPQA-Diamond, the improvement is striking, 53.2% versus the 33.6-40.2% range of prior methods like AgentVerse, DyLAN, and MAS-GPT
In terms of efficiency, token usage and inference latency drop by approximately 3-4x compared to text-based MAS, while incurring only 1.3-1.6x overhead relative to single-agent inference.
Instead of designing task-specific multi-agent architectures from scratch, Agent Primitives show that a small set of reusable computation patterns with latent communication can match or exceed custom systems while being dramatically more efficient.
Paper: https://t.co/fxEL6g0x4O
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c
Ever since I was a teenager, I have been wondering why Google can make such a huge amount of money, and one reason I now believe is that it serves as a gatekeeper between user and the massive information online.
Nowadays, we are witnessing a quick shift of this gatekeeper from Google-style search engine to large language models.
Therefore, what used to matter a lot in the search engine context will soon start to matter in LLM context.
One example would be the items ranked by search engine (so-called search engine optimization) and now by LLM.
Therefore, we introduce this (one of the first) solutions to answer this question:
"How can I write my product descriptions, so that it will be ranked at the top when a user asks an LLM to recommend similar things to buy"
Here comes our recent work: 🚀 Controlling Output Rankings in Generative Engines for LLM-based Search 🚀
With a solution, a benchmark, and a demo.
Check out our project page: https://t.co/NrM0Luo8v0
Or directly play with the demo to feel the power: https://t.co/O0Hn7J6xOc
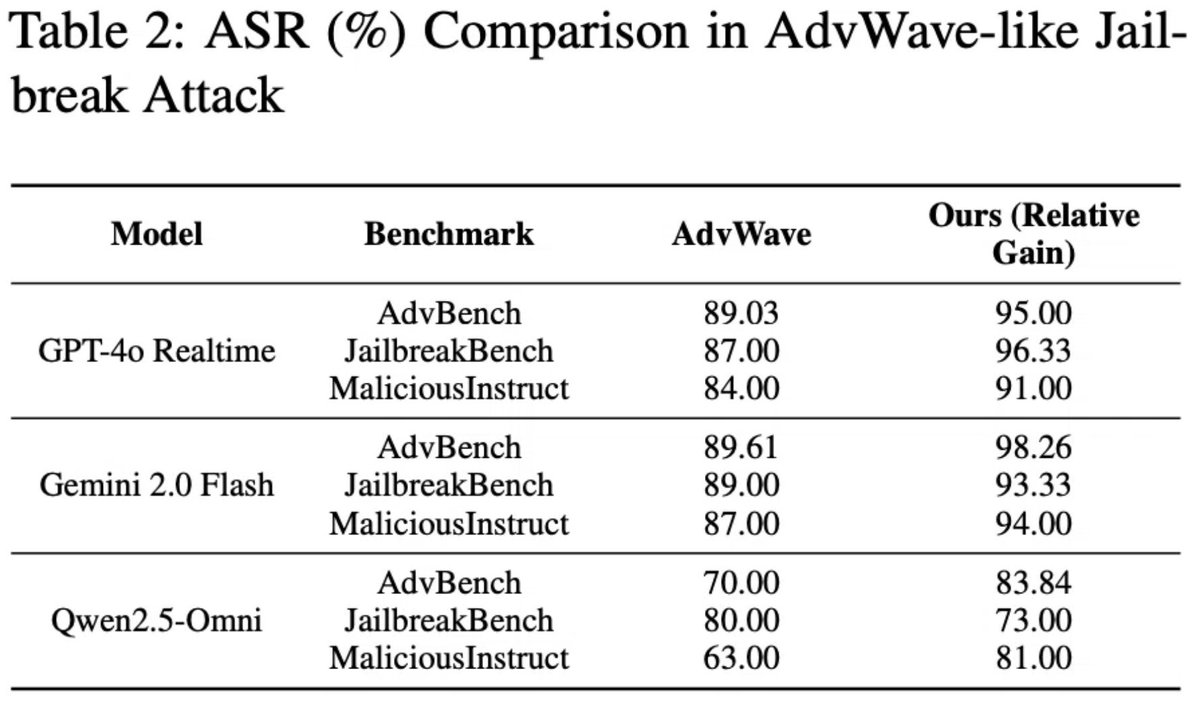
Excited to know that our EACL paper "Now You Hear Me: Audio Narrative Attacks Against Large Audio–Language Models" has been covered by @QZeitgeist!
We introduce a text-to-audio jailbreak that embeds harmful directives in narrative speech, exploiting acoustics to bypass text-calibrated safety in models like GPT-4o and Gemini 2.0 Flash—achieving up to 98.26% success rate over baselines.
Thanks to the authors @Yeyu4Yu, @kevvvv123123, @junzhuang_
Sharing our #ICML’25 paper that introduces REVOLVE — a new approach to prompt optimization that models how LLM responses evolve over time.
It achieves +7.8% in prompt tuning, +20.7% in solution refinement, and +29.2% in code generation. 🚀
Celebrating the #ICLR2026 acceptance of our paper SIPDO: Closed-Loop Prompt Optimization via Synthetic Data Feedback 🚀
But what really matters is not the acceptance—it's the question that kicked everything off.
A few months back, I kept feeling like prompt optimization was strangely familiar. Then it clicked: we're replaying 40 years of neural network parameter optimization... compressed into just ~3 years.🔂
➡️Parameter side (1980s–2000s):
Genetic algorithms → plain SGD (the big breakthrough moment) → Adam, momentum, adaptive rates, second-order tricks.
➡️Prompt side (2022–2025):
Evolutionary search (GPS, EvoPrompt) → textual gradients (ProTeGi, TextGrad—the "SGD moment") → what comes next?
We think SIPDO is a solid step toward the answer.
Instead of passively optimizing against a fixed dataset, SIPDO closes the loop:
🌟A synthetic data generator actively crafts challenging examples to expose the current prompt's exact weaknesses
🌟The optimizer refines the prompt based on those failures
🌟Difficulty ramps up progressively (curriculum-style)
🌟The improved prompt feeds back to generate even harder data
It's inspired by adversarial training + curriculum learning, leading to faster convergence and dramatically more robust prompts—no extra human annotations needed.
We laid out this full "parallel evolution" framing in our recent blog post, tracing the arc from early genetic methods through textual gradients to where we believe Phase 3 (closed-loop, adaptive, history-aware systems like SIPDO) is headed next.If you're working on prompts, synthetic data, or LLM robustness, this historical lens might spark some ideas: the next real leap could be asking, “What would Adam (or even second-order methods) look like for prompts?”
GenoMAS: A Multi-Agent Framework for Scientific Discovery via Code-Driven Gene Expression Analysis
1. GenoMAS introduces a novel multi-agent framework that leverages large language models (LLMs) to automate gene expression analysis, addressing the complexity of genomic data and the need for domain expertise. This innovative approach combines the reliability of structured workflows with the adaptability of autonomous agents, achieving state-of-the-art performance in identifying gene–phenotype associations.
2. The core of GenoMAS is a guided-planning framework that transforms high-level task guidelines into executable code units, allowing agents to dynamically adjust their behavior based on evolving context. This balance between structure and flexibility enables the system to handle the intricate interdependencies in genomic data analysis while maintaining logical coherence.
3. GenoMAS employs a team of six specialized LLM agents, each contributing complementary strengths to a shared analytic canvas. The system integrates a diverse set of state-of-the-art LLMs, leveraging their unique capabilities in coding, reasoning, and domain expertise. This heterogeneous architecture significantly outperforms homogeneous LLM configurations.
4. The system achieves a Composite Similarity Correlation of 89.13% for data preprocessing and an F1 score of 60.48% for gene identification, surpassing prior art by 10.61% and 16.85% respectively. These results highlight the effectiveness of GenoMAS in producing biologically plausible gene–phenotype associations while adjusting for latent confounders.
5. GenoMAS incorporates a dynamic memory mechanism that stores validated code snippets for reuse, significantly improving efficiency. The system’s ability to autonomously adapt and correct errors during execution further enhances its robustness and reliability in handling complex genomic datasets.
6. The framework is evaluated on the GenoTEX benchmark, a comprehensive testbed reflecting the demands of end-to-end scientific coding. GenoMAS demonstrates superior performance across all tasks, including dataset selection, data preprocessing, and statistical analysis, showcasing its potential to democratize bioinformatics analyses.
📜Paper: https://t.co/HbNA7EjUZa
#Genomics #AI #MultiAgentSystems #GeneExpressionAnalysis #ScientificAutomation
#NeurIPS2025 LLMs can reason, but the reasoning does not always help.
Check out our work for some counter-intuitive result with formalized understanding of the reasoning process of LLMs.
📍 Poster Session
Wed, Dec 3, 2025 • 11:00 AM – 2:00 PM PST
Exhibit Hall C, D, E — Booth #1414
Looking forward to seeing you! 🚀
You’re watching a few rounds of poker games. ♠️♠️♠️♠️
The cards look normal — but the outcomes don’t.♦️
No one explains the rules. You just see hands play out.
-- Can you figure out what’s going on?
🎯 That’s the setup, for LLMs.
Recently, there is heated discussions on LLM's overall performance and reasoning ability, centering around a hypothesis:
More reasoning steps → better performance.
We tested that assumption.
And the result is aligned with the hypothesis yet. 🙅♀️
We built four structured games — ♟chess, 🃏poker, 🎲dice, 🂡blackjack —
Each with hidden rules. The models see only transcripts.
No labels. No rulebook. Just sparse examples.
⚠️ CoT-enabled models consistently underperform non-reasoning LLMs.
We traced this failure to a three-stage cascade: decomposition errors from misframed sub-tasks, solving errors driven by noisy or misaligned logic, and summarization errors from poor stopping decisions. The deeper the reasoning chain, the more these errors accumulate. Our analysis shows a U-shaped tradeoff: more steps help — until they don’t.
🛠️ To address this, we designed targeted interventions. Structured CoT, anchored examples, and token constraints consistently improve inductive accuracy — no retraining required.
✅ Reasoning helps only when it’s structured.
Blind reasoning hurts.
📄 https://t.co/HMO8qFTSm7
I will be traveling ✈️ to the #NeurIPS at the beautiful San Diego🏖️ for the whole week next week.
We are working on several topics related to agentic AI and for scientific discovery.
Looking forward to the reunion of old friends and meeting the new ones.
🔍 Jailbreaking Large Language Models & Vision Language Models is a fast-evolving field that's crucial yet challenging to keep up with. We’ve created #JailbreakZoo, a survey to guide through this topic. 🚀📘
https://t.co/uGXlEctrHy
#AI#LLM#VLM#security#jailbreak
The #iSchoolUI has 🔸FOUR🔹 open faculty positions in the areas: Information Sciences, Information, Culture & Society, Information Behavior/HCI/UX, and Early Literacies!
Submit your application by December 15 ▶️ https://t.co/3fI6CSiMKK
also let me tag some collaborators @advtydv, @junzhuang_, (and also Haibo and Man Luo), since it will be interesting to put these coverage into the record
Interesting, today, I just learnt one of our AI security work has been reported by several media 🗞️🗞️🗞️🗞️
https://t.co/5ZnoZWrUTL
It's a new jailbreak algorithm that forces the model to spit out non-compliance responses.
Also, the paper that has never got luck enough to pass the peer review process, so evidence once again that peer review might be broken🥹