Frontier models are powerful advisors.
On @harvey's Legal Agent Benchmark, a GLM 5.1 worker using Claude Opus 4.7 as a sparse advisor reached 18/100 all-pass versus 14/100 for Opus alone, at 39% of the cost.
More on the harness design, advisor pattern, and training results: https://t.co/ozxFycdzcT
We partnered with @FireworksAI_HQ to train open-source models for legal. Here's what we found:
1) Hybrid legal agents can beat frontier models on quality and cost by routing selectively to a frontier advisor.
We tested a hybrid setup where GLM 5.1 served as the primary worker, routing tasks to Opus 4.7 as an advisor when needed.
GLM invoked Opus sparingly, just 0.83 times per task on average.
The hybrid setup beat Opus on both quality and cost: 18% all-pass vs 14%, at $368 vs $954 across the same 100 tasks.
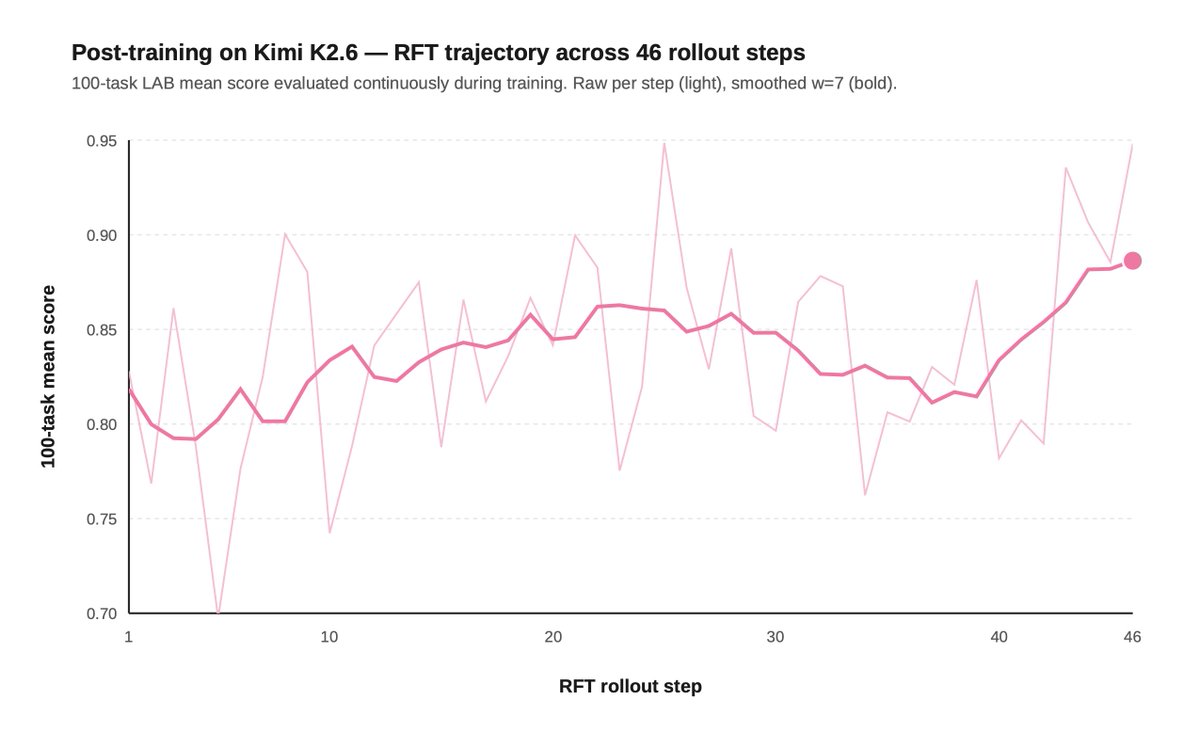
2) Post-training can push open models to frontier-level legal performance.
On a 100-task slice of our Legal Agent Benchmark (LAB), SFT moved Kimi 2.6's all-pass rate from 11% to 15%, beating Opus' 14%.
But the cost gap was even more striking: $84 vs $954 across the same 100 tasks, or ~11x cheaper.
We're excited to continue working with @FireworksAI_HQ on the next generation of open-source legal agents.
Can we design legal agent verifiers that are up to 1,000x cheaper?
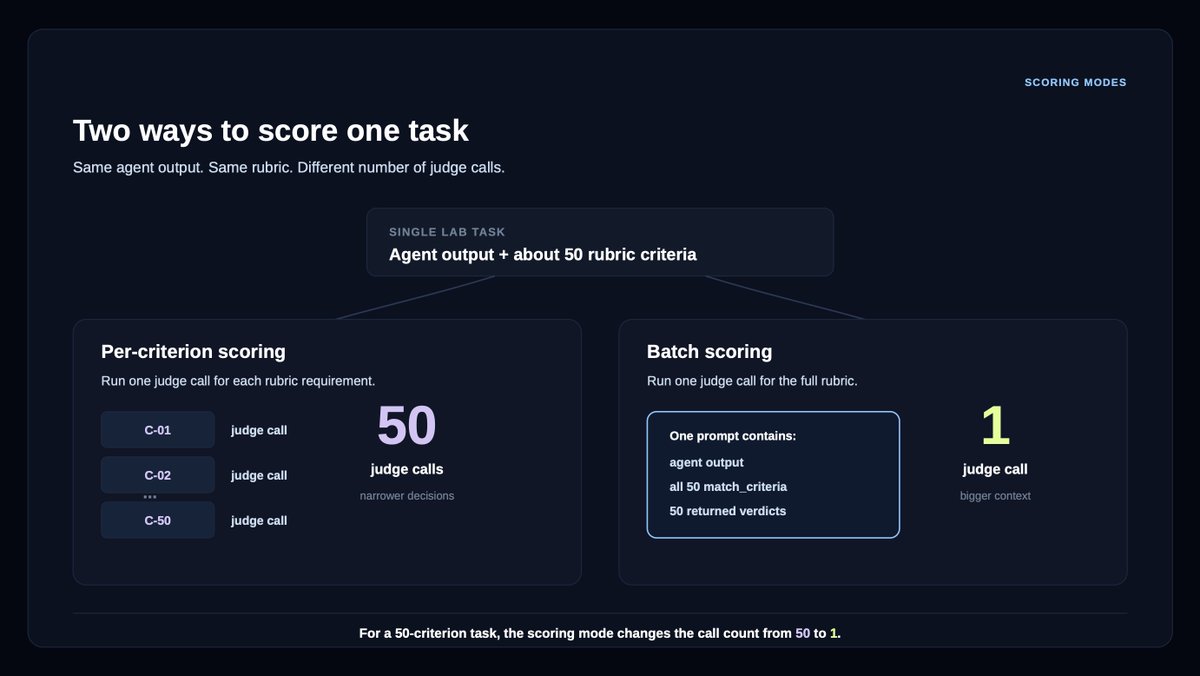
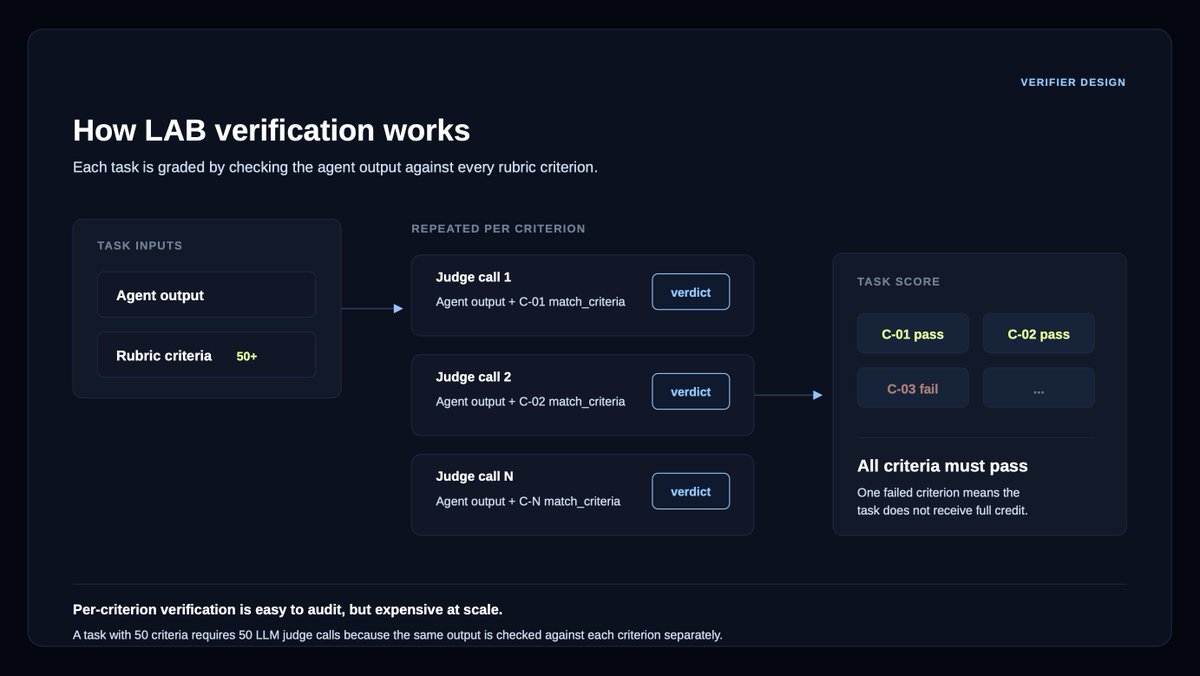
Verifiers are LLM judges that check an agent’s work against rubric criteria: they're used both in agent benchmarking and as reward signal in post-training.
But verifiers can be a bottleneck at scale.
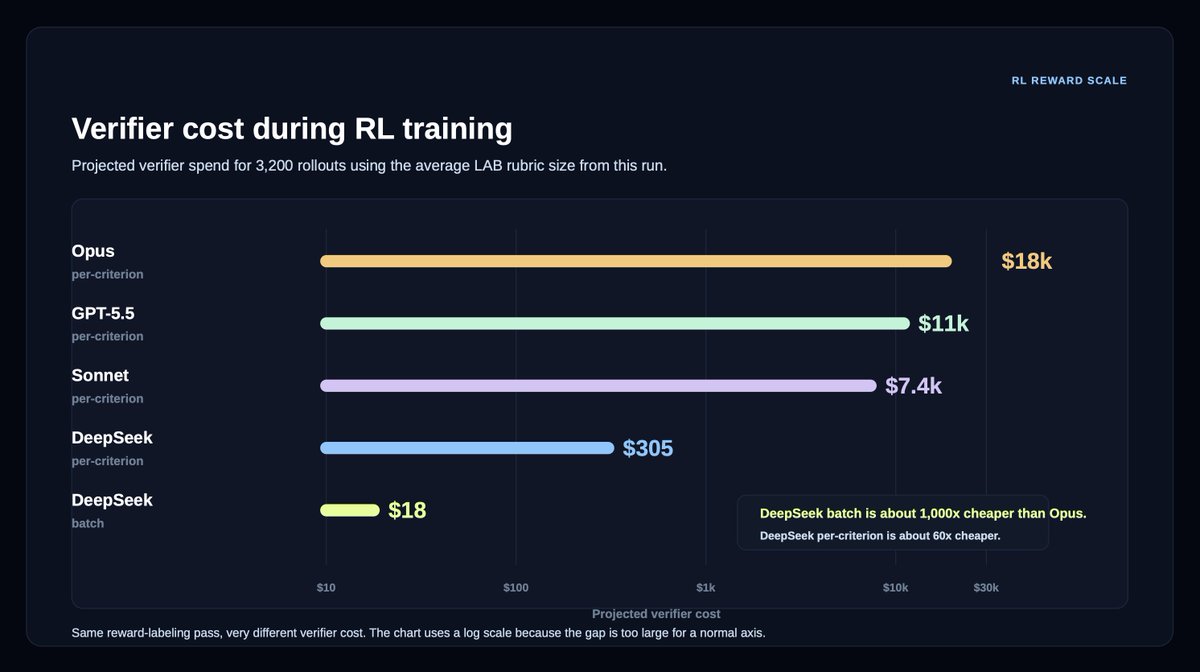
For example, our Legal Agent Benchmark (LAB), comprising 1,200+ legal tasks across 24 different practice areas, requires grading an average of 50+ rubric criteria per answer.
We partnered with @LangChain Labs to design more efficient verifiers for LAB, comparing batch vs per-criterion scoring and open/cost-efficient models against Opus 4.7.
The results were surprising:
DeepSeek v4 Flash preserved much of the Opus 4.7 verifier signal with 94-96% agreement, between batch mode and per-criterion mode.
This came with a massive reduction in cost: 18x cheaper on per-criterion verification, and ~1,000x cheaper on batch verification.
In an RL setting with 3,200 rollouts, the cost of verification drops from $18,000 to $18.
Today, we're opening our Singapore office and announcing our first law school partnership in Southeast Asia, with the National University of Singapore Faculty of Law.
Managed agent platforms are now emerging from frontier labs and cloud providers.
So why build our own cloud agent platform at Harvey?
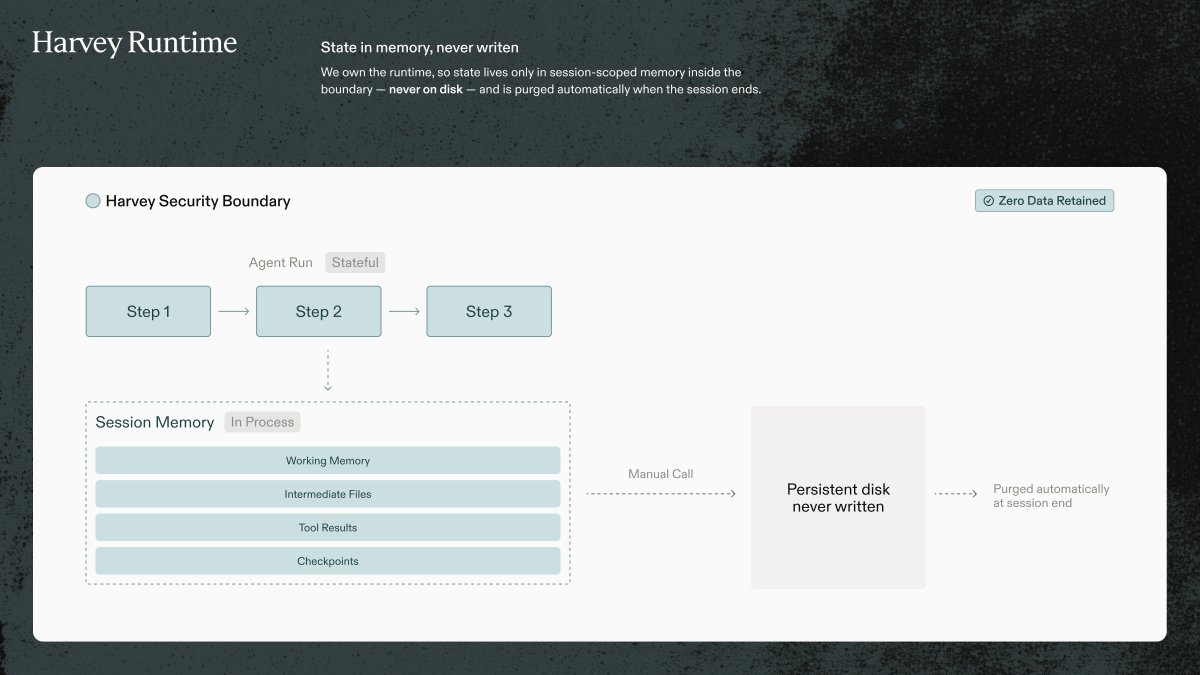
Because legal agents have three hard requirements: model flexibility, zero data retention, and cost control.
1) Model flexibility.
Lawyers can’t be locked into a single model provider. Client conflicts and confidentiality requirements can make a single model off-limits for a matter.
Instead, Harvey routes to the best model for a task. Our recent Legal Agent Benchmark (LAB) shows that different frontier models excel in different legal practice areas. The optimal choice is a mix of models across different types of legal work.
2) Zero data retention.
Lawyers work with client data that is often privileged, confidential, and subject to strict contractual controls.
Zero data retention means that data is never written to persistent storage by the model provider or agent runtime. The major managed agent platforms do not offer ZDR, so we had to build our own.
3) Cost control.
Legal agents run over large corpora and can involve many rounds of retrieval, reasoning, and tool use in a single workflow. If every step goes to the largest frontier model, cost runs out of control.
Owning the runtime lets Harvey match model capability to task complexity, routing to open-source models when it makes sense.
Empirically, we see 3-5x cost reductions versus a frontier-only approach.
More from our cofounder @gabepereyra:
We’re partnering with Tirant lo Blanch, the leading legal publisher for Spain, Portugal, and 20 Latin American countries.
Tirant’s database of legislation, case law, and more than 24,000 legal forms is now available in Harvey.
This is a great read on post-training and open models.
@harvey & @trajectorylabs post-trained Nemotron 3 Super on complex legal tasks with some very impressive initial results. All with auditable weights, real security, and clear provenance.
We're partnering with @trajectorylabs to bring sovereign continual learning to legal AI with NVIDIA Nemotron models.
Continual learning allows agents to improve over time from feedback on their work: every redline refines the next draft.
Open-weight models offer full auditability and data sovereignty over legal agents.
Using Trajectory's platform, we post-trained NVIDIA Nemotron 3 Super on our Legal Agent Benchmark (LAB), measuring performance on 1,200+ complex end-to-end legal tasks across 24 practice areas.
Initial results show that a post-trained Nemotron 3 Super can match performance of closed-source frontier models.
This is just the start: we'll keep pushing the frontier with the more powerful Nemotron 3 Ultra when available.
Welcome to Day 2. Yesterday, we showed the broader work we're doing with the pioneers of continual learning.
Today we'd like to deep dive on one: how we post-trained an open model for legal work, in partnership with @Harvey.
We've built a platform where production data is the moat. Every correction, retry, and edit becomes signal you can post-train on, and the models are plug and play: customer's can drop in their model of choice, and improve from there.
Fields like legal and finance make those demands absolute, with hard security, sovereignty, and provenance requirements. That's why we post-trained @nvidia 's open-weight Nemotron 3 Super, on Harvey's LAB benchmark.
The results, in just hours: post-trained Nemotron 3 Super approaches the closed frontier, matches GPT 5.5, lifts rubric-pass criteria +25%, all while beating the performance-vs-cost frontier. That's the power of our platform.
And this is just a glimpse towards what the future of intelligence will look like: continual learning, where products get smarter every time they're used.
Thanks to @nikogrupen, @gabepereyra, @ItsJulioPereyra, and the whole Harvey team for their collaboration on this. Much more to come soon on continually learning legal agents
@AnthropicAI launched Claude Opus 4.8 today.
Legal Agent Benchmark is the newest knowledge work benchmark included in their public model card -- awesome to see frontier labs making legal intelligence first-class!
Check out the results below:
Now live in Harvey: Claude Opus 4.8.
Opus 4.8 scored 10.4% on our Legal Agent Benchmark (LAB), which measures end-to-end completion of complex legal tasks across 24 practice areas.
Opus 4.8 is the first frontier model to break 10% on our all-pass standard.
Harvey Mobile is now generally available on Android.
With Harvey Mobile, legal teams can securely access relevant context, capture new information in real time, and stay up to speed wherever work takes them.